







回归

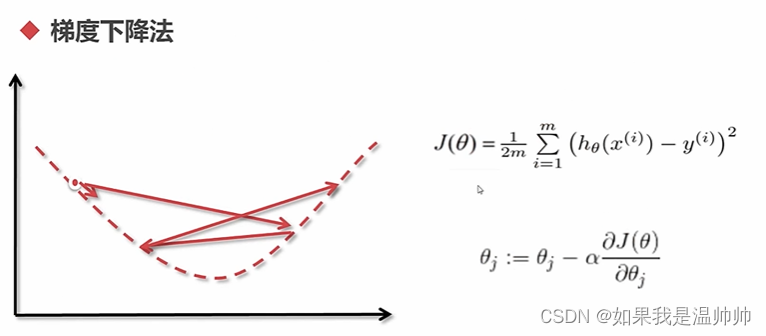
线性回归



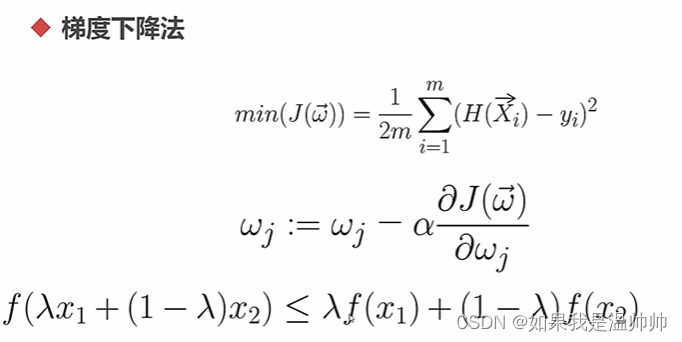
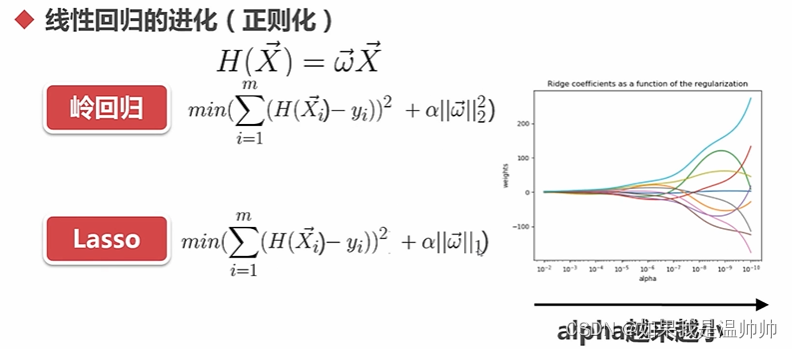
岭回归,lasso回归通过控制参数的规模
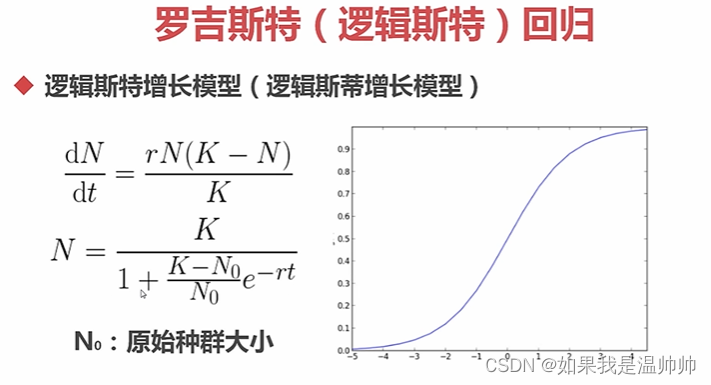
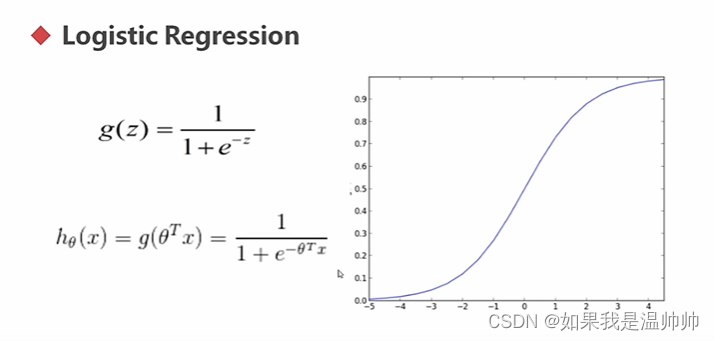
分类-逻辑回归
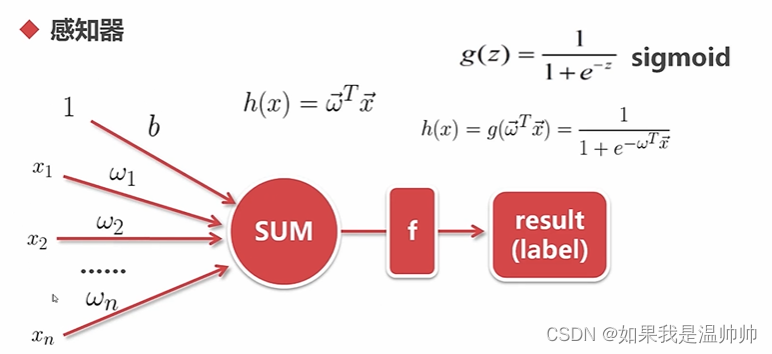
