






Mysql数据库迁移说明文档
1、使用工具及工程
| 使用工具 | 作用 |
|---|---|
| datax | 存量数据迁移 |
| canal + otter | 增量数据迁移–方案 |
增量数据迁移,方案一和方案二,选择其中一个即可
2、前提步骤
1、待同步的Mysql,需要开启binlog日志
[mysqld]
server_id=1 # 服务编号, 与其它节点不冲突即可
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
1、将所有的表结构,通过工具或者命令导出(只导表结构),形成.sql文件
2、将sql文件中的相关表结构进行修改
- 修改存储引擎,将MyISAM修改为InnoDB
- 将某些表结构中,主键id的类型,由int类型,修改为bigint类型
3、针对特殊的表数据,进行单独处理
3、datax使用说明
参考文档:
1、https://github.com/alibaba/DataX/blob/master/introduction.md
2、https://blog.youkuaiyun.com/weixin_46902396/article/details/121904705
3.1、读取目标库中的表名循环
/data/datax/bin/all_Sync_Task.sh
# vi /data/datax/bin/all_Sync_Task.sh
#!/bin/bash
. /etc/profile
# 读库的变量 待修改
r_ip="******" #源库地址
r_port="3306" #源库端口号
r_username="root" #源库用户
r_password="******" #源库密码
dbname="test" #源库database
# 写入库的变量 待修改
w_ip="******" #目标库的地址
w_port="3306" #目标库的端口号
