







 博客主要介绍了机器学习中的分类算法,包括KNN、朴素贝叶斯、决策树、支持向量机、随机森林和Adaboost等。提到KNN中K值取5,朴素贝叶斯有生成和判别模型之分,决策树可针对数据不均衡情况剪枝,Adaboost采用提升法,模型受权重影响大。
博客主要介绍了机器学习中的分类算法,包括KNN、朴素贝叶斯、决策树、支持向量机、随机森林和Adaboost等。提到KNN中K值取5,朴素贝叶斯有生成和判别模型之分,决策树可针对数据不均衡情况剪枝,Adaboost采用提升法,模型受权重影响大。
分类

KNN

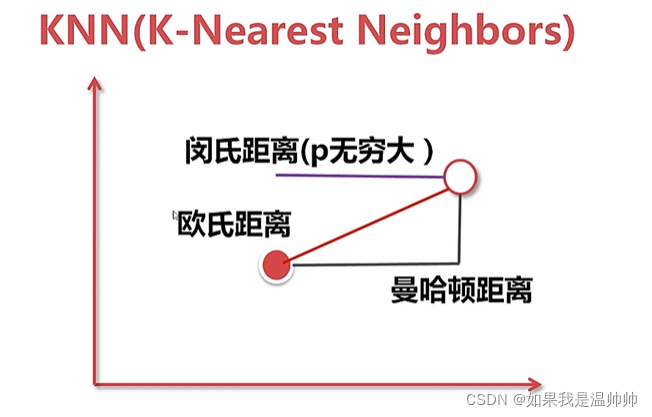
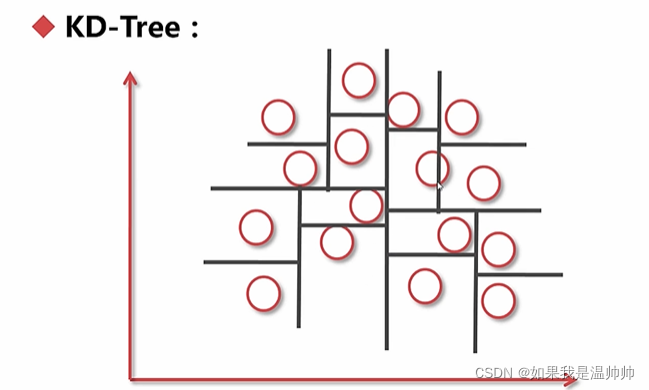
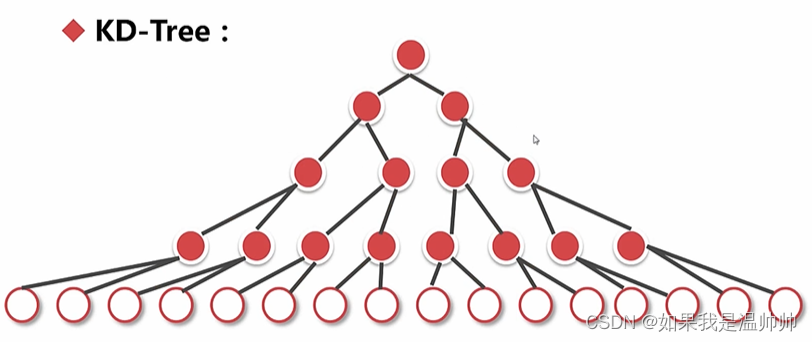
K=5
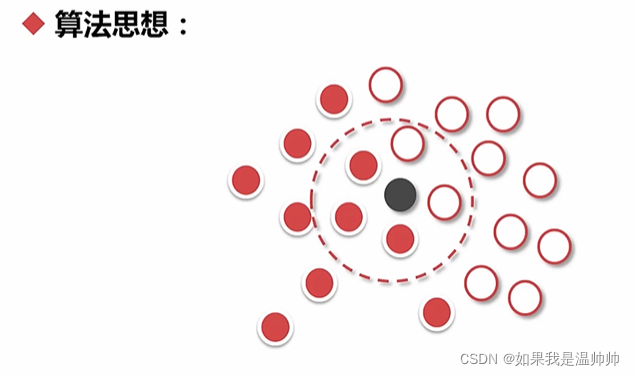
朴素贝叶斯


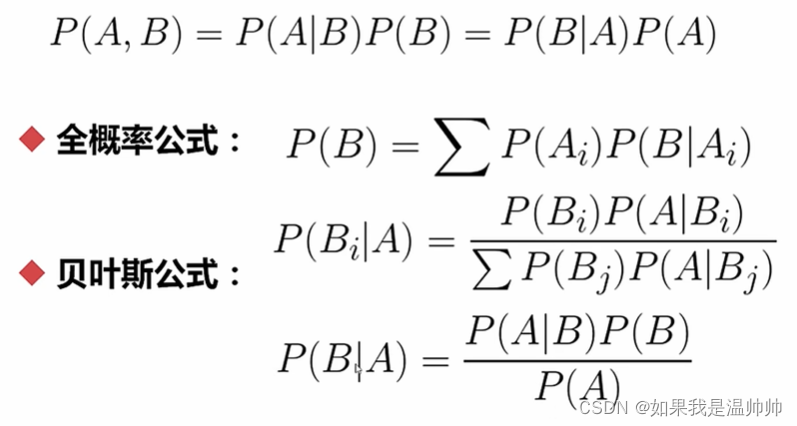




如果有联合概率分布,就是生成模型,如果没有,就是判别模型
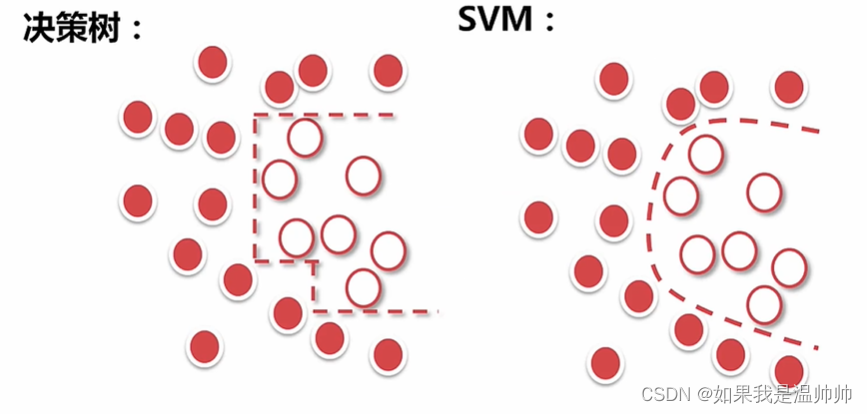
决策树
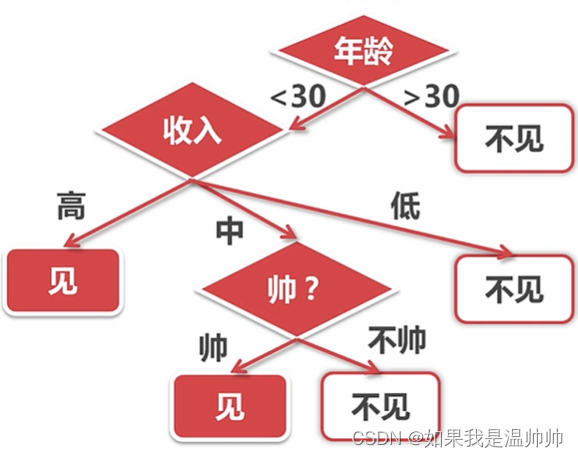
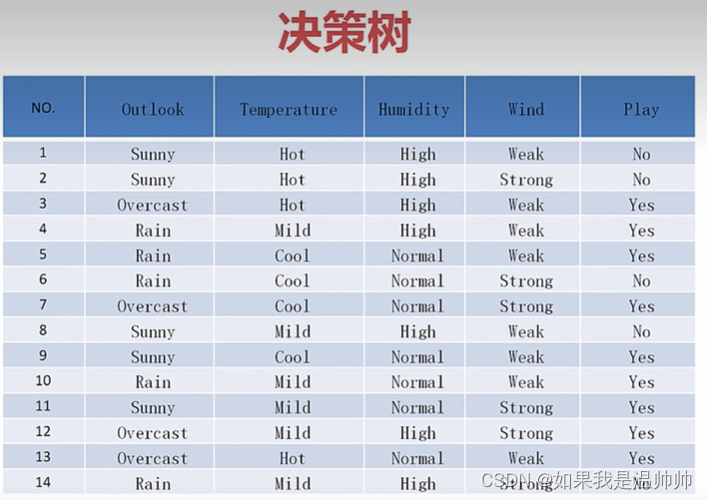
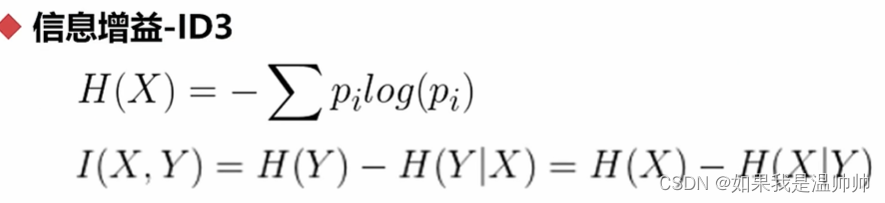
对于上面的例子
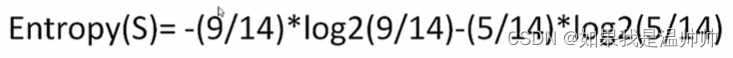


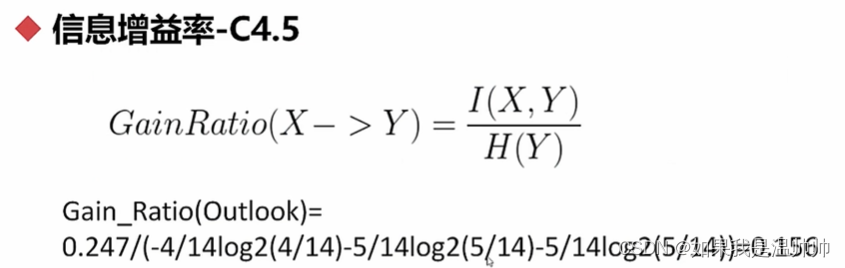
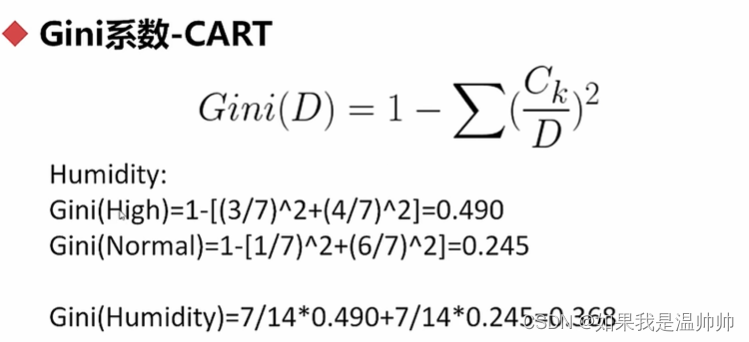
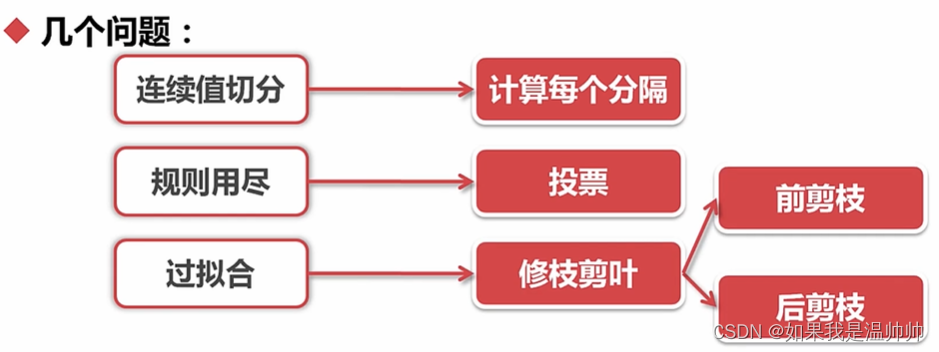
剪枝
对于某些数据不均衡的情况,可以剪枝
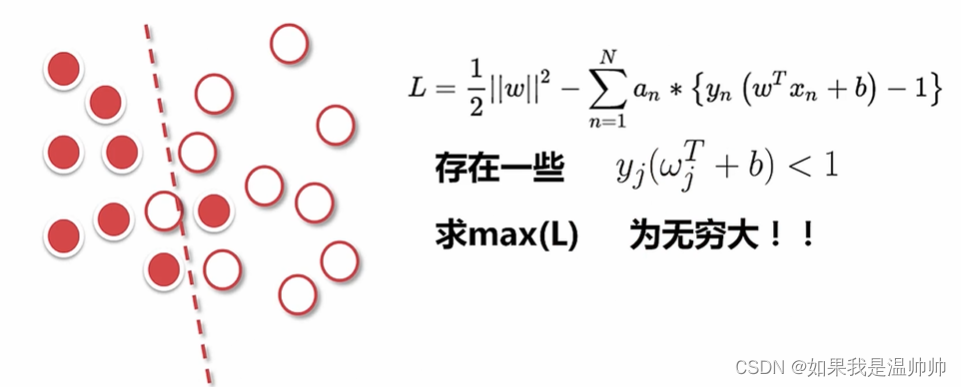
