






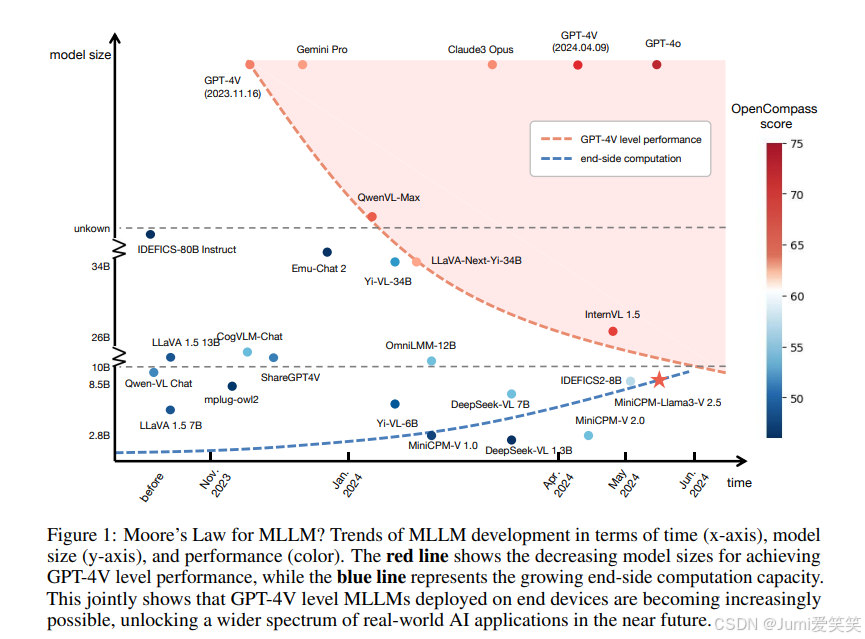
从以上这张图来看,达到gpt4v性能所需的模型体量越来越小;(还是模型越大性能越好);
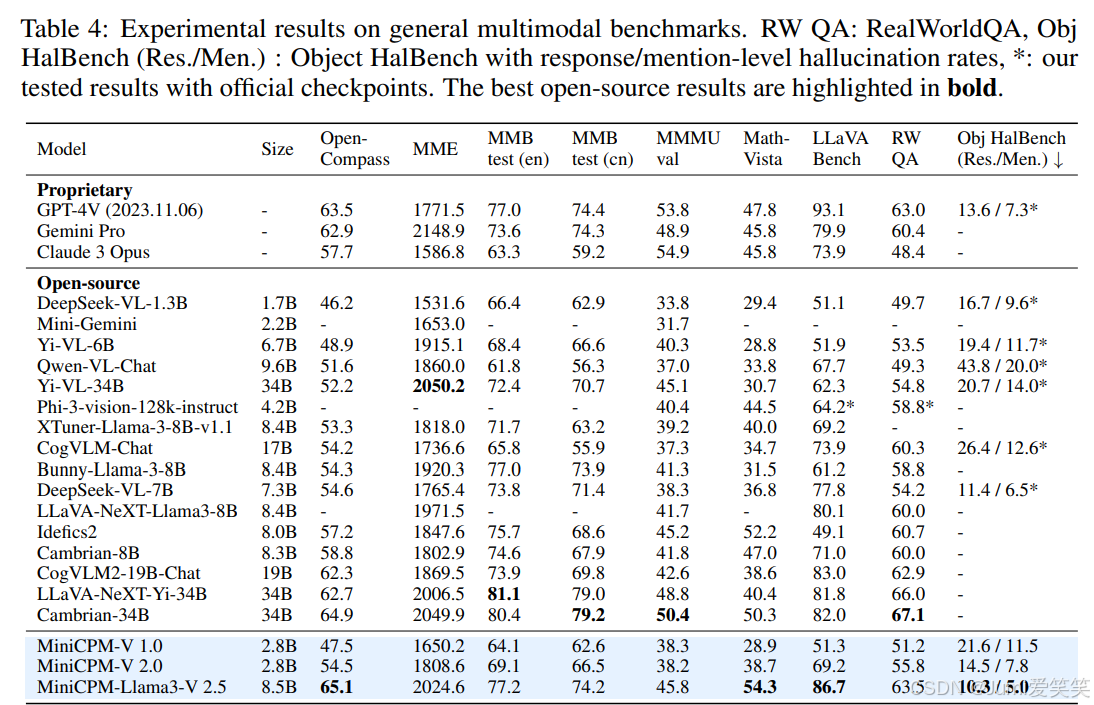
minicpm-2.5的优势主要在于:1.在opencompass上的评分性能优于gpt4v;2可在端侧部署;3.强大的ocr能力;4.支持30多种语言;
模型结果:
目前MLLM不能落地的主要原因是大量的参数和繁杂的计算量;
整个模型架构也是包含三个部分:1.visual encoder;2.compressed layer;3.LLM
1.various aspect ratio的输入;2.position embedding;
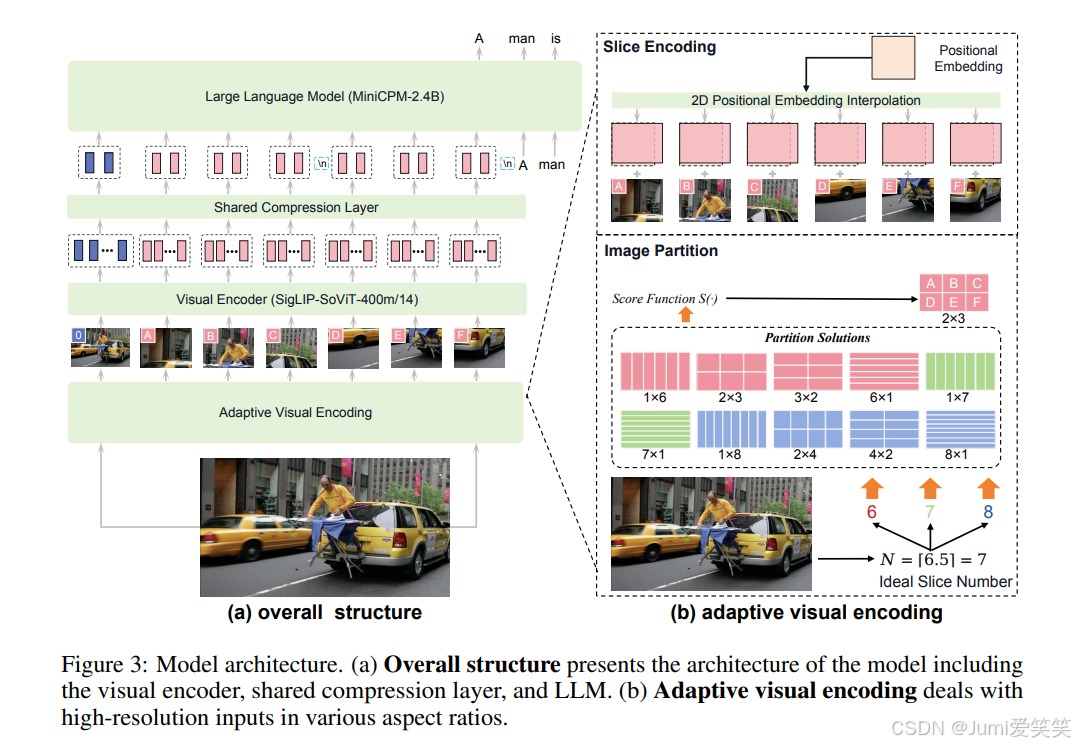
Image Partition:挑选长宽比最符合原图的划分方式;
Slice Encoding:送入vit之前需要resize到固定大小,意思就是会对position embedding也进行插值;同时,全图也会作为一个slice,以保持全局信息;
