






 本文详细介绍了Linux的安全模型,包括认证、授权和审计,以及用户和组的管理。讨论了文件权限、ACL访问控制列表以及正则表达式的使用。此外,还涵盖了文本处理工具如grep、sed、awk和vim的使用,以及shell脚本中的变量管理和循环控制。
本文详细介绍了Linux的安全模型,包括认证、授权和审计,以及用户和组的管理。讨论了文件权限、ACL访问控制列表以及正则表达式的使用。此外,还涵盖了文本处理工具如grep、sed、awk和vim的使用,以及shell脚本中的变量管理和循环控制。
1. 总结linux安全模型
资源分派:
authentication: 认证,验证用户身份
authorization:授权,不同的用户设置不同权限
accounting | audition: 审计
当用户登陆成功时,系统会自动分配令牌token,包括:用户表示和组成员信息
用户:
Linux中每个用户是通过user id (UID) 来唯一标识
管理员的:root, 默认UID为0
普通用户:UID为1-60000自动分配
系统用户(给系统服务使用,比方说计算机里的一些程序):1-499 (Centos 6以前), 1-999 (CentOS 7以后)
对守护进程获取资源进行权限分配
登录用户: 500+ (Centos 6以前),1000+ (CentOS7以后)
给用户进行交互式登录使用
用户组:(账号的集合)
Linux中可以将一个或多个用户加入用户组中,用户组是通过Group ID (GID) 来唯一标识。
管理员组: root, 默认GID为0
普通组:
系统组:1-499 (CentOS 6以前), 1-999(CentOS7以后),对守护进程获取资源进行权限分配
普通组:500+(CentOS 6以前), 1000+(CentOS7以后),给用户使用
用户和组的关系:
用户的主要组(primary group): 用户必须属于一个且只有一个主组,默认创建用户时会自动创建和用户名同名的组,作为用户的主要组,由于此组中只有一个用户,又称为私有组。
用户的附加组(supplementary group):一个用户可以属于零个或多个辅助组,附属组、。
举例:

uid:用户
gid:组(主组)
groups:附属组
在linux当中,我们可能会访问很多服务,这些服务表现为程序,程序运行经常需要访问磁盘上的文件,访问文件的时候,这个文件能不能能够给他访问和权限分配有很大的关系。
Linux安全上下文Context:运行中的程序,即进程(Process),以进程发起者的身份运行,进程所能够访问资源的权限取决于进程的运行者身份。
范例:
以普通用户aurora和管理员root去运行 /etc/shadow,得到的结果是不同的,资源能否被访问,取决于运行者的身份,而非程序本身。
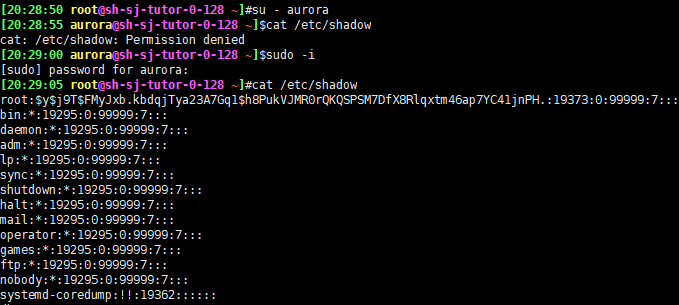
(作业笔记:vipw和vigr, pwck和grpck的概念:)
The vipw and vigr commands edit the files /etc/passwd and /etc/group
The pwck command checks the integrity of /etc/passwd and /etc/shadow, and grpck checks /etc/group and /etc/gshadow. They look for correct format, valid data, valid names, and valid GIDs (see the man pages for a complete list). When you run these with no options, they report both warnings and errors
2. 总结学过的权限,属性及ACL相关命令及选项,示例。
Linux系统中不仅是对用户与组根据UID,GID进行了管理,还对Linux系统中的文件,按照用户与组进行分类,针对不同的群体进行了权限管理,用他来确定谁能通过何种方式对文件和目录进行访问和操作。
一、文件权限
文件的权限针对三类对象进行定义
owner 属主,缩写u
group 属组,缩写g
other 其他,缩写o
每个文件针对每类访问者定义了三种主要权限
r:Read 读
w:Write 写
x:execute 执行
另 X:针对目录加执行权限,文件不加执行权限(因文件具备执行权限有安全隐患)
注意:root账户不受文件权限的读写限制,执行权限受限制
对于文件和目录来说,r,w,x有着不同的作用和含义:
针对文件:
r:读取文件内容
w:修改文件内容
x:执行权限对除二进制程序以外的文件没什么意义
针对目录:目录本质可看做是存放文件列表、节点号等内容的文件
r:查看目录下的文件列表
w:删除和创建目录下的文件
x:可以cd进入目录,能查看目录中文件的详细属性,能访问目录下文件内容(基础权限)

用户获取文件权限的顺序: 先看是否为所有者,如果是,则后面权限不看;再看是否为所属组,如果是,则后面权限不看。
二、修改文件访问权限的方法
chmod 修改权限 change mode
方法1:mode法
格式:chmod who opt per file
who:u g o a(all)
opt:+ – =
per:r w x X
方法2:数字法
格式:chmod XXX file
rwx rw- r–
111 110 100
7 6 4
r:4
w:2
x:1
例:chmod 764 file 给file文件添加 rwxrw-r– 权限
chmod -R +X dir 给dir目录添加X执行权限,dir目录下文件不添加执行权限
(如果dir目录下有文件已具备执行权限,则添加该文件执行权限)
三、UMASK值
作用:取消对应的权限,影响创建文件和目录的默认权限
对目录:umask+default=777(dir)
对文件:666-umask:观察结果,如果有奇数,奇数位+1,偶数不变
四、三种特殊权限suid、sgid、sticky(sticky权限工作环境中相对常用)
suid
作用:给一个用户继承二进制程序所有者拥有的权限
suid权限位 位于所有者的执行权限位上,如果一个文件具有suid权限,则所有者执行位为s,文件表现为红色背景
例:ll /usr/bin/passwd
-rwsr-xr-x. 1 root root 27832 Jun 10 2014 /usr/bin/passwd
给file文件增加suid权限
chmod u+s file
chmod 4755 file suid数字法表示为4
注: suid只适合作用在二进制程序上
sgid
作用1:给一个用户继承二进制程序所有组拥有的权限
sgid权限位 位于所有组的执行权限位,如果一个文件具有suid权限,则所有组的执行位为s,文件表现为黄色背景
例:ll `which cat`
-rwxr-sr-x. 1 root root 48568 Mar 23 2017 /bin/cat
给file文件增加sgid权限
chmod g+s file
chmod 2755 file sgid数字法表示为2
作用2:作用在目录上时,使一个目录下的新建的文件继承目录的所属组
sticky
作用:作用于目录上,此目录的文件只能被所有者删除
sticky权限位 位于其他的执行权限位上,如果一个文件具有sticky权限,则其他的执行位为t,目录表现为绿色背景
如:ll -d /tmp
drwxrwxrwt. 17 root root 4096 Apr 4 10:02 /tmp
给dir目录添加sticky权限
chmod o+t dir
chmod 1777 dir sticky数字法表示为1
五、ACL访问控制列表
作用:实现更加灵活的权限管理,打破了三类用户的权限管理
添加ACL权限
setfacl -m u:wang:0 file 使wang账户对指定file文件无权限
setfacl -m u:mage:rw file 使mage账户对指定file文件有读写权限
setfacl -m g:g1:rw file 使g1组对指定file文件有读写权限
getfacl file 查看指定file文件的ACL权限
ACL权限执行顺序类似于用户获取文件权限的顺序,getfacl顺序从上到下执行,一旦生效,下面的将不再生效(如果属于多个组,权限累加)
删除ACL权限
setfacl -x u:wang file 删除wang账户对指定file文件的ACL权限
setfacl -x g:g1 file 删除g1组对指定file文件的ACL权限
ACL权限下的mask
设置用户对指定文件所能拥有的最大权限(限高作用)
setfacl -m mask::r file 使指定文件file所拥有的最大权限位读r
setfacl -x mask::r file 取消指定文件file的最大权限限制mask
