









 本文详细记录了Hadoop从安装、配置到运行的全过程,包括环境变量设置、XML文件修改、免密登录配置及常见问题解决。作者分享了如何避免和解决在格式化namenode、启动进程、配置端口及使用pig时遇到的各种错误。
本文详细记录了Hadoop从安装、配置到运行的全过程,包括环境变量设置、XML文件修改、免密登录配置及常见问题解决。作者分享了如何避免和解决在格式化namenode、启动进程、配置端口及使用pig时遇到的各种错误。
1.看到网上好多人都把原来的java jdk卸了,然后从官网下载之后解压自己配置环境变量,我也就照着这么做了
rpm -qa | grep java看看有哪些,然后敲
yum -y remove java-1.7.0-openjdk*
yum -y remove java-1.8.0-openjdk*
接着去官网下载了linux版本的压缩包,放到/usr/java里,直接解压,解压命令是tar -zxvf jdk-1.8.0_022(根据自己的jdk的名字来)
解压完删掉压缩包,然后设置环境变量
首先获得权限, su root
vi /etc/profile

按Esc键后输入:wq保存退出,
source /etc/profile,但是这样子做之后发现一个问题,每当我打开新的终端以后,都要source /etc/profile才能echo 出$JAVA_HOME,后面就在.bashrc这个文件里面加了 source /etc/profile,加完保存退出之后再source .bashrc即可
2.安装并配置hadoop
官网直接下载适合的版本,我下了3.1.2版本的,下完之后解压到了/usr/local下,然后还是在/etc/profile下加入环境变量
![]()
加完还是source一下吧,接着就是修改一堆xml文件并创建相应的目录以及两个.sh文件
我在新建了目录/usr/local/hadoop/tmp
修改的文件都在hadoop-3.1.2里面的etc/hadoop下
以下部分的配置修改是参考https://www.cnblogs.com/lovezhaolei/p/5594115.html这位博主的
a. 配置hadoop-env.sh
# java environment
export JAVA_HOME=/usr/java/jdk1.8.0_022
b.配置yarn-env.sh
#java environment
export JAVA_HOME=/usr/java/jdk1.8.0_022
c.配置core-site.xml
要创建目录/usr/local/hadoop/tmp
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
c. 配置hdfs-site.xml
要创建/usr/local/hadoop-3.1.2/hdfs/name跟/usr/local/hadoop-3.1.2/hdfs/data的目录
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop-3.1.2/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop-3.1.2/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
d. 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
e. 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8099</value>
</property>
</configuration>
3.配置本机免密登录(说实话我不是很懂)
# ssh-keygen -t rsa
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
验证嘛,就输入ssh localhost或者 ssh hostname即可
4.启动hadoop啦
a.格式化namenode
./bin/hdfs namenode –format
b.启动NameNode 和 DataNode 守护进程
./sbin/start-dfs.sh
c.启动ResourceManager 和 NodeManager 守护进程
./sbin/start-yarn.sh
但是我在hadoop-3.1.2的目录下输入./sbin/start-dfs.sh
./sbin/start-yarn.sh这两句命令的某一条出现了这样的报错Attempting to operate on hdfs namenode as root....
