







 本文记录了一次线上微服务因CPU使用率升高导致服务不可用的排查过程。经过分析日志、下游系统监控、调用量、HTTP请求和机器状态,初步排除了各种常见问题。最终发现是由于加解密操作中频繁创建BouncyCastleProvider对象,导致内存泄露。通过MAT工具分析堆文件,定位到javax.crypto.JceSecurity对象占用大量内存。修复方案是将对象设置为静态,避免频繁创建。
本文记录了一次线上微服务因CPU使用率升高导致服务不可用的排查过程。经过分析日志、下游系统监控、调用量、HTTP请求和机器状态,初步排除了各种常见问题。最终发现是由于加解密操作中频繁创建BouncyCastleProvider对象,导致内存泄露。通过MAT工具分析堆文件,定位到javax.crypto.JceSecurity对象占用大量内存。修复方案是将对象设置为静态,避免频繁创建。
前言
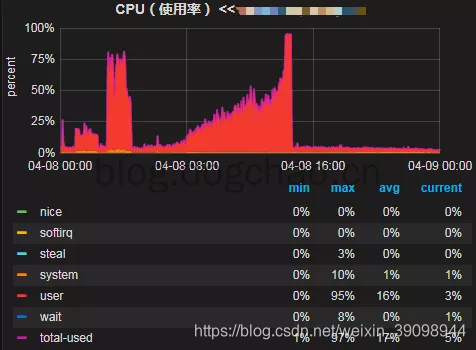
下面是线上机器的cpu使用率,可以看到从4月8日开始,随着时间cpu使用率在逐步增高,最终使用率达到100%导致线上服务不可用,后面重启了机器后恢复
简单分析下可能出问题的地方,分为5个方向:
-
系统本身代码问题
-
内部下游系统的问题导致的雪崩效应
-
上游系统调用量突增
-
http请求第三方的问题
-
机器本身的问题
-
开始排查
-
查看日志,没有发现集中的错误日志,初步排除代码逻辑处理错误。
-
首先联系了内部下游系统观察了他们的监控,发现一起正常。可以排除下游系统故障对我们的影响。
-
查看provider接口的调用量,对比7天没有突增,排除业务方调用量的问题。
-
查看tcp监控,TCP状态正常,可以排除是http请求第三方超时带来的问题。
-
查看机器监控,6台机器cpu都在上升,每个机器情况一样。排除机器故障问题。即通过上述方法没有直接定位到问题。
-
解决方案
1、重启了6台中问题比较严重的5台机器,先恢复业务。保留一台现场,用来分析问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