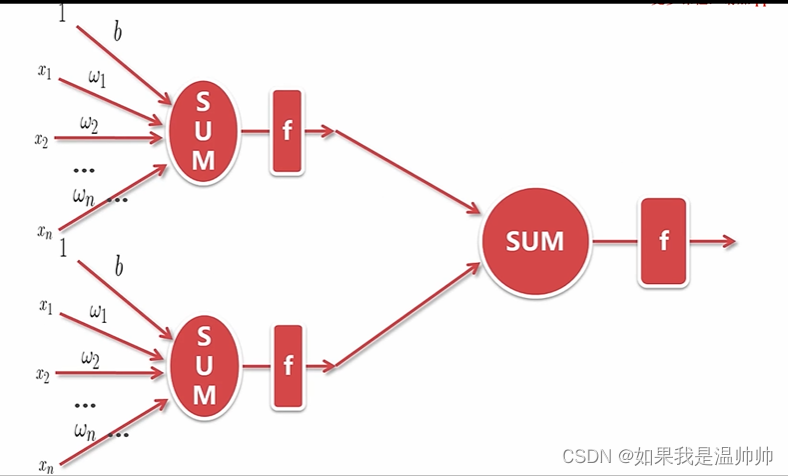
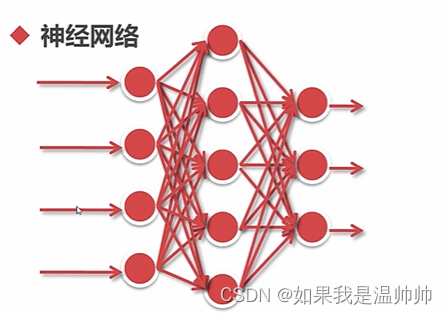
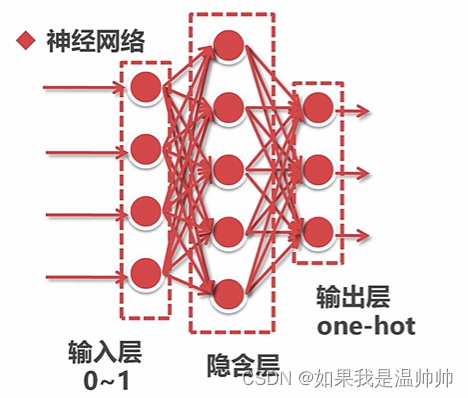
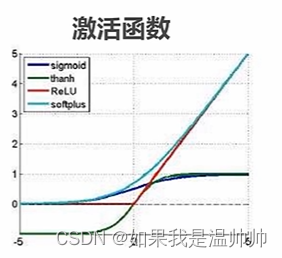
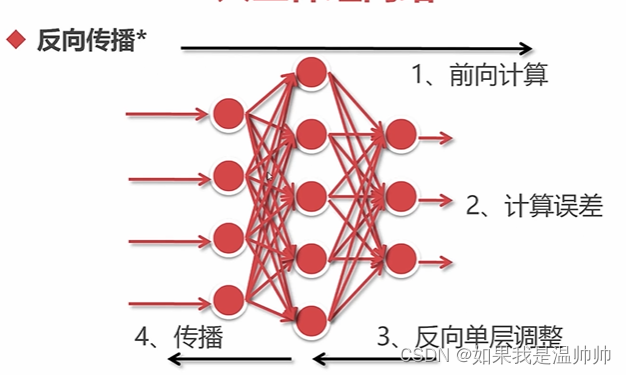
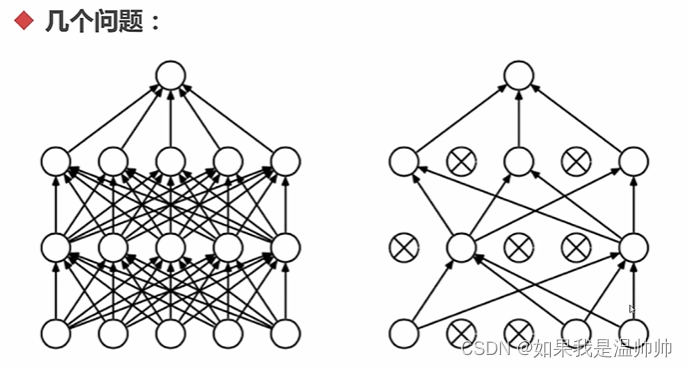
分类-人工神经网络


