






 本文详细介绍Pandas库的基础操作,包括Series和DataFrame的创建、索引、取值、计算及转换等,适合初学者快速掌握数据分析技能。
本文详细介绍Pandas库的基础操作,包括Series和DataFrame的创建、索引、取值、计算及转换等,适合初学者快速掌握数据分析技能。
说明:pandas是基于numpy构建的软件库,主要应用于数据分析,对原始数据进行处理
1.安装pandas: pip install pandas
2.启动jupyter notebook
3.创建一个新的notebook,并导入pandas
一: Series ,相当于Excel表格中的一列
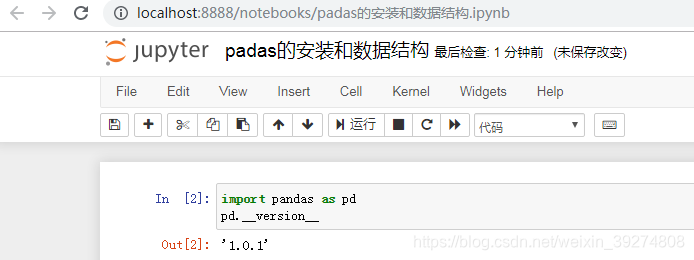
4. Series创建一个数据,ser=pd. Series(['张三','李四','王五']),自动创建索引,默认从0开始. Series相当于Excel表格中的一列
ser = pd.Series(['张三','李四','王五'])
ser运行效果图如下:

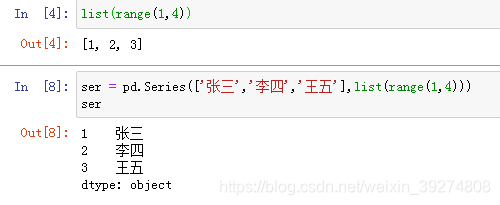
5.自己定义索引值
#1.定义一个列表
list(range(1,4))
#结果:[1, 2, 3]
#2.将列表作为series数据的索引
ser = pd.Series(['张三','李四','王五'],list(range(1,4)))
ser运行效果图如下:
6.根据索引进行取值,改值
#1.获取索引为1的值
ser[1]
#2.修改索引为2的值
ser[2] = 'jack'
ser
#3.获取多个值
ind = [1,3]
ser[ind]运行效果如下:

7.numpy和Series之间的关系
#1.输出ser的数据类型
type(ser)
#2.输出ser的values属性
ser.values
#3.输出ser的values属性的数据类型
type(ser.values)
运行效果如下:

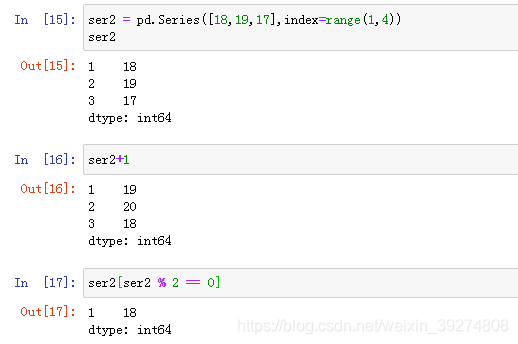
8.Series数据计算
#1.构建一个新的Series
ser2 = pd.Series([18,19,17],index=range(1,4))
ser2
#2.ser2+1,就是每个元素上面进行+1
ser2+1
#3.取出ser2的所有偶数
ser2[ser2 % 2 == 0]
运行效果如下:
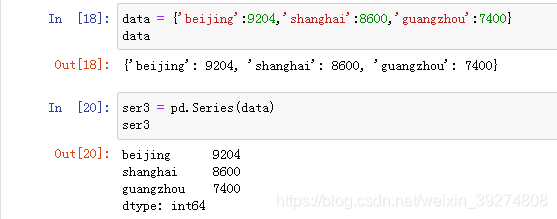
9.用数据字典构建Series
#1.构建一个字典
data = {'beijing':9204,'shanghai':8600,'guangzhou':7400}
data
#2.使用字典构建Series
ser3 = pd.Series(data)
ser3运行效果如下:
10.字典构建Series指定索引,若指定的索引在字典中的Key中不存在,那么返回的值是NaN
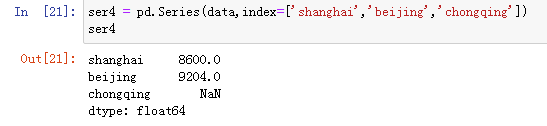
ser4 = pd.Series(data,index=['shanghai','beijing','chongqing'])
ser4
运行效果如下:
11.Series转化成字典、列表、json
#1.转化成字典
ser4.to_dict()
#2.转化成列表
ser4.to_list()
#3.转化成json
ser4.to_json()运行效果图如下:

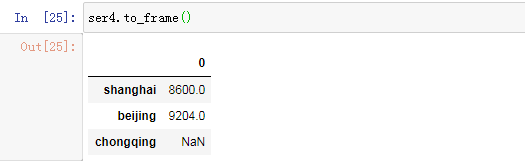
12.Series转化成DataFrame
#转化成DataFrame
ser4.to_frame()运行效果如下:
二:Data_frame,相当于Excel整个表格
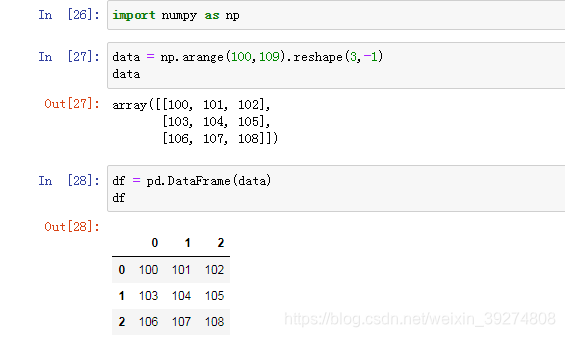
13.二维数组构建一个DataFrame
#1.创建一个二维数组
import numpy as np
data = np.arange(100,109).reshape(3,-1)
data
#2.创建一个DataFrame数据
df = pd.DataFrame(data)
df运行效果如下:
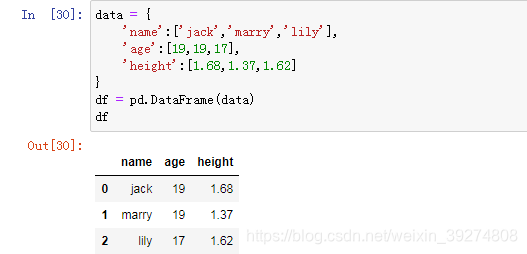
14.使用一个字典构建DataFrame,Key被当做列名,且每个Key的value值个数要一致,否则就会报错
#构建一个字典,使用字典构建一个DataFrame
data = {
'name':['jack','marry','lily'],
'age':[19,19,17],
'height':[1.68,1.37,1.62]
}
df = pd.DataFrame(data)
df运行效果图如下:
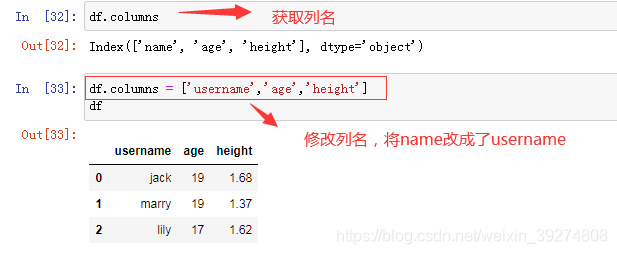
15.使用df. columns获取和修改列名
#1.获取列名
df.columns
#2.修改列名
df.columns = ['username','age','height']
df运行效果图如下:
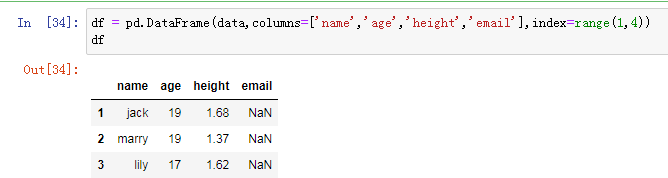
16.通过index指定索引值
#通过index指定索引
df = pd.DataFrame(data,columns=['name','age','height','email'],index=range(1,4))
df运行效果图如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