setfacl -b f1 取消f1文件所有的ACL权限
ACL生效顺序:所有者、自定义用户、自定义组、其他人
备份和恢复ACL权限
getfacl -R /tmp/dir1>acl.txt 将dir1目录下ACL权限备份
setfacl -R –set-file=acl.txt /tem/dir 恢复dir1目录下ACL权限
六、文件权限操作的常用命令
chown 设置文件所有者(普通用户无法修改文件所有者)
chgrp 设置文件所属组(普通用户要想该所属组,前提是文件所有者为自己,自己在所属组中)
chmod 设置指定文件权限
-R 递归
–reference=f1 f2 f3 参考f1文件权限设置f2,f3文件
chattr 给指定文件添加保护,避免root账户误操作
+i 锁定文件,不能删除,不能改名,不能更改内容
-i 解锁+i
-a 锁定文件,不能删除,不能改名,但可追加内容(追加重定向)
-a 解锁+a
+A 指定文件读时间atime不再更改
lsattr 查看指定文件是否有锁定状态
setfacl 设置文件ACL权限
-m mask::r file 使指定文件file所拥有的最大权限位读r
-x mask::r file 取消指定文件file的最大权限限制mask
-b f1 取消f1文件所有的ACL权限
-R –set-file=acl.txt /tem/dir 恢复dir1目录下ACL权限
getfacl 查看文件ACL权限
3. 结合vim几种模式,学会使用vim几个常见操作。
如何打开文件。并在打开文件(命令模式)之后如何退出文件。
+# 打开文件后,让光标处于第#行的行首,+默认行尾
+/Pattern 让光标处与第一个被pattern匹配到的行行首
-b file 二进制方式打开文件
-d file file2... 比较多个文件,相当于vimdiff
-m file 只读打开文件
-e file 直接进入ex模式,相当于执行 file
:wq 保存文件退出命令模式
:q!不保存文件退出命令模式
说明:如果该文件存在,文件被打开并显示内容;如果不存在,编辑后第一次存盘时创建它
打开文件(命令模式)之后,进入插入模式。并在插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。
i insert,在光标所在处输入
I 在当前光标所在行的行首输入
a append,在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下方打开一个新行
O 在当前光标所在行的上方打开一个新行
插入模式>ESC>命令模式
命令模式>:>扩展命令模式
扩展命令模式>ESC,enter>命令模式
打开文件(命令模式)之后,进入插入模式,编写一段话,"马哥出品,必属精品", 之后从插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。

使用cat命令验证文件内容,是刚刚自己写的内容。
(可选),命令模式下,光标在单词,句子上进行前后,上下跳转。行复制粘贴。行删除。
光标的位置按“yy”,复制当前行;
然后再光标的行按“p”,粘贴到下一行,原来的往下顺移。
删除当前行-------dd
复制多行----------nyy(比如3yy,复制3行)
删除多行----------ndd
复制多遍----------np
h:左
L:右
J:下
K:上
4. 总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
cat:查看文本内容
-E:显示行结束符
-A:显示所有控制符
-n:对显示出的每一行进行编号 = nl
-s:压缩连续的空行成一行
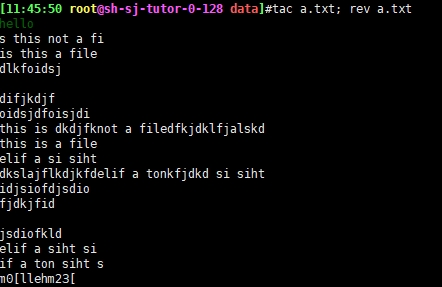
tac: 逆向显示文本内容
rev:将同一行的内容逆向显示
tac与rev的区别:
hexdump:查看非文本文件内容

less:分页查看文件或者STDIN输出 ,less命令是man命令使用的分页器
[14:11:28 root@sh-sj-tutor-0-128 /]#tree -d /etc |less /etc bin
head: 可以显示文件或标准输入的前面行
-c # 指定获取#字节
-n # 指定获取前#行,如果#为负数,表示从文件头取到倒数第#前
-# 同上


tail: 查看文件或标准输入的倒数行,和head相反
tail -f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow-descriptor,当文件删除再新建同名文件,将无法继续跟踪文件。
范例:只查看最新发生的日志:
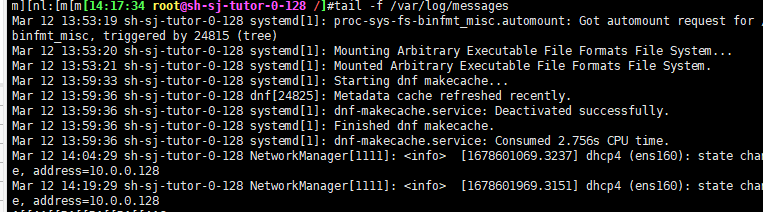
取IP行:

文本查找工具:find
实时查找工具,通过遍历指定路径完成文件查找。
find 文件查找
1 查找txt和pdf文件
find .(-name "*.txt"-o -name "*.pdf")-print
2 正则方式查找.txt和pdf
find .-regex ".*(.txt|.pdf)$"
-iregex:忽略大小写的正则
3 否定参数
查找所有非txt文本
find .!-name "*.txt"-print
4 指定搜索深度
打印出当前目录的文件(深度为1)
find .-maxdepth 1-type f
5 定制搜索
按类型搜索:
find .-type d -print //只列出所有目录-type f 文件 / l 符号链接
按时间搜索:
-atime 访问时间(单位是天,分钟单位则是-amin,以下类似) -mtime 修改时间 (内容被修改) -ctime 变化时间 (元数据或权限变化)
最近7天被访问过的所有文件:
find .-atime 7-type f -print
按大小搜索:
w字 k M G
寻找大于2k的文件
find .-type f -size +2k
按权限查找:
find .-type f -perm 644-print //找具有可执行权限的所有文件
按用户查找:
find .-type f -user weber -print// 找用户weber所拥有的文件
6 找到后的后续动作
删除:
删除当前目录下所有的swp文件:
find .-type f -name "*.swp"-delete
执行动作(强大的exec)
find .-type f -user root -exec chown weber {};//将当前目录下的所有权变更为weber
注:{}是一个特殊的字符串,对于每一个匹配的文件,{}会被替换成相应的文件名;
eg:将找到的文件全都copy到另一个目录:
find .-type f -mtime +10-name "*.txt"-exec cp {}OLD;
7 结合多个命令
tips: 如果需要后续执行多个命令,可以将多个命令写成一个脚本。然后 -exec 调用时执行脚本即可;
-exec ./commands.sh {};
-print的定界符
默认使用' '作为文件的定界符;
-print0 使用''作为文件的定界符,这样就可以搜索包含空格的文件;
02 grep 文本搜索
grep match_patten file // 默认访问匹配行常用参数:
-o 只输出匹配的文本行 VS -v 只输出没有匹配的文本行
-c 统计文件中包含文本的次数
grep -c "text" filename-n 打印匹配的行号
-i 搜索时忽略大小写
-l 只打印文件名
1 在多级目录中对文本递归搜索(程序员搜代码的最爱):
grep "class".-R-n2 匹配多个模式
grep -e "class"-e "vitural" file3 grep输出以作为结尾符的文件名:(-z)
grep "test" file*-lZ| xargs -0 rm4 xargs 命令行参数转换
xargs 能够将输入数据转化为特定命令的命令行参数;这样,可以配合很多命令来组合使用。比如grep,比如find;
将多行输出转化为单行输出
cat file.txt| xargs是多行文本间的定界符
将单行转化为多行输出
cat single.txt | xargs -n 3-n:指定每行显示的字段数
xargs参数说明
-d 定义定界符 (默认为空格 多行的定界符为 )
-n 指定输出为多行
-I {} 指定替换字符串,这个字符串在xargs扩展时会被替换掉,用于待执行的命令需要多个参数时
eg:
cat file.txt | xargs -I{}./command.sh -p {}-1-0:指定为输入定界符
eg:统计程序行数
find source_dir/-type f -name "*.cpp"-print0 |xargs -0 wc -lprintf:实现格式化输出
5. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
