







 本文介绍了ClickHouse的基本概念,包括OLTP与OLAP的区别,ClickHouse的特点、部署方式、目录结构等。同时,还详细讲解了ClickHouse的服务端及客户端配置方法、数据存储结构及其引擎类型。
本文介绍了ClickHouse的基本概念,包括OLTP与OLAP的区别,ClickHouse的特点、部署方式、目录结构等。同时,还详细讲解了ClickHouse的服务端及客户端配置方法、数据存储结构及其引擎类型。
基本概念
OLTP(on-line transaction processing)
针对事务处理。
保证数据增删改的强一致性。
OLAP(On-Line Analytical Processing)
针对数据的分析处理。
主要针对数据的读请求,基本不存在或者很少对数据进行修改。
数据量比较大,数据落库多呈现批量落库。
不要求数据的强一致性。
特点
列式存储,高效率的数据压缩。
支持海量数据的存储,优秀的单机存储能力。
数据吞吐量相当大,亿级数据量查询效率可达到毫秒级。
支持数据副本,实现高可用。
支持分布式表,实现水平扩容。
可作为实时数仓或离线数仓。
每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。
ClickHouse对CPU的压榨比较狠,建议并发请求客户端不超过100。
ClickHouse的查询语法类似Mysql,容易上手。
部署
安装链接:https://repo.clickhouse.com/tgz/
安装脚本:
tar -xzvf clickhouse-common-static-21.9.4.35.tgz tar
clickhouse-common-static-21.9.4.35/install/doinst.sh
tar -xzvf clickhouse-common-static-dbg-21.9.4.35.tgz
clickhouse-common-static-dbg-21.9.4.35/install/doinst.sh
tar -xzvf clickhouse-server-21.9.4.35.tgz
clickhouse-server-21.9.4.35/install/doinst.sh
tar -xzvf clickhouse-client-21.9.4.35.tgz
clickhouse-client-21.9.4.35/install/doinst.sh
安装server时,提示输入default用户的密码,直接回车即可(暂不设置)。
启动:
clickhouse restart
说明:
1.默认端口:
1)9000: 默认client连接端口
2)8123:默认JDBC访问端口
2.默认客户端访问方式
1) clickhouse-client:单行模式(SQL语句不可换行)
2) clickhouse-client -m:单行模式
目录结构
脚本文件:/usr/bin
配置文件:/etc/clickhouse-server/ 需重点关注: /etc/clickhouse-server/config.xml