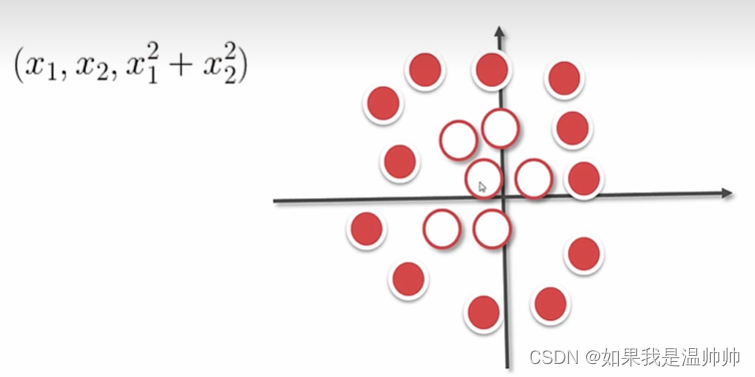
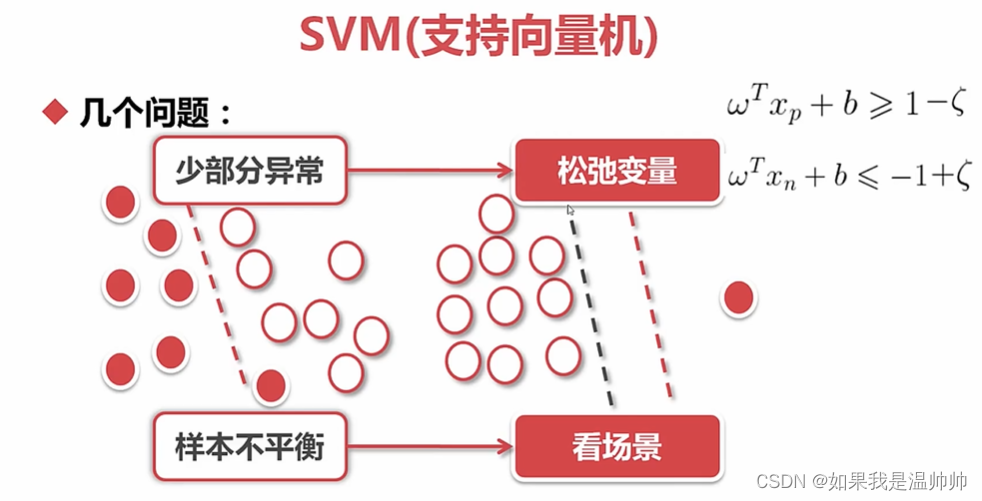
支持向量机(SVM)


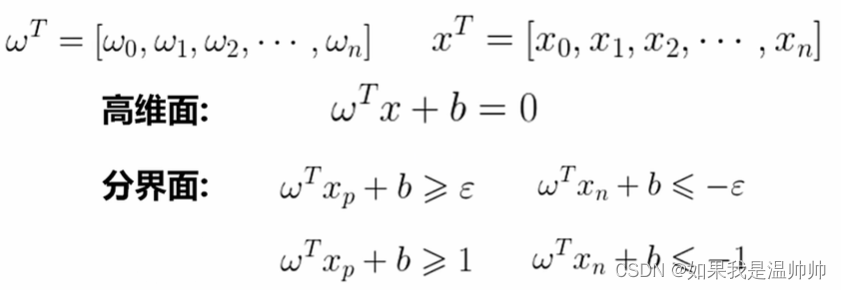

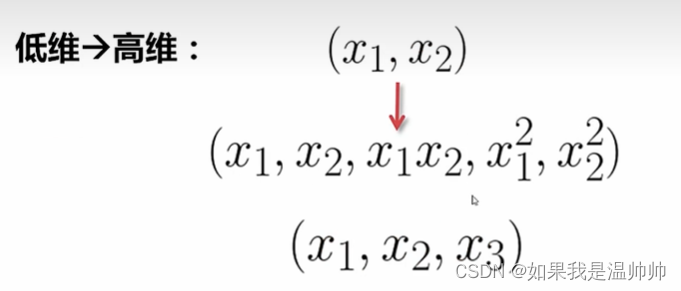

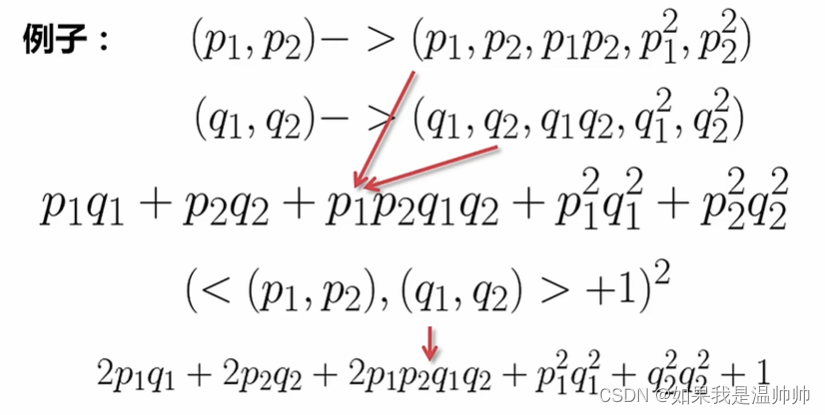


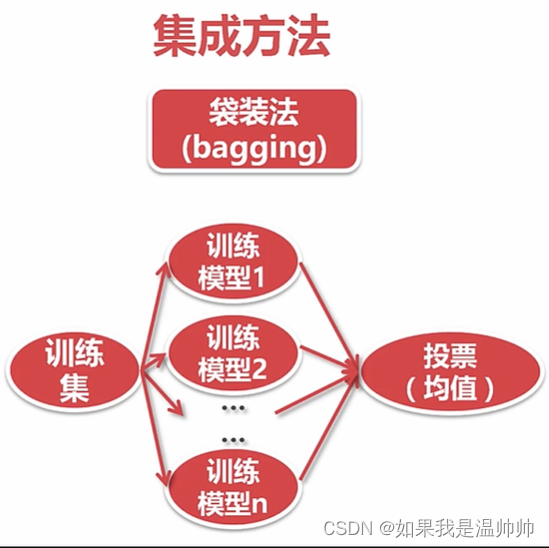
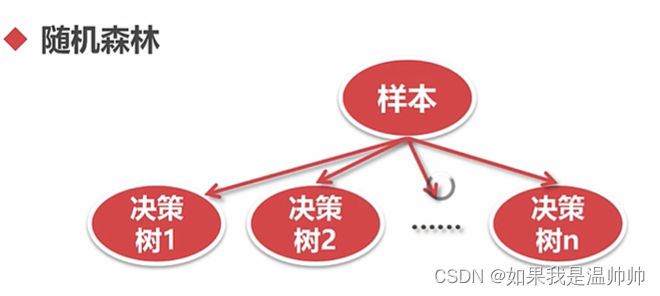
集成-随机森林

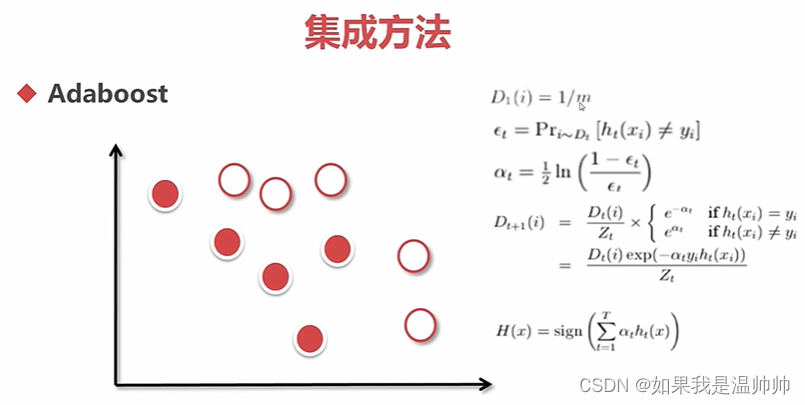
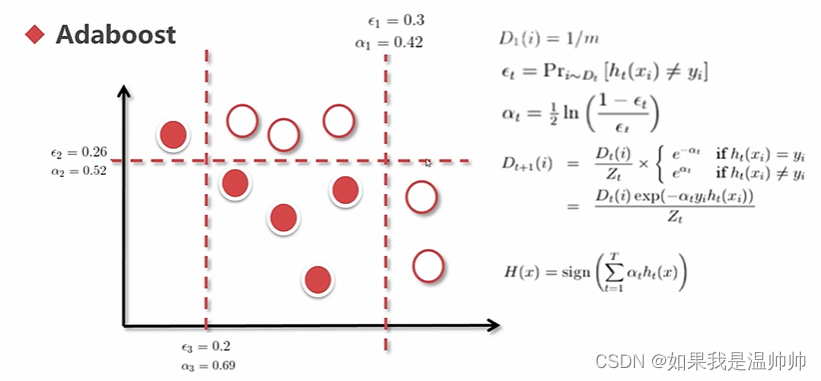
集成-Adaboost
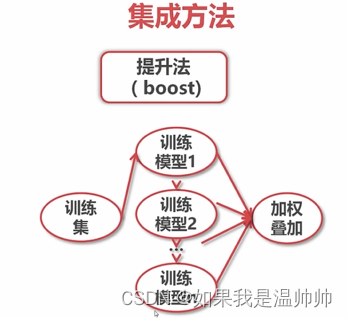
提升法:每个模型都是根据前一个模型训练的结果
最大的影响是权重,而不是顺序


代码
#sl:false:minimaxscaler,true:standerdscalar
#le:last_evaluation,
#cr:False:LabelEncoding,True:OneHotEncoding
def hr_preprocessing(dn=False,ta=False,pn=False,hn=False,vol=False,risk=False,cr=False,lower_d=False,ld_n=1):
df=pd.read_csv(r'C:\Users\wenxiaoyu_intern\Documents\用户画像\shengji.csv')
#1.清洗数据
df=df.fillna(0)
# #2.得到标注
# label=df["shengji_type"]
# df=df.drop("shengji_type",axis=1)
#df=df[df["date_nums"<1000][df["vol"]>0]]
