







hadoop 离线 day07 HDFS文件系统的基本特性和操作
1、HDFS文件系统的基本特性
HDFS的特性:
- master/slaver架构:主从架构
- namenode:主节点,主要用于存储元数据
- datanode:用于存储数据,就是出磁盘的
- 分块存储:把一个大的文件化成一个个小的block块,在hadoop2中,一个block块的大小默认是128M。
- 副本机制:一个1280M的文件需要拆成10个block块,每个block块都有三个副本。
- 一次写入,多次读取:适用于频繁读取的情况,不适用与频繁写入的情况,改变文件,涉及改元数据的改变。
2、HDFS的命令行使用
- ls 查看文件
hdfs dfs -ls path
hdfs dfs -ls /test
hdfs dfs -ls -R /test
- movefromLocal 移动文件夹,是剪切,本地文件没有了
hdfs dfs -movefromLocal localDir hdfs
- moveToLocal 向本地移动文件夹
hdfs dfs -moveToLocal hdfs localDir
- mv 移动文件
hdfs dfs -mv /test/input/install.log /test/input/install2.log
- put 本地上传到hdfs,复制过去
hdfs dfs -put localDir hdfs
- appendToFile 追加到hdfs文件中去
hdfs dfs -appendToFile localfilehdfs hdfsfile
- cat 查看文件内容
hdfs dfs -cat hdfsfile
- cp 复制文件
hdfs dfs -cp hdfsfile hdfsfile2
- rm 删除文件或文件夹
hdfs dfs -rm hdfsfile
- chmod 修改权限
hdfs dfs -chmod -R 777 hdfsfile
hdfs dfs -chmod -R hadoop:hadoop hdfsfile
- expunge 清空回收站
hdfs dfs -expunge
3、HDFS的高级使用命令
3.1 hdfs的文件限额配置
- 数量限额
hdfs dfs -mkdir -p /user/root/wq
# 限额只能2个(本身算一个,其实只能上传一个文件)
hdfs dfsadmin -setQuota 2 /user/root/wq
# 删除限额
hdfs dfsadmin -clrQuota /user/root/wq
- 空间大小限额
hdfs dfs -rmr /user/root/wq/
hdfs dfsadmin -setSpaceQuota 4k /user/root/wq
# 删除限额
hdfs dfsadmin -clrSpaceQuota /user/root/wq
# 查看限额
hdfs dfs -count -q -h /user/root/wq
3.2 hdfs的安全模式
在集群刚启动的时候,集群处于安全模式的,对外不提供任何服务,只做集群的自检。如果集群自检没有问题,则过三十秒自动脱离安全模式。
#查看是否处于安全模式
hdfs dfsadmin -safemode get
#进入安全模式
hdfs dfsadmin -safemode enter
#离开安全模式
hdfs dfsadmin -safemode leave
4、hadoop的基准测试
集群搭建成功之后,第一件事就是做基准测试,就是压力测试,测试网络带宽,文件读取速度和写入速度等
4.1 测试写入速度
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.0.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
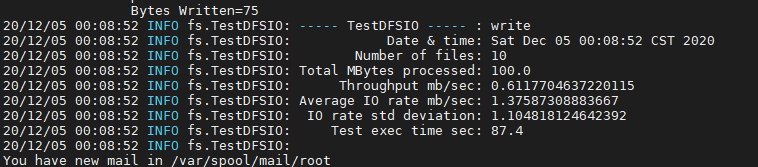
测试结果跟磁盘转速有关系,一般也就7200/min 5400/min,服务器的转速轻松过万。
磁头不动,磁盘转动。
真实的服务器写入速度在20-30M/秒
4.2 测试读取速度
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.0.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
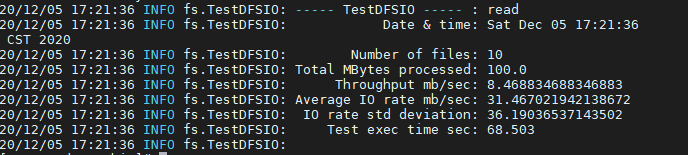
本次测试大于为36M/s,有一些机器比较新,由于集群是搭建在一台物理机上的三台虚拟机,读取操作相当于操作本地文件 ,因此读取速度比较快,测试结果能达到超过100 M,一般真实服务器速度大约在50-100M每秒的样子
# 清除测试数据
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.0.jar TestDFSIO -clean
实际线上环境该如何压测:
从小到大 ,10M,100M,500M
复习:


















 3008
3008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