w_username="root" #目标库的用户
w_password="******" #目标库的密码
w_dbname="test" #目标库database
Tool_Datax='/usr/bin/python2.7 /data/datax/bin/datax.py'
# 获取库名
Mysql_Names=`mysql -h$r_ip -u$r_username -p$r_password -P$r_port -e "show databases\G" |grep 'Database'|awk -F'Database: ' '{print $2}' |grep -v 'information_schema\|performance_schema\|test\|sys\|mysql\|test1|'`
# 获取表名
table_tchema=`mysql -h$r_ip -u$r_username -p$r_password -P$r_port -e "use ${dbname}; show full tables;"|grep 'TABLE'|awk '{print $1}'`
#echo $table_tchema;
#循环导入数据库
for table_name in $table_tchema;
do
echo $table_name;
$Tool_Datax /data/datax/job/mysql2mysql_All.json -p "-Dr_ip=$r_ip -Dr_port=$r_port -Dr_dbname=$dbname -Dr_username=$r_username -Dr_password=$r_password -Dw_ip=$w_ip -Dw_port=$w_port -Dw_dbname=$w_dbname -Dw_username=$w_username -Dw_password=$w_password -Dtable_name=$table_name"
done
需要修改all_Sync_Task.sh脚本中读库和写库相对应的变量
3.2、撰写job脚本
/data/datax/job/mysql2mysql_All.json
{
"job": {
"setting": {
"speed": {
"channel": 50
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://${r_ip}:${r_port}/${r_dbname}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull"],
"table": ["${table_name}"]
}
],
"username": "${r_username}",
"password": "${r_password}"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"column": ["*"],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"truncate ${table_name}"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://${w_ip}:${w_port}/${w_dbname}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull",
"table": ["${table_name}"]
}
],
"username": "${w_username}",
"password": "${w_password}"
}
}
}
]
}
}
mysql2mysql_All.json,根据情况,修改channel的值
3.3、执行
[root@server02 bin]# sh all_Sync_Task.sh
3.4、特殊表处理