1、grep命令
功能:输入文件的每一行中查找字符串。
基本用法:
grep [-acinv] [--color=auto] [-A n] [-B n] '搜寻字符串' 文件名参数说明:-a:将二进制文档以文本方式处理-c:显示匹配次数-i:忽略大小写差异-n:在行首显示行号-A:After的意思,显示匹配字符串后n行的数据-B:before的意思,显示匹配字符串前n行的数据-v:显示没有匹配行-A:After的意思,显示匹配部分之后n行-B:before的意思,显示匹配部分之前n行--color:以特定颜色高亮显示匹配关键字–color选项是个非常好的选项,可以让你清楚的明白匹配了那些字符。最好在自己的.bashrc或者.bash_profile文件中加入:
alias grep=grep --color=auto
每次grep搜索之后,自动高亮匹配效果了。‘搜寻字符串’是正则表达式,注意为了避免shell的元字符对正则表达式的影响,请用单引号(’’)括起来,千万不要用双引号括起来(””)或者不括起来。
2、grep 与正则表达式
正则表达式分为基本正则表达式和扩展正则表达式。下面分别简单总结一下。
元数据 | 意义和范例 |
^word | 搜寻以word开头的行。 例如:搜寻以#开头的脚本注释行 grep –n ‘^#’ regular.txt |
word$ | 搜寻以word结束的行 |
. | 匹配任意一个字符。 例如:grep –n ‘e.e’ regular.txt 匹配e和e之间有任意一个字符,可以匹配eee,eae,eve,但是不匹配ee。 |
\ | 转义字符。 例如:搜寻’,’是一个特殊字符,在正则表达式中有特殊含义。必须要先转义。grep –n ‘\,” regular.txt |
* | 前面的字符重复0到多次。 例如匹配gle,gogle,google,gooogle等等 grep –n ‘go*gle’ regular.txt |
[list] | 匹配一系列字符中的一个。 例如:匹配gl,gf。grep –n ‘g[lf]’ regular.txt |
[n1-n2] | 匹配一个字符范围中的一个字符。 例如:匹配数字字符 grep –n ‘[0-9]’ regular.txt |
[^list] | 匹配字符集以外的字符 例如:grep –n ‘[^o]‘ regular.txt 匹配非o字符 |
\<word | 单词是的开头。 例如:匹配以g开头的单词 grep –n ‘\<g’ regular.txt |
word\> | 前面的字符重复n1,n2次 例如:匹配google,gooogle。grep –n ‘go\{2,3\}gle’ regular.txt |
\<word | 匹配单词结尾 例如:匹配以tion结尾的单词 grep –n ‘tion\>’ regular.txt |
word\{n1\} | 前面的字符重复n1 例如:匹配google。 grep –n ‘go\{2\}gle’ regular.txt |
word\{n1,\} | 前面的字符至少重复n1 例如:匹配google,gooogle。 grep –n ‘go\{2\}gle’ regular.txt |
word\{n1,n2\} | 前面的字符重复n1,n2次 例如:匹配google,gooogle。 grep –n ‘go\{2,3\}gle’ regular.txt |
扩展正则表达式
? #匹配0个或1个在其之前的那个普通字符。 例如,匹配gd,god grep –nE ‘go?d’ regular.txt+ #匹配1个或多个在其之前的那个普通字符,重复前面字符1到多次。 例如:匹配god,good,goood等等字符串。 grep –nE go+d’ regular.txt() #表示一个字符集合或用在expr中,匹配整个括号内的字符串, 原来都是匹配单个字符。 例如:搜寻good或者glad grep –nE ‘g(oo|la)’ regular.txt| #表示“或”,匹配一组可选的字符,或(or)的方式匹配多个字串。 例如:grep –nE ‘god|good’ regular.txt 匹配god或者good。常用的集合表示方法有:
纯数字:[[:digit:]]或[0-9]小写字母:[[:lower:]]或[a-z]大写字母:[[:upper:]]或[A-Z]大小写字母:[[:alpha:]]或[a-zA-Z]数字加字母:[[:alnum:]]或[0-9a-zA-Z]空白字符:[[:space:]]标点符号:[[:punct:]]3、关于匹配的实例
grep -c "48" test.txt #统计所有以“48”字符的行有多少grep -i "May" test.txt #不区分大小写查找“May”所有的行)grep -n "48" test.txt #显示行号;显示匹配字符“48”的行及行号,相同于 nl test.txt |grep 48)grep -v "48" test.txt #显示输出没有字符“48”所有的行)grep "471" test.txt #显示输出字符“471”所在的行)grep "48;" test.txt #显示输出以字符“48”开头,并在字符“48”后是一个tab键所在的行grep "48[34]" test.txt #显示输出以字符“48”开头,第三个字符是“3”或是“4”的所有的行)grep "^[^48]" test.txt #显示输出行首不是字符“48”的行)grep "[Mm]ay" test.txt #设置大小写查找:显示输出第一个字符以“M”或“m”开头,以字符“ay”结束的行)grep "K…D" test.txt #显示输出第一个字符是“K”,第二、三、四是任意字符,第五个字符是“D”所在的行)grep "[A-Z][9]D" test.txt #显示输出第一个字符的范围是“A-D”,第二个字符是“9”,第三个字符的是“D”的所有的行grep "[35]..1998" test.txt #显示第一个字符是3或5,第二三个字符是任意,以1998结尾的所有行grep "4/{2,/}" test.txt #模式出现几率查找:显示输出字符“4”至少重复出现两次的所有行grep "9/{3,/}" test.txt #模式出现几率查找:显示输出字符“9”至少重复出现三次的所有行grep "9/{2,3/}" test.txt #模式出现几率查找:显示输出字符“9”重复出现的次数在一定范围内,重复出现2次或3次所有行grep -n "^$" test.txt #显示输出空行的行号ls -l |grep "^d"#如果要查询目录列表中的目录 同:ls -d *ls -l |grep "^d[d]"#在一个目录中查询不包含目录的所有文件ls -l |grpe "^d…..x..x"#查询其他用户和用户组成员有可执行权限的目录集合4、grep实例
(1).显示/proc/meminfo文件中以大写或小写s开头的行;
# grep -i '^[Ss]'/proc/meminfo(2).显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
# grep -v '/sbin/nologin$'/etc/passwd | cut -d: -f1(3).显示/etc/passwd文件中其默认shell为/bin/bash的用户
进一步:仅显示上述结果中其ID号最大的用户
# grep '/bin/bash$'/etc/passwd | cut -d: -f1 | sort -n -r | head -1(4).找出/etc/passwd文件中的一位数或两位数;
# grep '\<[[:digit:]]\{1,2\}\>'/etc/passwd(5).显示/boot/grub/grub.conf中至少一个空白字符开头的行
# grep '^[[:space:]]\+.*'/boot/grub/grub.conf(6).显示/etc/rc.d/rc.sysinit文件中,以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
# grep '^#[[:space:]]\+[^[:space:]]\+'/etc/rc.d/rc.sysinit(7).找出netstat -tan命令执行结果中包含’LISTEN’的行;
# netstat -tan | grep 'LISTEN[[:space:]]*$(8).添加用户bash,testbash,basher,nologin(SHELL为/sbin/nologin),而找出当前系统上其用户名和默认SHELL相同的用户;
# grep '\(\<[[:alnum:]]\+\>\).*\1$'/etc/passwd(9).扩展题:新建一个文本文件,假设有如下内容:
He like his lover.