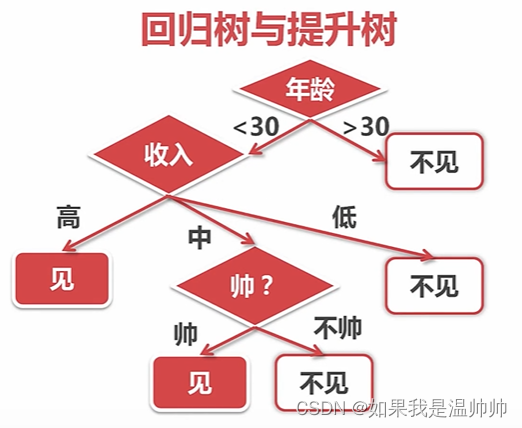
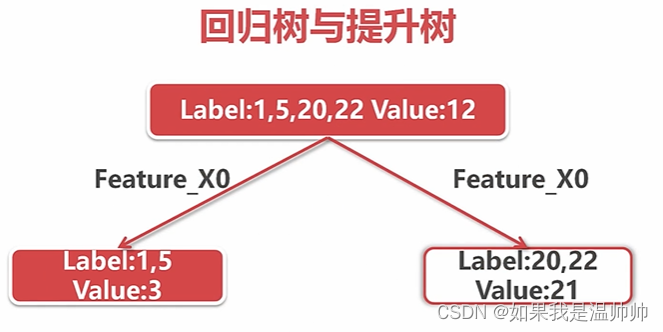
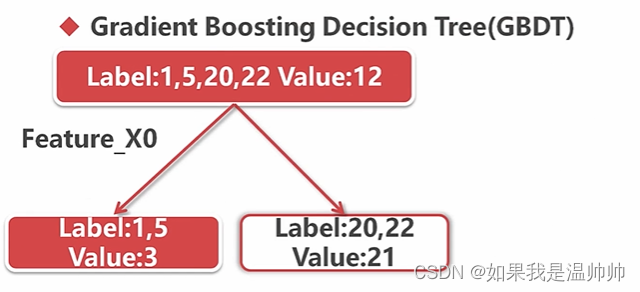
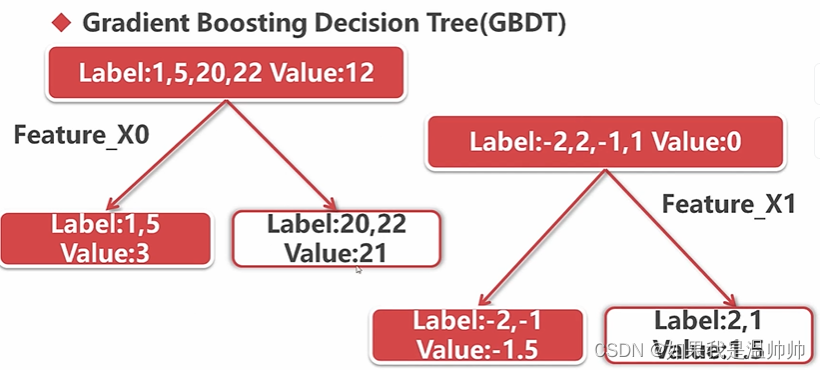
回归树与提升树


代码
from sklearn.model_selection import train_test_split
fv = features.values
f_names = features.columns.values
l_v = label.values
X_tt, X_validation, Y_tt, Y_validation = train_test_split(
f_v, l_v, test_size=0.2)
X_train, X_test, Y_train, Y_test = train_test_split(
X_tt, Y_tt, test_size=0.25)
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score
from sklearn.naive_bayes import GaussianNB, BernoulliNB
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingClassifier
# 贝叶斯,在离散属性下,有更好的表现,对特征有更高的要求
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors=5)))
models.append(("GaussianNB",GaussianNB()))
models.append(("BernoulliNB", BernoulliNB()))
models.append(("DecisionTree", DecisionTreeClassifier()))
#models.append(("svm", SVC(C=10000)))
#models.append(("adaboost", AdaBoostClassifier(base_estimator=SVC(),n_estimators=10000,)))
models.append(("logisiticRegression",LogisticRegression()))
models.append(("GBDT",GradientBoostingClassifier()))
for clf_name, clf in models:
clf.fit(x_train, y_train)
xy_lst = [(x_train, y_train), (x_validation,
y_validation), (x_test, y_test)]
for i in range(len(xy_lst)):
X_part = xy_lst[i][0]
Y_part = xy_lst[i][1]
Y_pred = clf.predict(X_part)
print(i)
print(clf_name, "ACT:", accuracy_score(Y_part, Y_pred))
print(clf_name, "REC:", recall_score(Y_part, Y_pred))
print(clf_name, "F:", f1_score(Y_part, Y_pred))
def regr_test(features,label):
from sklearn.linear_model import LinearRegression,Ridge,Lasso
#regr = LinearRegression()
#regr = Ridge(alpha=0.1)
regr=Lasso(alpha=0.1)
regr.fit(features.values,label.values)
Y_pred = regr.predict(features.values)
regr.coef_
from sklearn.metrics import mean_squared_error
mean_squared_error(Y_pred,label.values)
def main():
features,label=hr_preprocessing()
regr_test(df,label)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









