




写在前面,笔者最近在学习tensorflow(附一个tensorflow中文官方链接https://www.tensorflow.org/tutorials/keras/basic_classification)。遇到了一些问题,下面内容为解决方法。仅适合如笔者一般的小白~~
问题:已有数据的导入
笔者根据文档中的提供的模块下载数据失败,于是选择其他方式下载了数据到指定的文件。

如图,仅为keras中提供的一个数据集下载方法,下载失败后,通过数据集的链接直接到官方下载fashion_mnist数据,保存在文件‘fashion-mnist’中,此时数据集下载后有4个gz文件(如图):
解决:上述数据的导入与keras.datasets.fashion_mnist.load_data()结果相同
代码如下:
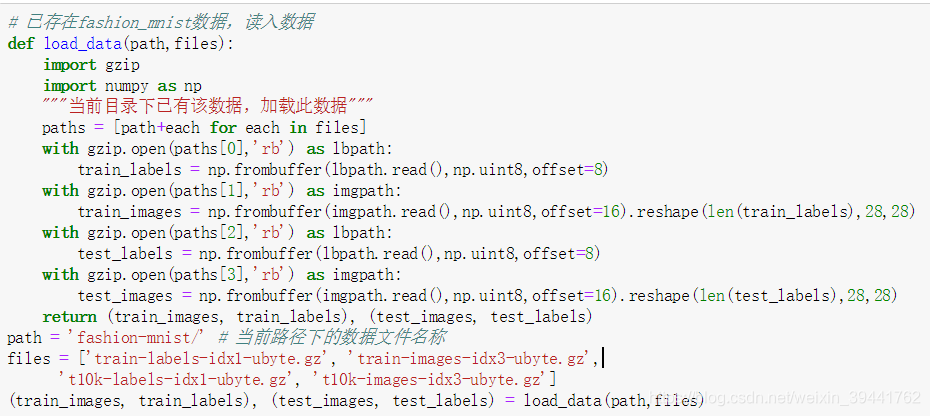
上述代码即可实现下载数据集的导入。测试train_images,train_labels,test_images,test_labels的shape:
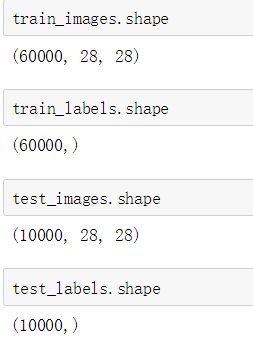 与通过keras.datasets.fashion_mnist.load_data()结果相同
与通过keras.datasets.fashion_mnist.load_data()结果相同
load_data(path,files)修改path和fies同样适用于‘MNIST_data’,如图:

思路来源:keras.datasets.fashion_mnist.load_data()导入模块中的fashion_mnist.py的代码修改
常用数据集Datasets-Keras数据集说明链接https://keras.io/zh/datasets/
以fashion_mnist数据集为例:上述链接中提及path:如果在本地索引文件(at '~/.keras/datasets/' + path), 它将被下载到该目录。因此找到自己安装的keras/datasets文件下:
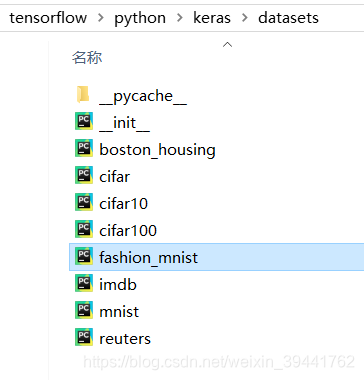
打开fashion_mnist.py文件,此文件下提到了下载数据和返回数据集的格式,删除其中下载部分,将路径部分修改为笔者的数据集路径,其他部分保持不变,即可得到导入已有数据的demo。

















 1927
1927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