Token Compression:每个slice经过vit会得到1000个token,经过一个qformer,64个queries会产生64个tokens,可以大大节约计算量;
Spatial Schema:每个slice之间会有一个 and <\slice>专属的slice开头和结束的符号,然后行之间会有一个\n的符号;
Traning:
训练主要分为三个阶段:the pre-training phase, the supervised fine-tuning phase, and the RLAIF-V phase;
pretraining stage1的训练数据:
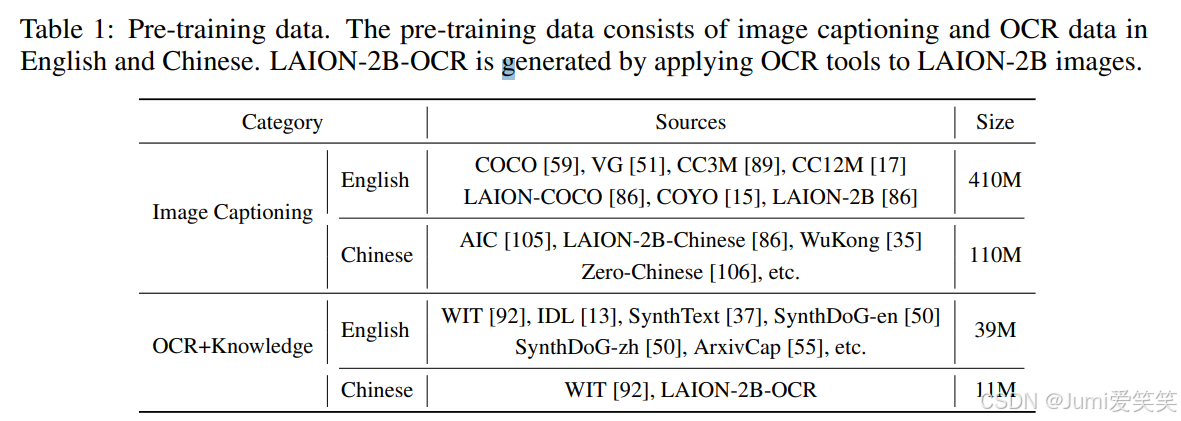
pretraning
stage1:只训练对齐层,其他地方冻住,只用200M的caption数据去训练;
stage2:在训练完压缩对齐层之后,第二阶段把输入分辨率从224224扩展到448448,只训练visual encoder,其他参数是冻结的;用的还是stage1的200M的caption数据;