然后查了资料是说要修改start-dfs.sh, stop-dfs.sh,start-yarn.sh以及stop-yarn.sh
新版的
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改完重启 ./start-dfs.sh
然后我又遇到另外一个问题,我的主机名是audi.com,这个好像是secondaryxxx的地方出的问题
audi.com: ssh: hadoop connect to host audi.com port 22: Connection timed out
然后想起来之前为了配置多虚拟机的hadoop集群,把自己的这台虚拟机的ip地址改成手动配置,连同vmware也改了,
还在/etc/hosts上面一本正经的写了
xxx.xxx.xxx.xxx(这台虚拟机的ip地址) master
=。=想来应该是这里的问题了,就把master改成了我的hostname:audi.com
重新启动下就行了
还启动了jobhistory daemon
# sbin/mr-jobhistory-daemon.sh start historyserver
简单一点可以直接用./sbin/start-all.sh 跟./sbin/stop-all.sh来替代上面的./sbin/start-xxx.sh 跟./sbin/stop-xxx.sh
然后jps是查看进程
我的只有这几个
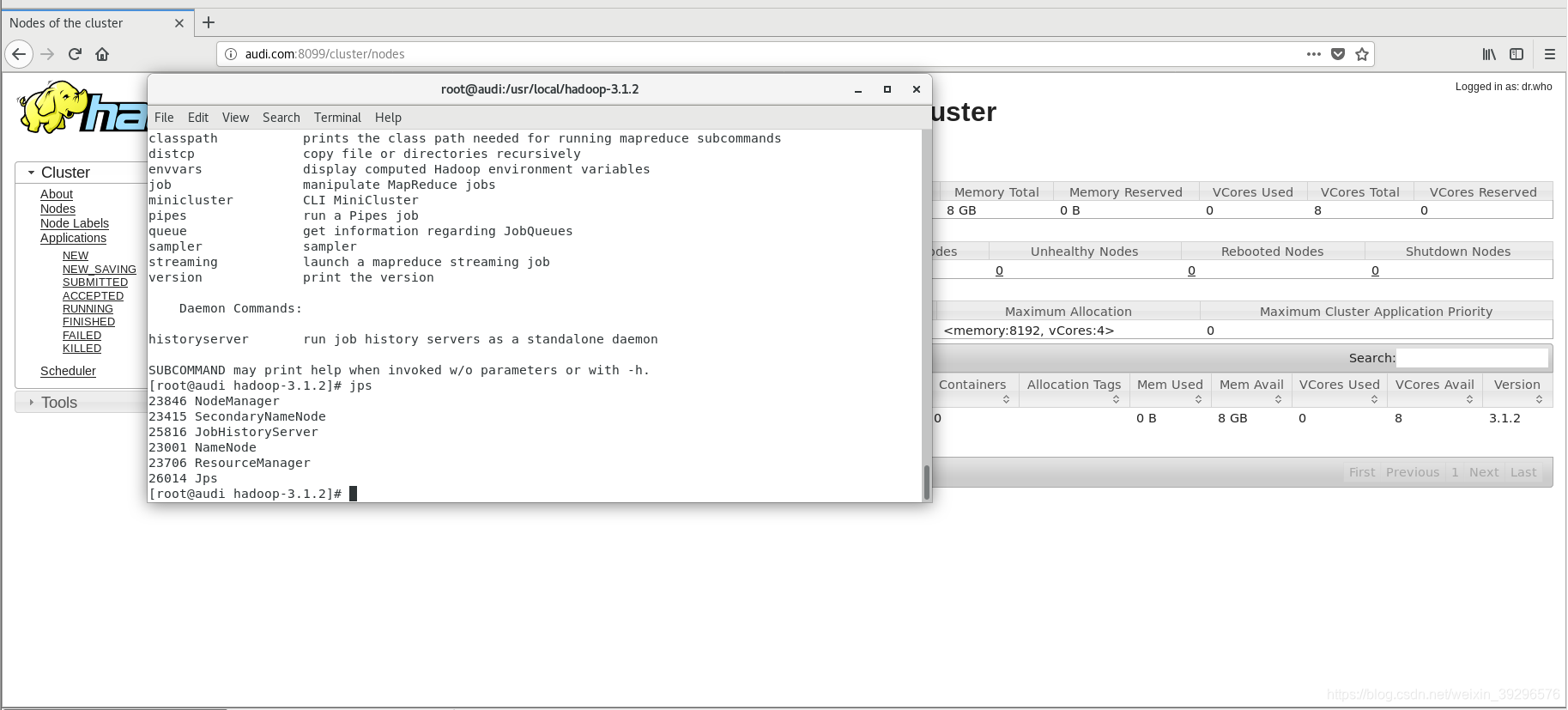
不知道为什么有一些跟别人不一样,图是别的博主的,emm,那个master倒不要紧,要紧的是没有datanode,查看了原因可能是我在格式化namenode的时候格式化太多次出了问题
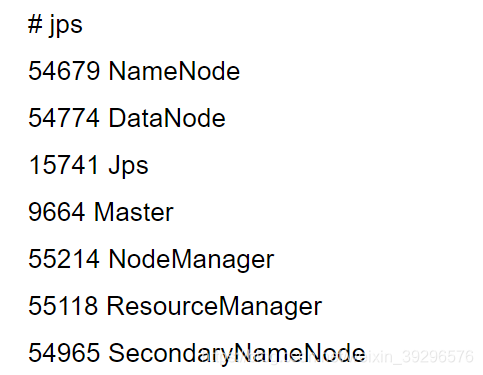
更新一个问题,我还发现我的50070的端口没开,用netstat -ant查的,所以没能看见以下画面
解决以上两个问题的方法:
1.针对没有namenode或者datanode进程,在hadoop-3.1.2目录下使用
./sbin/stop-all.sh将所有进程停掉
然后把/usr/local/hadoop-3.1.2/hdfs/data以及/usr/local/hadoop-3.1.2/hdfs/name下的东西全删了
2.针对50070端口没打开的问题
修改hadoop-3.1.2目录下面的etc/hadoop里面的hdfs-site.xml
添加一以下配置:
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
修改hadoop-3.1.2目录下面的etc/hadoop里面的mapred-site.xml(这一步我也不懂额,查了好久才找到的)
vi mapred-site.xml(注意切换成root)
添加以下配置:
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
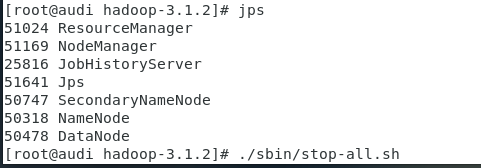
然后重新格式化,启动所有进程,jps查看下情况,也可以netstat -ant看看端口有没有起来
最后成功了
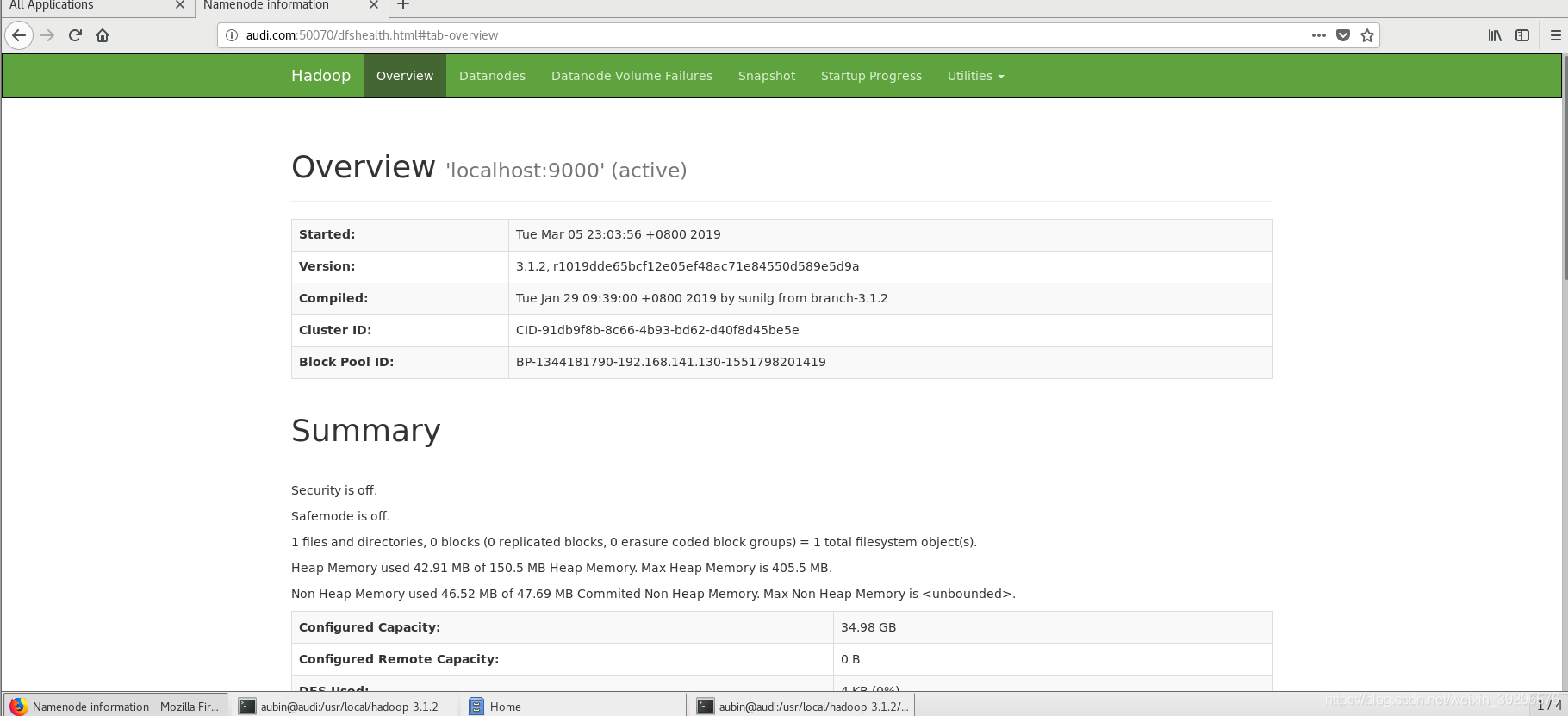
参考链接:https://www.cnblogs.com/lovezhaolei/p/5594115.html
https://blog.youkuaiyun.com/CoffeeAndIce/article/details/78879151
-------------------------------------------------------------------------------------------------------
19.3.29更新一波