He love his lover.
He like his liker.
He love his liker.
找出其中最后一个单词是由此前某单词加r构成的行;
# grep '\(\<[[:alpha:]]\+\>\).*\1r' grep.txt(10).显示当前系统上root、centos或user1用户的默认shell及用户名;
# grep -E '^(root|centos|user1\>)'/etc/passwd(11).找出/etc/rc.d/init.d/functions文件中某单词后面跟一对小括号’()”的行;
# grep -o '\<[[:alpha:]]\+\>()'/etc/rc.d/init.d/functions(12).使用echo输出一个路径,而使用egrep取出其基名;
# echo /etc/rc.d/ | grep -o '[^/]\+/\?$' | grep -o '[^/]\+'
6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
1 变量的分类
在Linux中,变量分为环境变量 和 局部变量。 环境变量能被子进程继承,而局部变量只能在当前进程中使用。 并且,不论是环境变量还是局部变量,他们又都可以分为系统变量 和 自定义变量。系统变量是系统启动时自动创建的变量,往往为系统运行提供支持;而自定义变量是用户自己定义的。一般而言,系统变量全为大写,自定义变量全为小写。
1.1 常见的环境变量
系统提供了一些默认的环境变量,如下:
HOME:用户主目录 当我们使用cd 或cd ~时就会调用这个环境变量找到用户主目录。
SHELL:当前使用的SHELL
HISTSIZE:历史命令的最大条数
MAIL:当前用户的邮箱目录
PATH:可执行文件的查找路径。 这是一个非常重要的环境变量,当我们直接写一个命令时,系统就会在PATH路径中寻找这个命令,这样我们在执行命令的时候就不用输命令完整的路径了。多个路径之间用:分隔。
LANG:当前系统的语言
RANDOM:随机数生成器的路径。 该路径默认指向/dev/random这个文件,这个文件是一个随机数生成器,当我们使用$RANDOM时就能获得一个0-32767之间的随机整数。
1.2 常见的局部变量(非环境变量)
PS1:命令提示符 在命令输入光标前有一串用中括号括起来的信息,这就是命令提示符。命令提示符究竟需要显示哪些信息,这就是由PS1这个局部变量决定的。由于它是局部变量,因此子进程中无法继承这个变量,子进程拥有自己的PS1。 我们可以修改这个变量,使得它显示我们需要的信息,如:我们让命令提示符显示当前用户名和当前完整的路径:
[root@iZ28st035lsZ ~]# PS1='[\u:\w]:'[root:~]:$:当前shell的PID 可以通过如下命令查看当前shell的PID:
echo $$?:上个命令的执行结果 上个命令若执行成功,则echo $?就会返回0;若上个命令执行失败,则该值为一个非0整数。
1.3 环境变量与局部变量的区别
环境变量相当于全局变量,它可以被子进程继承;而局部变量只能在当前shell中使用。那么,什么是子进程呢?
1.4 什么是子进程?
在一个bash中开启一个新的bash,那么原本的bash称为父进程,新的bash称为子进程。 子进程会继承父进程的所有环境变量,而父进程的局部变量只能在父进程中使用。
2 变量的显示与设置
2.1 变量的显示:echo
显示一个变量有两种方式,这两种方式等价:
方式一:
echo $变量名方式二:
echo ${变量名}2.2 变量的设置
变量的设置较为简单,如下所示:
变量名=变量值但是,变量的设置具有较多的注意点!
2.2.1 设置变量的注意事项:
等号两侧都不能含有任何空格!若变量值必须有空格,则可以使用单引号 或 双引号将变量值包裹起来,如下所示:
myName='chai bo zhou'
或
myName="chai bo zhou"但是,单引号和双引号包裹变量值有本质的区别: 若变量值中包含特殊字符,则按照特殊字符代表的含义输出,如:
username="username is $myName"
echo $username则输出的结果为:username is chai bo zhou。 若改为单引号,则以一个字符串的形式输出:
username='username is $myName'
echo $username则输出结果为:username is $myName。
变量名绝对不能含有空格,即使用单/双引号的方式包裹也无济于事!
转移字符\可以将特殊字符转换成一般的字符,即这些特殊字符将失去它原有的特性,它退化成一个字符串了。特殊字符有:回车键、$、\、空格、!等。
若变量值中包含命令的话,可以使用反单引号或$(命令)包裹命令,这样命令就会原样执行,如:
currentPath="current path is : $(pwd)"
echo $currentPath
输出结果为:current path is :/root可以使用export将自定义变量升级成环境变量,供子进程使用。
一般系统变量全部大写,自定义变量用小写。
2.3 取消变量
unset 变量名3 环境变量
自定义变量相当于局部变量,只能在当前shell中使用;而环境变量相当于全局变量,可以在子shell中使用。
3.1 查看变量
3.1.1 查看环境变量:env
env是environment的缩写,代表的就是环境变量的意思。他会把系统中所有的环境变量都数出来,如下所示:
[root@iZ28st035lsZ ~]# env
TERM=xterm-256color
SHELL=/bin/bash
CATALINA_HOME=/usr/tomcat
SSH_CLIENT=218.94.83.1325562422SSH_TTY=/dev/pts/0USER=root
LS_COLORS=MAIL=/var/spool/mail/root
PATH=/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/tomcat/tomcat:/usr/web2/tomcat:/usr/tomcat:/usr/jdk/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin3.1.2 查看环境变量 与 自定义变量:set
set命令可以查看到所有的环境变量 和 自定义的变量。
3.1.3 查看环境变量:export
export和env都会输出所有的环境变量,但export还会输出环境变量的类型:
[root:~]:export
declare -x CATALINA_HOME="/usr/tomcat"
declare -x CATALINA_HOME2="/usr/web2/tomcat"
declare -x CATALINA_HOME3="/usr/local/tomcat/tomcat"
declare -x CLASSPATH=".:/usr/jdk/lib/dt.jar:/usr/jdk/lib/tools.jar"
declare -x CVS_RSH="ssh"3.2 设置环境变量
设置环境变量首先需要创建一个局部变量:
变量名=变量值然后再通过export命令将该局部变量提升为环境变量:
export 变量名4 从键盘读取变量:read
read [-p 提示语][-t 时间] 变量名
-p:后面加上提示语
-t:后加上秒数,表示等待用户输入的时间用户输入之后的值会存储到变量名中。
5 变量类型:declare/typeset
Linux中的变量一共有5种类型,分别是:字符、整型、只读、环境变量。
declare -/+参数 变量名=变量值
-a:将变量变成数组类型
-i:将变量变成int型
-x:将变量变成环境变量型
-r:将变量变成只读型
+:表示取消操作,即:将变量还原成字符型。6 变量内容的删除 与 替换
之前介绍的unset命令是将变量删除,而接下来介绍的命令是对变量内容的删除或替换。
操作方式 | 说明 |
${变量名#关键词} | 从变量值的头部开始,依次向后删除到关键词第一次出现的位置为止 |
${变量名##关键词} | 从变量值的头部开始,依次向后删除到关键词最后一次出现的位置为止 |
${变量名%关键词} | 从变量值的尾部开始,依次向前删除到关键词第一次出现的位置为止 |
${变量名%%关键词} | 从变量值的尾部开始,依次向前删除到关键词最后一次出现的位置为止 |
${变量名/旧字符串/新字符串} | 从变量值的头部开始,依次向后找到第一个旧字符串,并将其替换 |
${变量名//旧字符串/新字符串} | 将变量值中所有的旧字符串替换成新字符串 |
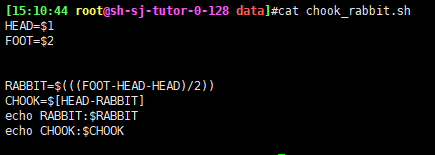
7. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?