stage3:该阶段使用aspect ratio进行预训练,visual encoder和compressed layer是打开的,LLM冻住,因为不想拿预训练的低质量的数据去给LLM模型参数造成造成;这一阶段的训练在历史image caption的基础上加上了ocr的数据,因为希望visual encoder具有ocr的能力;
Caption Rewriting:web caption的数据有很多噪声,比如不连续的内容,语法错误,重复的词汇;如此低质量的数据会导致训练的不稳定,然后作者用gpt造了少量的caption rewriting的数据,去训练LLM完成caption rewriting的任务;
Data Packing:数据当中的不同样本有非常不同的长度,这么大的长度方差会导致数据利用的有效性低,以及可能导致oom的错误;为了解决这个问题,我们将多个样本打包成固定长度的单个序列。通过截断序列中的最后一个样本,我们确保序列长度的一致性,促进更一致的内存消耗和计算效率。同时,我们修改了位置id和注意掩码,以避免不同样本之间的干扰。在我们的实验中,数据打包策略在预训练阶段可以带来2~3倍的加速。
支持多语言:对于多语言的需求肯定是存在的,然后其实多语言不需要大量的不同语言的数据的收集,作者只用了中文和英文的数据做预训练,然后用少量且高质量的其他语言的数据finetune就可以轻松对齐到目标语言;