#3.特征选择
#4.特征处理
scaler_lst=[dn,ta,pn,hn,vol,risk]
column_list=["date_nums","total_amount","plan_nums","holding_plan_nums","vol","risk"]
for i in range(len(scaler_lst)):
if not scaler_lst[i]:
df[column_list[i]]=\
MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1,1)).reshape(1,-1)[0]
else:
df[column_list[i]]=\
StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1,1)).reshape(1,-1)[0]
scaler_list=[cr]
column_list=["client_rfm"]
for i in range(len(scaler_list)):
if not scaler_list[i]:
if column_list[i]=="client_rfm":
df[column_list[i]]=[map_client_rfm(s) for s in df["client_rfm"].values]
else:
df[column_list[i]]=\
LabelEncoder().fit_transform(df[column_list[i]].values.reshape(-1,1)).reshape(1,-1)[0]
df[column_list[i]]=\
MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1,1)).reshape(1,-1)[0]
else:
df=pd.get_dummies(df,columns=[column_list[0]])
if lower_d:
#return LinearDiscriminantAnalysis(n_components=ld_n)
return PCA(n_components=ld_n).fit_transform(df.values)
return df
def map_client_rfm(s):
return dict([("sleep",0),("lost",1),("decline",2),("normal",3),("active",4),("new",5),("vip",6)]).get(s,0)
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.preprocessing import Normalizer
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.decomposition import PCA
features_list=["date_nums","total_amount","plan_nums","holding_plan_nums","vol","risk"]
label_list=["shengji_type"]
#df=hr_preprocessing(True,cr=False)
df=hr_preprocessing(dn=True,ta=True,pn=True,hn=True,vol=True,risk=True)
features=df[features_list]
label=df[label_list]
f_v=features.values
l_v=label.values
x_tt,x_validation,y_tt,y_validation=train_test_split(f_v,l_v,test_size=0.2)
x_train,x_test,y_train,y_test=train_test_split(x_tt,y_tt,test_size=0.25)
import pydotplus