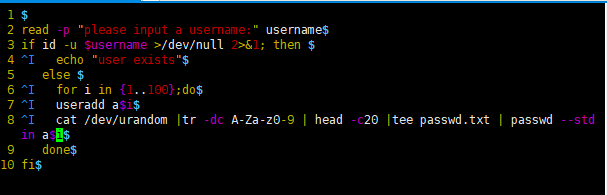
8. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
for遍历1..100
for ((i=1,sum=0;i<=100;i++));do let sum+=i;done;echo $sum
先id判断是否存在
3用户存在则说明存在,用户不存在则添加用户并说明已添加。
9. 磁盘存储术语总结: head, track, sector, sylinder.
磁盘结构
硬盘的物理结构一般由磁头与盘片、电动机、主控芯片与排线等部件组成;当主电动机带动盘片旋转时,副电动机带动一组(磁头)到相对应的盘片上并确定读取正面还是反面的碟面,磁头悬浮在碟面上画出一个与盘片同心的圆形轨道(磁轨或称柱面),这时由磁头的磁感线圈感应碟面上的磁性与使用硬盘厂商指定的读取时间或数据间隔定位扇区,从而得到该扇区的数据内容。
硬盘最基本的组成部分是由坚硬金属材料制成的涂以磁性介质的盘片,不同容量硬盘的盘片数不等。每个盘片有两面,都可记录信息。
术语
盘片(Platter)
一块硬盘有若干盘片,每个盘片有可以存储数据的上、下两盘面(Side)。这些盘面堆叠在主轴上高速旋转,它们从上至下从“0”开始依次编号。
读写磁头(Head)
每个盘面上一个读写磁头,盘面号即磁头号。所有磁头在磁头臂作用下同时内外移动,即任意时刻,所有磁头所处的磁道号是相同的。
每个盘片有两个面,每个面都有一个磁头,习惯用磁头号来区分。
磁道(Track)
每个盘面被划分成许多同心圆,这些同心圆轨迹叫做磁道;磁道从外向内从0开始顺序编号。
扇区(Sector)
将一个盘面划分为若干内角相同的扇形,这样盘面上的每个磁道就被分为若干段圆弧,每段圆弧叫做一个扇区。每个扇区中的数据作为一个单元同时读出或写入。硬盘的第一个扇区,叫做引导扇区。
在老式硬盘中,尽管磁道周长不同,但每个磁道上的扇区数是相等的,越往圆心扇区弧段越短,但其存储密度越高。不过这种方式显然比较浪费空间,因此现代硬盘则改为等密度结构,这意味着外围磁道上的扇区数量要大于内圈的磁道,寻址方式也改为以扇区为单位的线性寻址。为了兼容老式的 3D 寻址方式,现代硬盘控制器中都有一个地址翻译器将 3D 寻址参数翻译为线性参数。
为了对扇区进行查找和管理,需要对扇区进行编号,扇区的编号从0磁道开始,起始扇区为1扇区,其后为2扇区、3扇区……,0磁道的扇区编号结束后,1磁道的起始扇区累计编号,直到最后一个磁道的最后一个扇区(n扇区)。例如,某个硬盘有1024个磁道,每个磁道划分为63个扇区,则0磁道的扇区号为1~63,1磁道的起始扇区号为64最后一个磁道的最后一个扇区号为64512。硬盘在进行扇区编号时与软盘有一些区别,在软盘的一个磁道中,扇区号一次编排,即1、2、3……n扇区。由于硬盘的转速较高,磁头在完成某个扇区数据的读写后,必须将数据传输到微机,这需要一个时间,但是这时硬盘在继续高速旋转,当数据传输完成后,磁头读写第二个扇区时,磁盘已经旋转到了另外一个扇区。因此在早期硬盘中,扇区号是按照某个间隔系数跳跃编排的。
柱面(Cylinder)
所有盘面上的同一磁道构成一个圆柱,称作柱面。数据的读/写按柱面从外向内进行,而不是按盘面进行。定位时,首先确定柱面,再确定盘面,然后确定扇区。之后所有磁头一起定位到指定柱面,再旋转盘面使指定扇区位于磁头之下。写数据时,当前柱面的当前磁道写满后,开始在当前柱面的下一个磁道写入,只有当前柱面全部写满后,才将磁头移动到下一个柱面。在对硬盘分区时,各个分区也是以柱面为单位划分的,即从什么柱面到什么柱面;不存在一个柱面同属于多个分区。
磁道与柱面都是表示不同半径的圆,在许多场合, 磁道和柱面可以互换使用。
硬盘的CHS
即Cylinder(柱面)、Head(磁头)、Sector(扇区),只要知道了硬盘的CHS的数目,即可确定硬盘的容量:
硬盘的容量=柱面数(磁道数) * 磁头数 * 单磁道扇区数 * 单个容量扇区大小(一般初始为512字节)。
3D 寻址参数
×× 磁道(柱面),×× 磁头,×× 扇区
术语要点
(1)硬盘有数个盘片,每盘片两个面,每个面一个磁头
(2)盘片被划分为多个扇形区域即扇区