supervised fine-tuning:
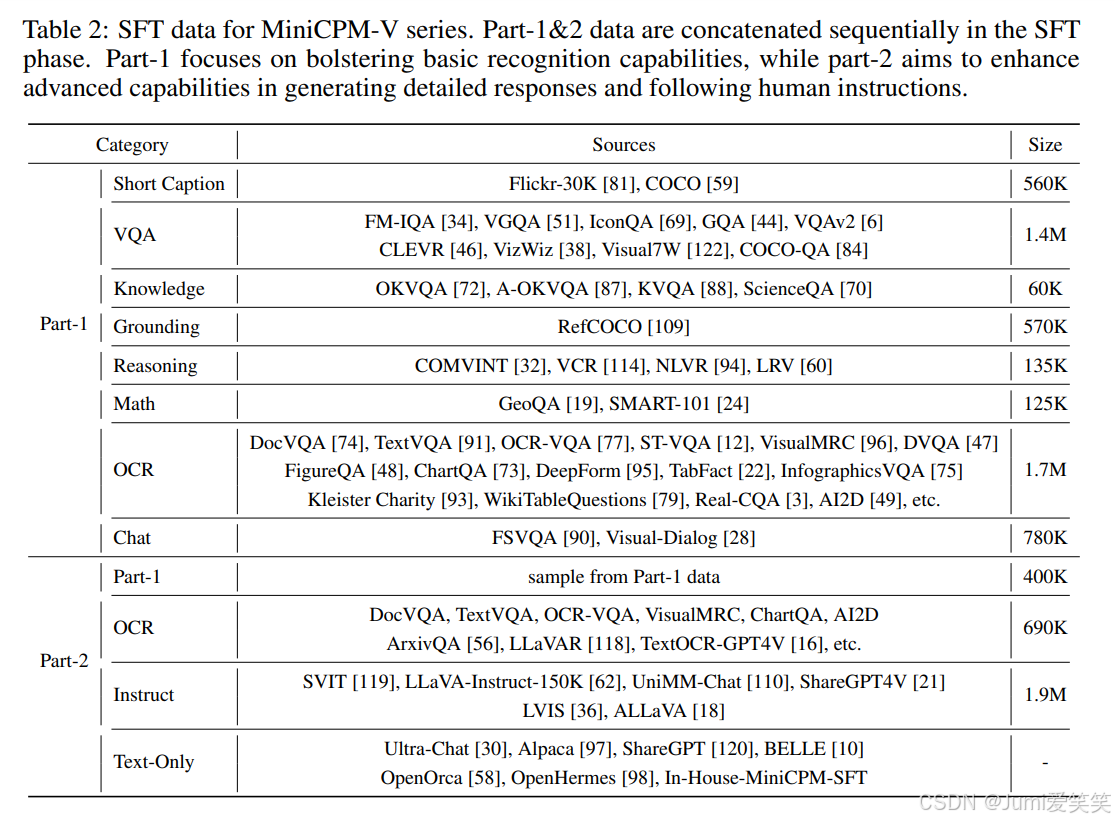
这一阶段主要使用的是高质量的vqa数据,会把所有参数放开训练;
这个阶段的数据分成了两个部分,1:提升基础认知能力的数据,短caption,ocr; 2.instruct following的数据;
RLAIF-V:整体这部分我是模糊看的,感觉大致的意思就是让训练出来的模型通过high temperature(较低置信度阈值的那种)的random sampling生成多组答案,让多个大模型去评测是否有幻觉,确定有幻觉的当作负样本加入训练?https://github.com/RLHF-V/RLAIF-V/blob/main/README_zh.md 这里有更详细的说明;
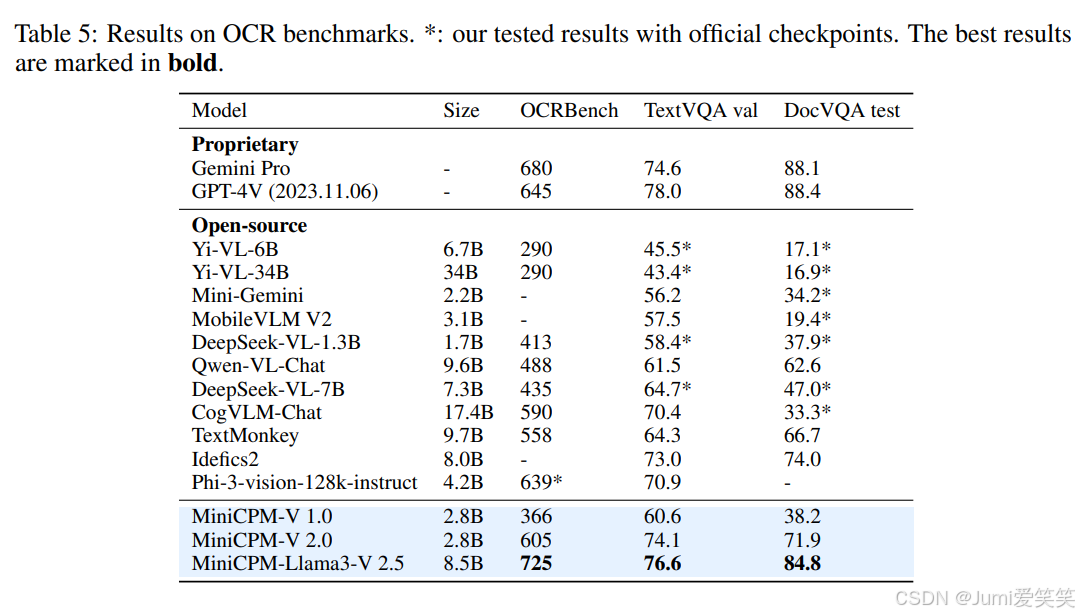
其ocr能力和推理能力都很好:

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