def hr_modeling(features, label):
from sklearn.model_selection import train_test_split
fv = features.values
f_names = features.columns.values
l_v = label.values
X_tt, X_validation, Y_tt, Y_validation = train_test_split(
f_v, l_v, test_size=0.2)
X_train, X_test, Y_train, Y_test = train_test_split(
X_tt, Y_tt, test_size=0.25)
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score
from sklearn.naive_bayes import GaussianNB, BernoulliNB
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.externals.six import StringIO
import os
os.environ["PATH"] += os.pathsep+"D:/Program/Graphviz/bin/"
# 贝叶斯,在离散属性下,有更好的表现,对特征有更高的要求
models = []
# models.append(("KNN",KNeighborsClassifier(n_neighbors=5)))
# models.append(("GaussianNB",GaussianNB()))
#models.append(("BernoulliNB", BernoulliNB()))
models.append(("DecisionTree", DecisionTreeClassifier()))
for clf_name, clf in models:
clf.fit(x_train, y_train)
xy_lst = [(x_train, y_train), (x_validation,
y_validation), (x_test, y_test)]
for i in range(len(xy_lst)):
X_part = xy_lst[i][0]
Y_part = xy_lst[i][1]
Y_pred = clf.predict(X_part)
print(i)
print(clf_name, "ACT:", accuracy_score(Y_part, Y_pred))
print(clf_name, "REC:", recall_score(Y_part, Y_pred))
print(clf_name, "F:", f1_score(Y_part, Y_pred))
dot_data = export_graphviz(clf, out_file=None,feature_names=f_names,class_names=['NL','L'],filled=True,rounded=True,special_characters=True)
graph=pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("dt_tree.pdf")
from sklearn.model_selection import train_test_split
fv = features.values
f_names = features.columns.values
l_v = label.values
X_tt, X_validation, Y_tt, Y_validation = train_test_split(
f_v, l_v, test_size=0.2)
X_train, X_test, Y_train, Y_test = train_test_split(
X_tt, Y_tt, test_size=0.25)
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score
from sklearn.naive_bayes import GaussianNB, BernoulliNB
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostClassifier
# 贝叶斯,在离散属性下,有更好的表现,对特征有更高的要求
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors=5)))
models.append(("GaussianNB",GaussianNB()))
models.append(("BernoulliNB", BernoulliNB()))
models.append(("DecisionTree", DecisionTreeClassifier()))
#models.append(("svm", SVC(C=10000)))
models.append(("adaboost", AdaBoostClassifier()))
for clf_name, clf in models:
clf.fit(x_train, y_train)
xy_lst = [(x_train, y_train), (x_validation,
y_validation), (x_test, y_test)]
for i in range(len(xy_lst)):
X_part = xy_lst[i][0]
Y_part = xy_lst[i][1]
Y_pred = clf.predict(X_part)
print(i)
print(clf_name, "ACT:", accuracy_score(Y_part, Y_pred))
print(clf_name, "REC:", recall_score(Y_part, Y_pred))
print(clf_name, "F:", f1_score(Y_part, Y_pred))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