(3)同一盘片不同半径的同心圆为磁道
(4)不同盘片相同半径构成的圆柱面即柱面
(5)公式: 存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
(6)信息记录可表示为:××磁道(柱面),××磁头,××扇区
簇
“簇”是DOS进行分配的最小单位。当创建一个很小的文件时,如是一个字节,则它在磁盘上并不是只占一个字节的空间,而是占有整个一簇。DOS视不同的 存储介质(如软盘,硬盘),不同容量的硬盘,簇的大小也不一样。簇的大小可在称为磁盘参数块(BPB)中获取。簇的概念仅适用于数据区。
磁盘驱动器在向磁盘读取和写入数据时,要以扇区为单位。在磁盘上,DOS操作系统是以“簇”为单位为文件分配磁盘空间的。硬盘的簇通常为多个扇区,与磁盘的种类、DOS 版本及硬盘分区的大小有关。每个簇只能由一个文件占用,即使这个文件中有几个字节,决不允许两个以上的文件共用一个簇,否则会造成数据的混乱。这种以簇为最小分配单位的机制,使硬盘对数据的管理变得相对容易,但也造成了磁盘空间的浪费,尤其是小文件数目较多的情况下,一个上千兆的大硬盘,其浪费的磁盘空间可达上百兆字节。
10. 总结MBR,GPT结构。
MBR分区结构
MBR磁盘分区是一种使用最为广泛的分区结构,它也被称为DOS分区结构,但它并不仅仅应用于Windows系统平台,也应用于Linux,基于X86的UNIX等系统平台。它位于磁盘的0号扇区(一扇区等于512字节),是一个重要的扇区(简称MBR扇区)。
MBR扇区由以下四部分组成:
引导代码:引导代码占MBR分区的前440字节,负责整个系统启动。如果引导代码被破坏,系统将无法启动。
Windows磁盘签名:占引导代码后面的4字节,是Windows初始化磁盘写入的磁盘标签,如果此标签被破坏,则系统会提示“初始化磁盘”。
MBR分区表:占Windows磁盘标签后面的64个字节,是整个硬盘的分区表。
MBR结束标志:占MBR扇区最后2个字节,一直为“55 AA”。

下面详细分析分区表结构
磁盘在使用前都要进行分区,也就是将硬盘划分为一个个逻辑的区域。每一个分区都有一个确定的起始结束位置。MBR磁盘的分区形式一般有3种,既主分区,扩展分区和非DOS分区。主分区既主DOS分区,扩展分区既扩展的DOS分区(扩展分区可以分逻辑分区),非DOS分区对于主分区的操作系统来说是一块被划分出去的区域,只能非DOS分区中操作系统可以管理。
如下:是MBR分区表
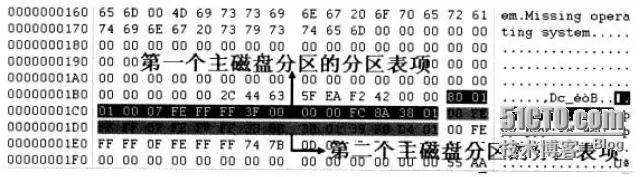
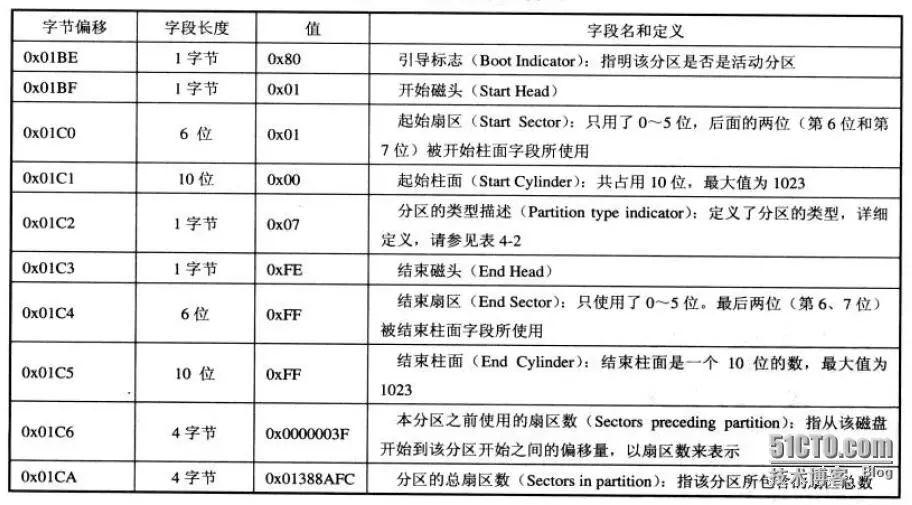
MBR一共占用64个字节,其中每16个字节为一个分区表项。也就是在MBR扇区中只能记录4个分区信息,可以是4个主分区,或者是3个主分区1个扩展分区。
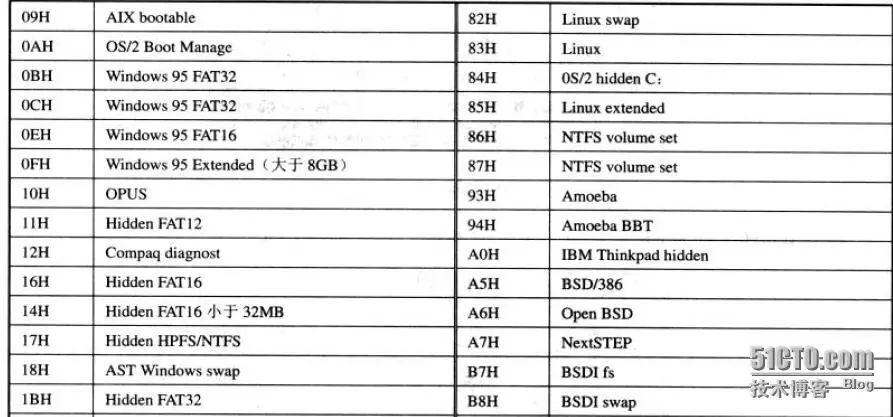
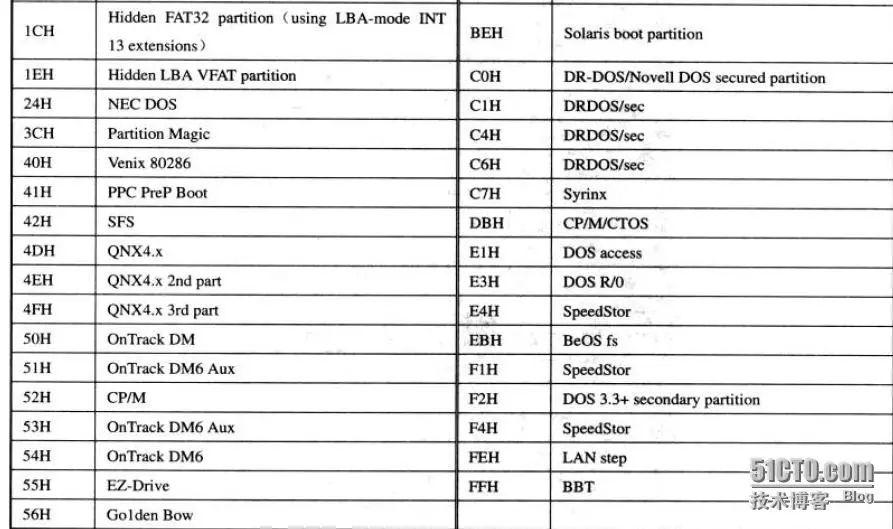
每个分区项中对应的字节解释如下表:
扩展分区的结构分析
由于MBR仅仅为分区表保留了64字节的存储空间,而每个分区则占用16字节的空间,也就是只能分4个分区,而4个分区在实际情况下往往是不够用的。因此就有了扩展分区,扩展分区中的每个逻辑分区的分区信息都存在一个类似MBR的扩展引导记录(简称EBR)中,扩展引导记录包括分区表和结束标志“55 AA”,没有引导代码部分。
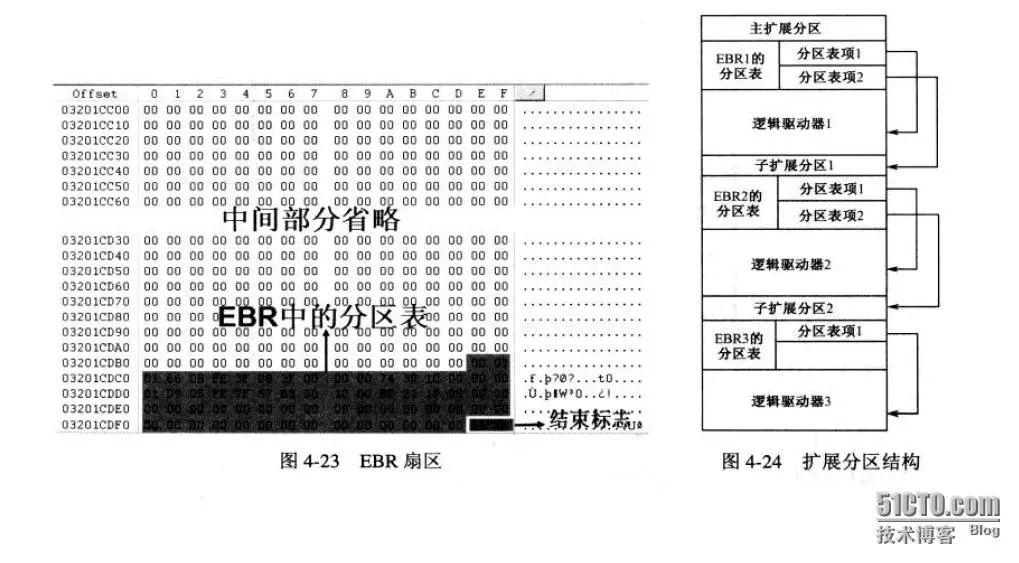
如上图:EBR中分区表的第一项描述第一个逻辑分区,第二项指向下一个逻辑分区的EBR。如果下一个逻辑分区不存在,第二项就不需要了。
MBR分区的结构大致就介绍到这了。如果硬盘的MBR被破坏,可以复制其他硬盘的MBR到故障盘,然后修复分区表,也可以初始化故障盘然后修复分区表。
GPT分区结构
GPT磁盘分区的基本特点
GPT磁盘分区结构解决了MBR只能分4个主分区的的缺点,理论上说,GPT磁盘分区结构对分区的数量好像是没有限制的。但某些操作系统可能会对此有限制。
GPT磁盘分区结构由6部分组成,如下图:
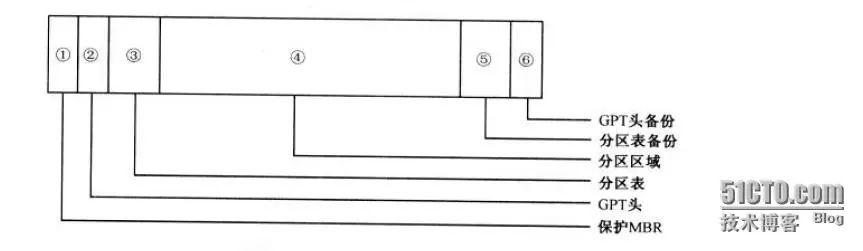
1、保护MBR