前些天开始要用到pig,于是去官网下载了一个,按照说明,我的hadoop是3.1.2版本的,所以选择了最新的那个
下载完后进行一些配置的修改即增加
#hadoop environment
export HADOOP_HOME=/usr/local/hadoop-3.1.2
export PATH=$PATH:$HADOOP_HOME/bin
#pig environment
export PIG_HOME=/usr/local/pig-0.17.0
export PATH=$PATH:$PIG_HOME/bin
export PIG_CLASSPATH=${HADOOP_HOME}/etc/hadoop/
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
一开始有地方写错了pig时出现警告:log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.上面的我pig_home是我自己的pig放的地方,以上的配置无误
当我开了hadoop的进程
put了txt文件在自己创建的/input目录下,准备mapreduce时
hadoop jar /usr/local/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /input/data1file /input/data2file /input/wordcout
出现了这样的问题
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
蒙圈中……
然后从http://wenda.chinahadoop.cn/question/357这个网站得知,是因为在我的环境中,这些宏并没有设置,所以导致任务执行时找不到classpath,所以只能在原来的mapred-site.xml再新增配置
保险起见也许要先把hadoop的进程都关掉先
通过在hadoop-3.1.2目录下,./bin/hadoop classpath 输出我的那串变量
然后vi etc/hadoop/mapred-site.xml,然后把那串值加上去
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop-3.1.2/etc/hadoop:/usr/local/hadoop-3.1.2/share/hadoop/common/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/common/*:/usr/local/hadoop-3.1.2/share/hadoop/hdfs:/usr/local/hadoop-3.1.2/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/hdfs/*:/usr/local/hadoop-3.1.2/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/mapreduce/*:/usr/local/hadoop-3.1.2/share/hadoop/yarn:/usr/local/hadoop-3.1.2/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/yarn/*
</value>
</property>加完保存重启运行就没问题了,然后用pig的时候又遇见了新问题
首先,开启hadoop,
pig 进入pig shell
不要高兴得太早
先输入cd hdsf:///
再ls或者其他对hadoop的操作,不然就跟我这个小白一样又有新错
ls /input看到文件都有,想着来一手骚操作,啊哈
beyond the 'VIRTUAL' memory limit. Current usage: 20.7 MB of 1 GB physical m...
