







在日常生活中,数据的数量并不是相等的。即使是在超大型数据集中,数据的数量差异也广泛存在,例如下图中SUN-397中的数据分布情况。卧室的数据可以达到1000以上,但图书馆甚至不到50。
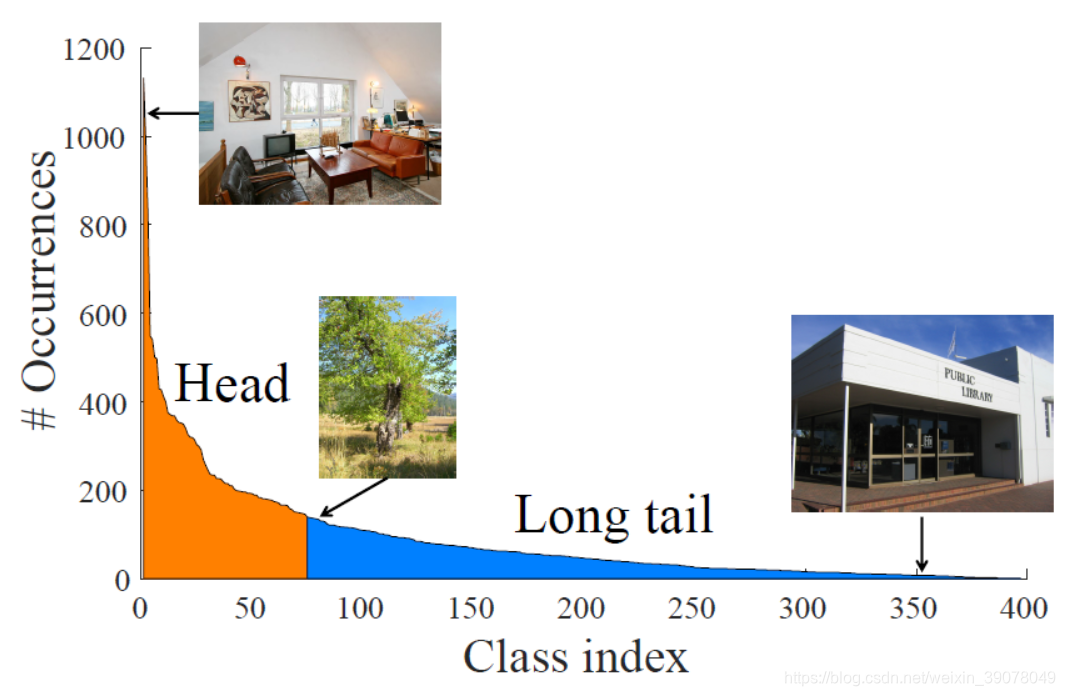
在本文中,这种数据分布情况被称为“长尾”(long tail)。对于处在尾部的数据而言,机器学习算法实际上是在执行小样本学习任务(N-shot learning),这直接导致了相关领域识别的准确率不高。
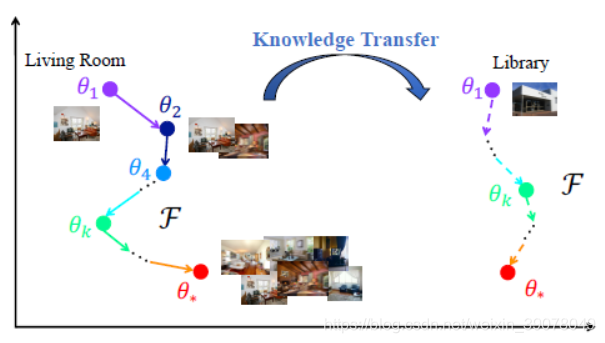
为解决这一问题,本文提出了一种基于元学习的方法。其思想入下图所示。对于具有较多样本的数据,使用基于残差网络(ResNet的思想)的元学习器学习这些学习的进程(Learn to learn),从而使用较少数据实现快速学习。
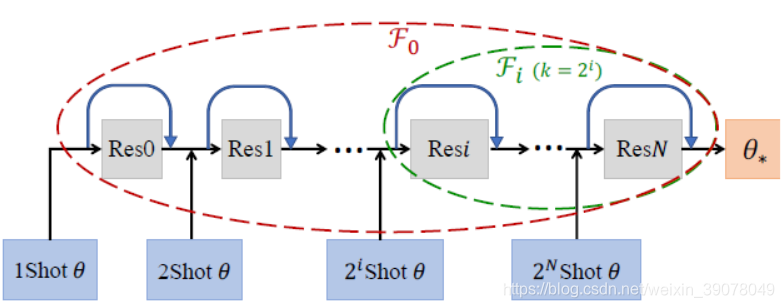
而他们的具体做法是如下图所示。他们使用的是一个N个Block的残差网络,每个模块有独立的参数。他们的具体设想是:第i个残差模块的输入是由
个数据训练所得的CNN网络的参数(这里他们保持CNN前部特征提取网络的参数不变,只将最后一层4096->1000中每一个4096->1的参数
θ作为了Transfer Learning的对象)。也即,第
个Block的作用就是将对应于
个数据的训练参数映射为对应于
的参数。
这种方法的最大好处是,后续的每一个class都可以选择与自己数据量最为契合的输入点,通过其后数层Res网络获得最终的优化参数。原文中使用“幻觉”(hallucinate)形象地描述这一参数演化过程。
网络的训练方面,文中使用了递归的训练方式:先用样本数量大于的类训练最后一层ResN,然后递归的逐渐包含前面的层。在训练第
层时,使用的所有类的样本数量都于
,这样可以保证用于训练的随机选择样本数量小于该类总样本量的一半。
如此这个网络的思想就成型了:当要训练的层由上图中所对应的的变成
所对应的,所用的训练样本来自的类的最小样本数量便会下降一半,如此便有更多的类参与到了训练过程中。这便是本文在摘要部分提出的“从头到身体再到尾巴”的训练方法,前面的类都会用于提高后面的类的训练效果。
如此,网络的思想就讲完了。剩下的一些损失函数定义等请读者看下原文吧。虽然这篇文章是NIPS,但我还是要吐槽:这从小往大写的方法介绍真是完全读不懂!读到损失函数什么的时候我本人完全是懵逼的,而上面我的讲解则是直接将他的介绍倒过来了,是不是觉得清晰了很多!!!

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