保护MBR位于GPT磁盘的第一扇区,也就是0号扇区,有磁盘签名,MBR磁盘分区表和结束标志组成,没有引导代码。而且分区表内只有一个分区表项,这个表项GPT根本不用,只是为了让系统认为这个磁盘是合法的。

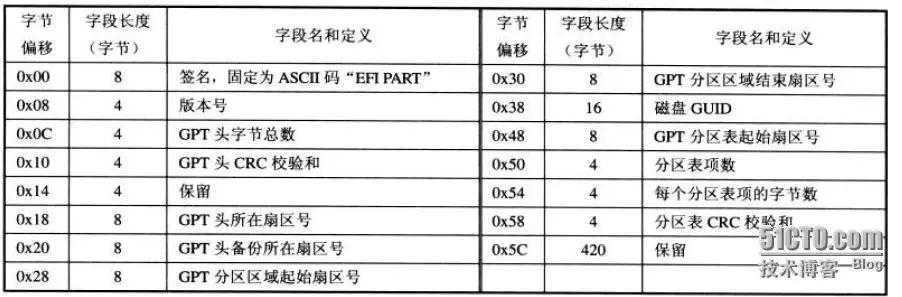
2、GPT头
GPT头位于GPT磁盘的第二个磁盘,也就是1号扇区,该扇区是在创建GPT磁盘时生成,GPT头会定义分区表的起始位置,分区表的结束位置、每个分区表项的大小、分区表项的个数及分区表的校验和等信息。

GPT头中参数的含义解释如下表:
3、分区表
分区表位于GPT磁盘的2-33号磁盘,一共占用32个扇区,能够容纳128个分区表项。每个分区表项大小为128字节。因为每个分区表项管理一共分区,所以Windows系统允许GPT磁盘创建128个分区。
每个分区表项中记录着分区的起始,结束地址,分区类型的GUID,分区的名字,分区属性和分区GUID。
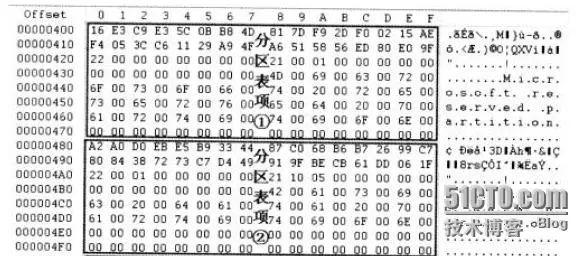
分区表项中各参数的含义解释如下表:

4、分区区域
GPT分区区域就是用户使用的分区,也是用户进行数据存储的区域。分区区域的起始地址和结束地址由GPT头定义。
5、GPT头备份
GPT头有一个备份,放在GPT磁盘的最后一个扇区,但这个GPT头备份并非完全GPT头备份,某些参数有些不一样。复制的时候根据实际情况更改一下即可。
6.分区表备份
分区区域结束后就是分区表备份,其地址在GPT头备份扇区中有描述。分区表备份是对分区表32个扇区的完整备份。如果分区表被破坏,系统会自动读取分区表备份,也能够保证正常识别分区。
GPT的分区结构相对于MBR要简单许多,并且分区表以及GPT头都有备份。
11. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例
fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
12. 总结raid 0, 1, 5, 10, 01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现。
RAID 0
原理:将数据条带化,最少需要两块硬盘(每块硬盘的容量一样,实际生产环境中建议使用同品牌同型号同批次同容量的硬盘组成 RAID 0),即将所有组成 RAID 0 的硬盘的可用容量组合在一起,形成计算机上的一个逻辑卷。通俗的讲就是至少使用两块硬盘来存储数据,但是我要存储的数据不是全部存在某一块硬盘上,而是把我要存储的数据分成均等的多部分,然后平均分散存储在组成 RAID 0 的磁盘阵列上。
下图是用四块硬盘组成 RAID 0 的示意图,其中每块硬盘都被分成 ABCD 四个条带,然后我要存数据就先存把数据均分成四部分,如果 A1 能存下其中一份,那就直接将四部分分别存入 A1-A4,如果存不下就先存满 A1-A4,剩下的按同样的方式存 B1-B4,以此类推。
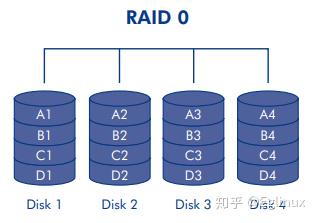
可用容量:组成 RAID 0 所有硬盘容量的总和
优点:
提高读写速度,对硬盘的总容量没有损失。
处理大文件很快。
缺点:
一旦阵列中某块硬盘损坏了,所有数据将不可恢复。
RAID 1
原理:镜像存储,RAID 1 至少需要两块硬盘组成,两块硬盘互为备份,存储的内容完全相同。建议硬盘容量大小也要一样,如果不一样,那实际可用容量不超过较小的那块硬盘的容量。
下图是 RAID 1 的示意图,左右两边存储的数据是完全相同的。
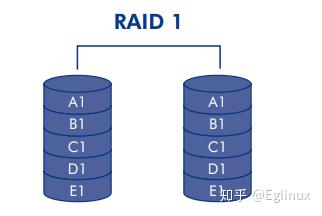
可用容量:不超过较小的那边硬盘的容量总和。
优点:
读取性能翻倍。
提供数据冗余,如果其中一块数据丢失,可以通过另一块还原。
缺点:
磁盘的利用率低,成本高。
RAID 3
原理:RAID 3 使用字节级别的条带化技术,并采用专用的奇偶校验磁盘。RAID 3 阵列能在一个磁盘出现故障的情况下确保数据不丢失。如果一个物理磁盘出现故障,该磁盘上的数据可以重建到更换磁盘上。如果数据尚未重建到更换驱动器上,而此时又有一个磁盘出现故障,那么阵列中的所有数据都将丢失。本质上和 RAID 0 相同,与 RAID 2 相似,作为 RAID 0 的优化版本。