貌似是占用了超过container分配的虚拟内存那样子
然后查了好多博客什么的最后这样修改
在yarn-site.xml中添加博文所述内容:
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
quit退出grunt>然后重启hadoop,pig再来
结果又出现错误:
Redirecting to job history server...Client: Retrying connect to server:
具体如下:
INFO mapred.ClientServiceDelegate: Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
INFO ipc.Client: Retrying connect to server: backup01/192.168.137.200:10020. Already tried
查了一下说是因为我没有启动history server,emmm我真的没启动……
退出pig shell
jobhistory的启动与停止
启动: 在hadoop-3.1.2/sbin/目录下执行
./mr-jobhistory-daemon.sh start historyserver
停止:在hadoop-3.1.2/sbin/目录下执行
./mr-jobhistory-daemon.sh stop historyserver
再进入pig shell
进入hdfs:///
查看文件什么的一切正常
grunt>A = load '/input/donors.txt' using PigStorage(':');
grunt>dump A;
提示:
2019-03-29 21:51:42,968 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2019-03-29 21:51:42,969 [main] INFO org.apache.pig.tools.pigstats.mapreduce.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
3.1.2 0.17.0 root 2019-03-29 21:50:48 2019-03-29 21:51:42 UNKNOWN
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTime AvgMapTime MedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs
job_1553866852522_0003 1 0 24 24 24 24 0 0 0 A,B MAP_ONLY hdfs://localhost:9000/tmp/temp-290433347/tmp1570960628,
Input(s):
Successfully read 12 records (848 bytes) from: "/input/donors.txt"
Output(s):
Successfully stored 12 records (240 bytes) in: "hdfs://localhost:9000/tmp/temp-290433347/tmp1570960628"
Counters:
Total records written : 12
Total bytes written : 240
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
有省略的地方
折腾到此总算成功了=。=


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