运行日志:/var/log/clickhouse-server/
数据目录 :/var/lib/clickhouse/
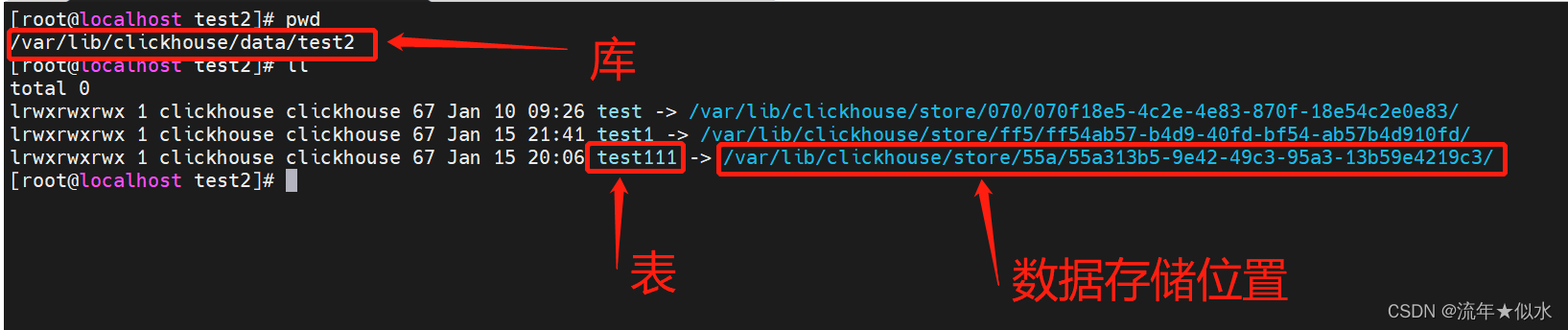
每个库在/var/lib/clickhouse/data目录下,会创建一个子目录。
子目录下每个表一个文件(表名),并指向数据存储的位置。
数据存储位置:/var/lib/clickhouse/store/目录下。
样例:库test2 表test的数据存储结构:
远程访问
1.服务端配置(ClickHouse默认不支持远程访问):
1) 修改文件:/etc/clickhouse-server/config.xml
使支持远程访问:<listen_host>::</listen_host>
2) 重启:clickhouse restart
2.客户端配置
驱动:
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
基础配置:
spring:
datasource:
driver-class-name: ru.yandex.clickhouse.ClickHouseDriver
username: default
password:
url: jdbc:clickhouse://x.x.x.x:8123/xxxClickhouse的数据存储结构
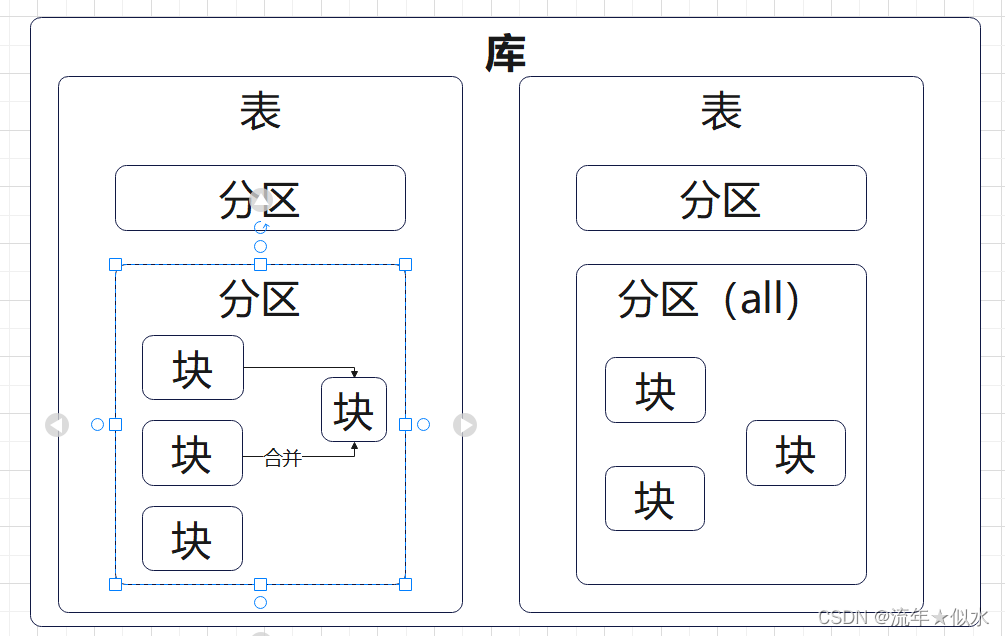
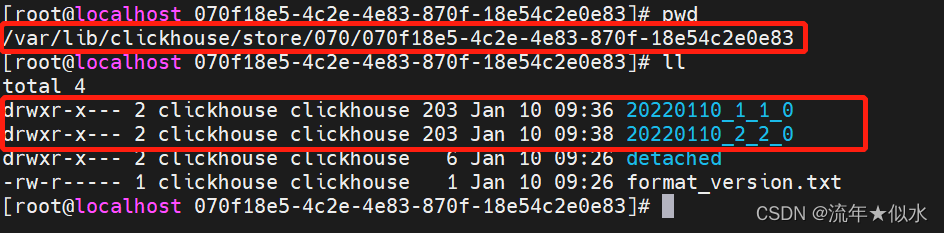
指定分区(由分区键指定)
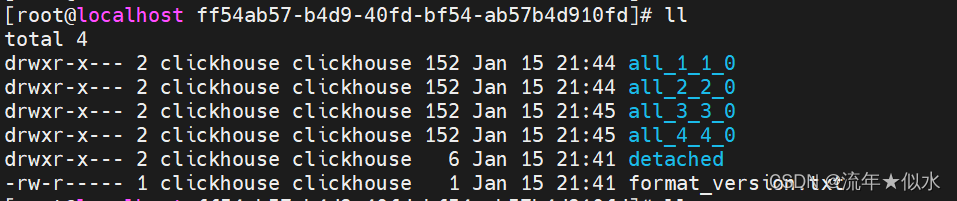
未指定分区(默认一个分区:all)
数据内容:
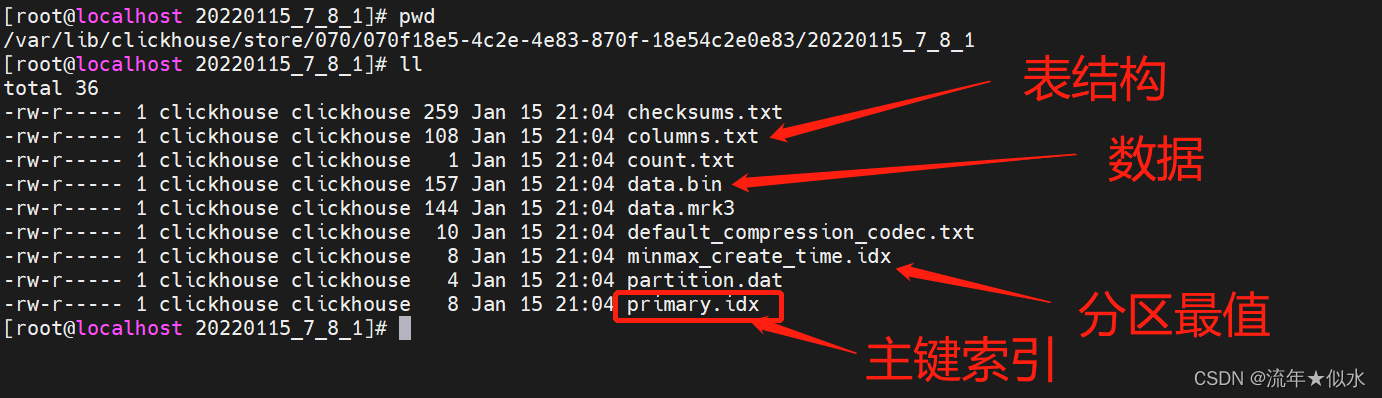
说明:
- xxx_a_b_c
xxx:分区名称
a:本块的最小编号
b:本块的最大编号
c:合并次数
- 每次插入数据,生成一个数据片段(非在原有片段上追加或者修改)--->所以最好批量插入。
- 如果一次插入的数据,分布在多个分区,那就会生成多个数据片段。
- 分区是为了增加查询速率,并不影响查询结果(MergeTree引擎底层使用一种类似于LSM树的结构来保存数据)。ClickHouse后台会进行分区合并,时机不定。也可手动合并,但不推荐:optimize table xxx final。
库引擎
Atomic(默认,一般选用这个)
MySQL(转发请求)
PostgreSQL
MaterializeMySQL(可作为从库读取musql数据库,暂不稳定)
MaterializedPostgreSQL
表引擎
MergeTree 合并树家族(最为重要,后续主要研究 MergeTree)
Log 日志系列
Integration Engines 集成引擎
Special Engines 特别引擎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