下图是 RAID 3 的实现架构图,图中 Disk 4 就是那块专用的奇偶校验磁盘。
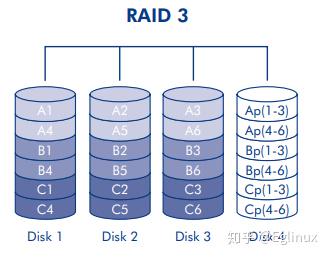
优点:
加入了数据纠错机制。
缺点:
做奇偶校验会消耗系统性能,容易导致系统出现性能瓶颈。
变种(RAID 3 + Spare)
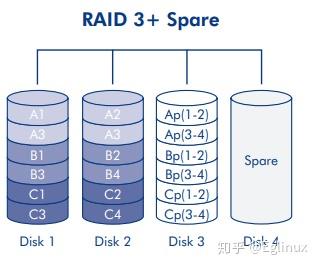
这种变种在主磁盘遇到故障的时候不需要立即处理,Spare 磁盘会无缝顶替上去。
RAID 5
原理:RAID 5 综合了 RAID 0 的条带化技术以及阵列数据冗余技术(阵列最少包括三个磁盘)。RAID 3 和 RAID 5 之间的区别在于,RAID 3 配置提供的性能更高,但总容量略低。数据会在所有磁盘之间分条,并且每个数据块的奇偶校验块 (P) 写入到同一条带上。如果一个物理磁盘出现故障,该磁盘上的数据可以重建到更换磁盘上。单个磁盘出现故障时,数据不会丢失,但如果数据尚未重建到更换驱动器上,而此时又有一个磁盘出现故障,那么阵列中的所有数据都将丢失。
下图是实现的架构图,其中能够看到,Ap-Dp 奇偶校验是放到和数据同一条带上的。
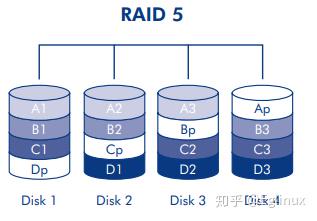
优点:
读写性能高。
有校验机制。
空间利用率高。
缺点:
组成 RAID 5 的磁盘越多,安全性能越差,容易丢失数据。连续两块硬盘损坏,数据就找不回来了。
变种(RAID 5 + Spare)
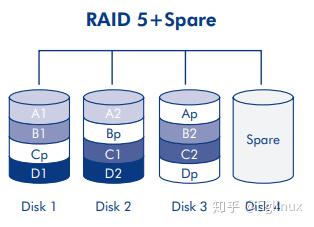
这种变种通过加入空闲的 Spare 盘,在系统将数据重建至备用驱动器时用户仍可以继续访问数据。它能提供良好的数据安全,但磁盘空间由于热备用磁盘的存在(在其他磁盘出现故障之后才使用)而受到限制。磁盘故障不需要立即处理,因为系统会使用热备用磁盘对自己进行重建,但故障磁盘还是应尽快更换。
RAID 6
原理:与 RAID 5 相比,RAID 6 增加了第二个独立的奇偶校验信息块,双重奇偶校验,在 RAID 6 中,数据会在所有磁盘(最少四个)间进行分条,并且每个数据块的两个奇偶校验块(如下图中的 p 和 q)写入到同一条带上。如果一个物理磁盘出现故障,该磁盘上的数据可以重建到更换磁盘上。这种 RAID 模式最多允许两个磁盘出故障而不丢失数据,而且它能更快地重建故障磁盘上的数据。
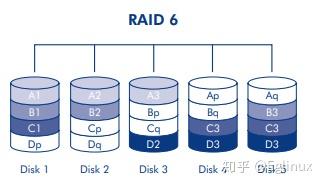
优点:
读取性能好。
有奇偶校验机制。
缺点:
成本高,写入性能差。
RAID 01
原理:RAID 0 + RAID 1,两边都是条带化的 RAID 0 存储数据,然后互为备份,组成镜像存储 RAID 1。
下图是 RAID 01 的架构图,在 RAID 01 阵列中,最多允许两个磁盘出现故障而不会丢失数据,但故障磁盘必须属于同一 RAID 0 队列。在图中,也就是当磁盘 1 和磁盘 2 出现故障时,数据会保存到磁盘 3 和磁盘 4。
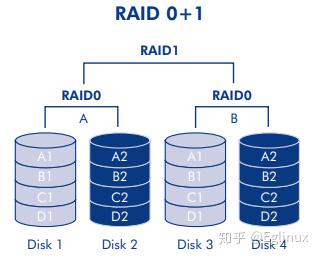
优点:
有数据备份,出现单点故障时可以恢复数据。
缺点:
成本高。
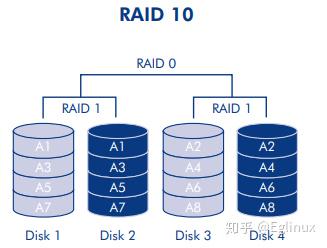
RAID 10
原理:RAID 1 + RAID 0,它合并了其他级别(尤其是 RAID 1 和 RAID 0)特点的另一种 RAID 级别。这是一种“镜像集条带”,意思是数据在两个镜像阵列间分条。“条带化”在阵列之间发生,而“镜像”是在相同的阵列中出现,两种技术的组合加快了重建的速度。RAID 10 阵列包含的磁盘数应为四的倍数。
下图是 RAID 10 的架构图,在 RAID 10 阵列中,每个镜像对中,可以有一个磁盘出现故障而不丢失数据。不过,故障磁盘所在阵列的工作磁盘会成为整个阵列中的弱点。如果镜像对中的另一个磁盘也发生故障,则会丢失整个阵列。
13. 完成不影响业务对LVM磁盘扩容及缩容示例。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