针对某些表结构或者或者数据的特殊要求,需要针对这些表进行特殊的处理,大致有如下几种情况:
- 表存储引擎必须是InnoDB,不支持MyISAM
- 表中必须包含主键
- 表字段中,若存在函数表达式生成的值,则会插入数据失败(eg:date_format等函数)
- 表字段存在外检依赖,需要提前特殊处理
4、增量数据迁移方案:otter使用说明
官方网站:https://github.com/alibaba/otter
| 地址 | 用户名 | 密码 |
|---|---|---|
| 安装服务器地址:8090 | admin | admin |
配置顺序:数据源–>数据表–>canal–>channel配置–>pipline
4.1、数据源配置

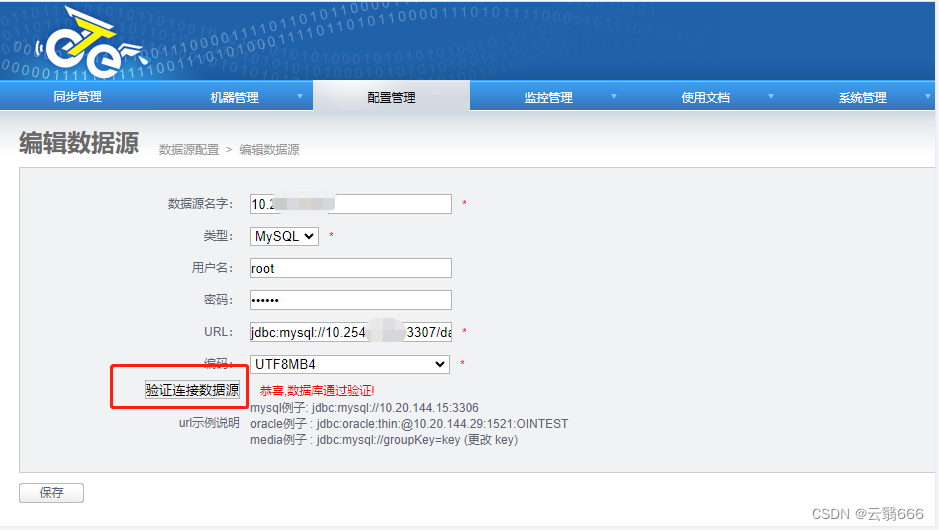
配置完数据源以后,验证链接数据源以后,再进行保存
注意:待同步的源库和目标库,都是需要在此处进行配置的
4.2、数据表配置
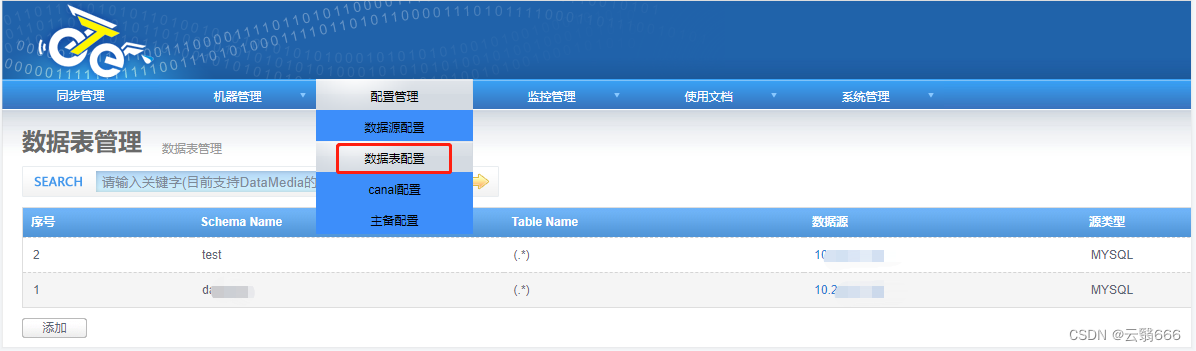
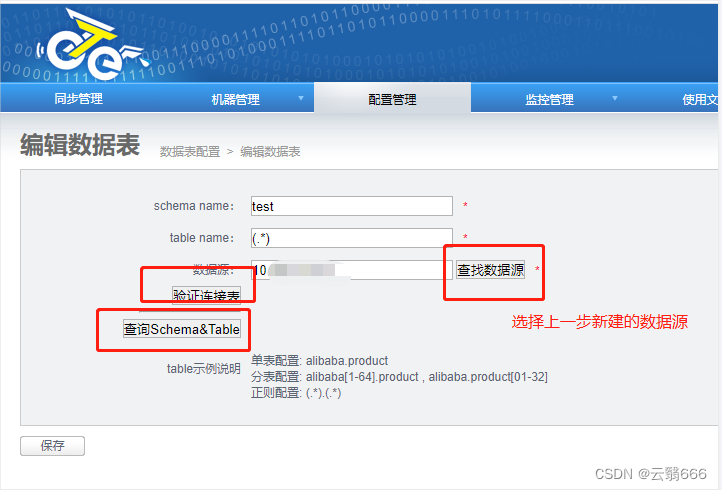
上图示例中,表示的是同步 源库地址(替换成自己的地址) 中test库下的所有的表
注意:源库和目标库的表同步规则,都需要在此处进行配置
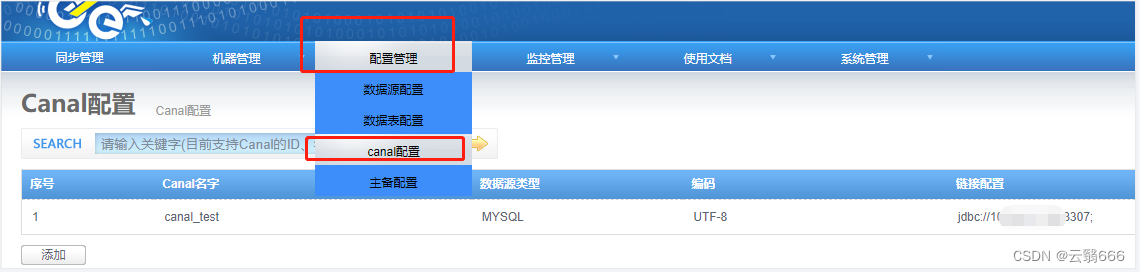
4.3、canal配置
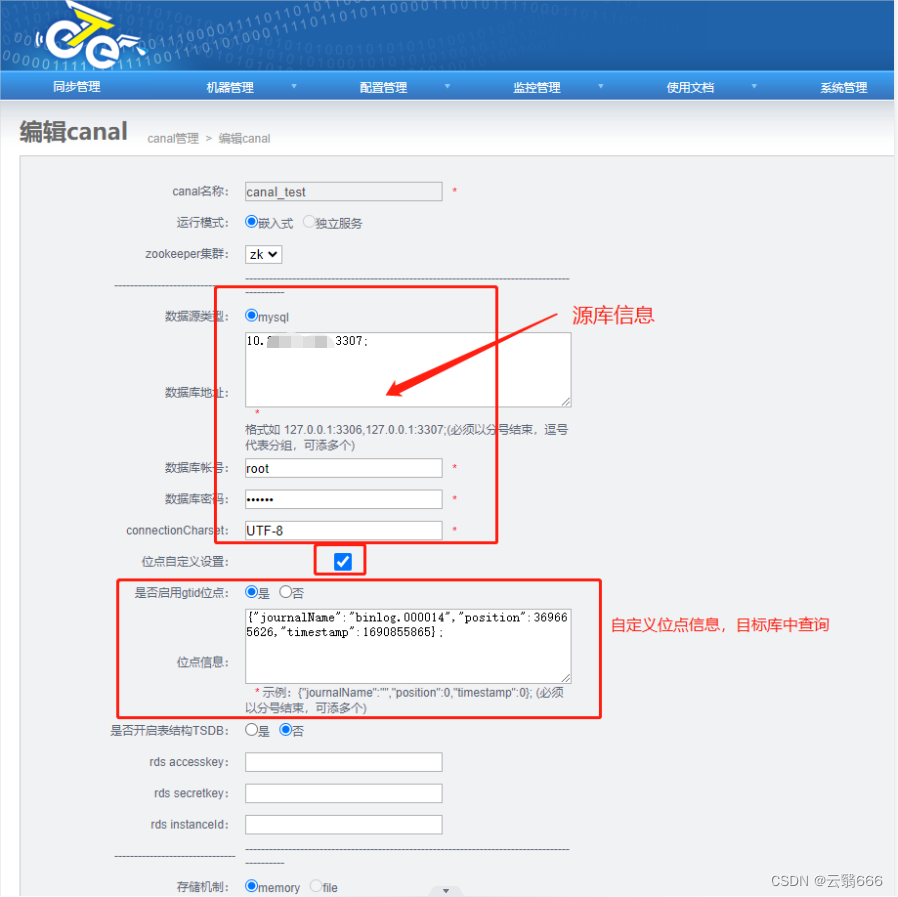
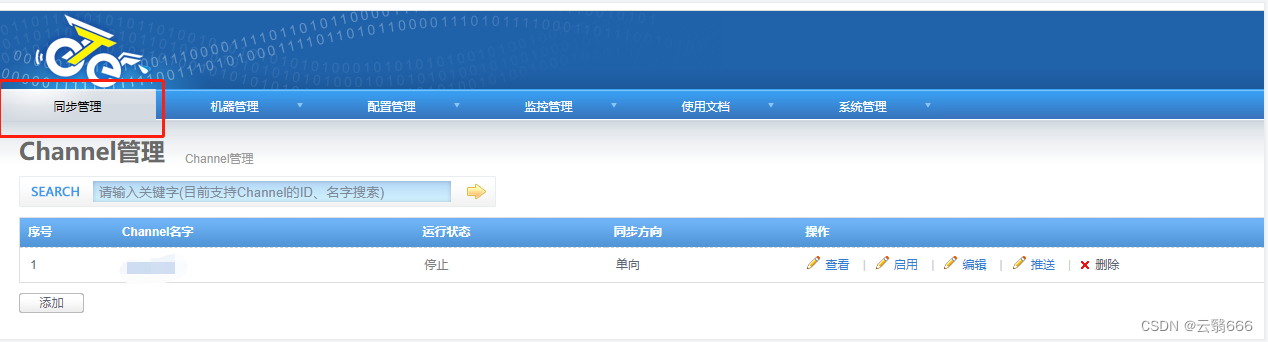
4.4、channel配置
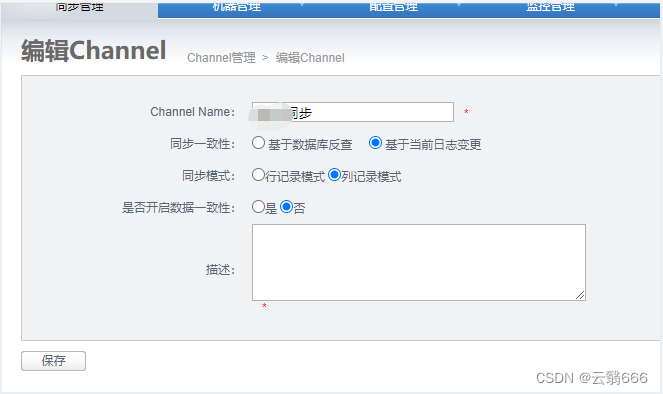
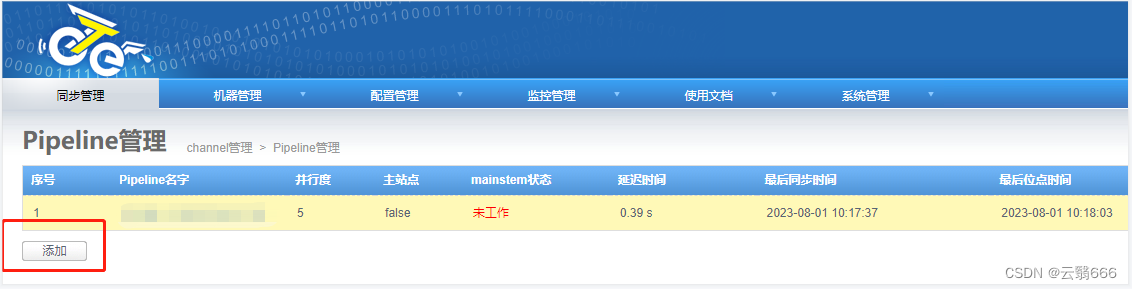
4.5、pipline配置
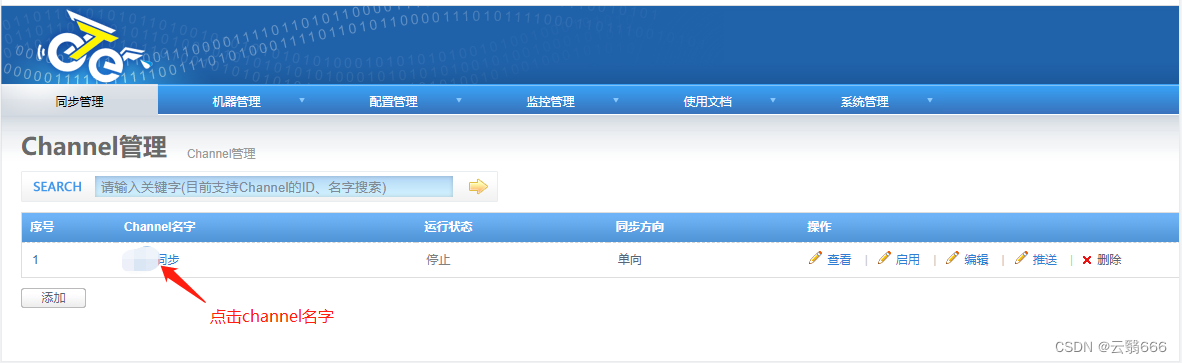
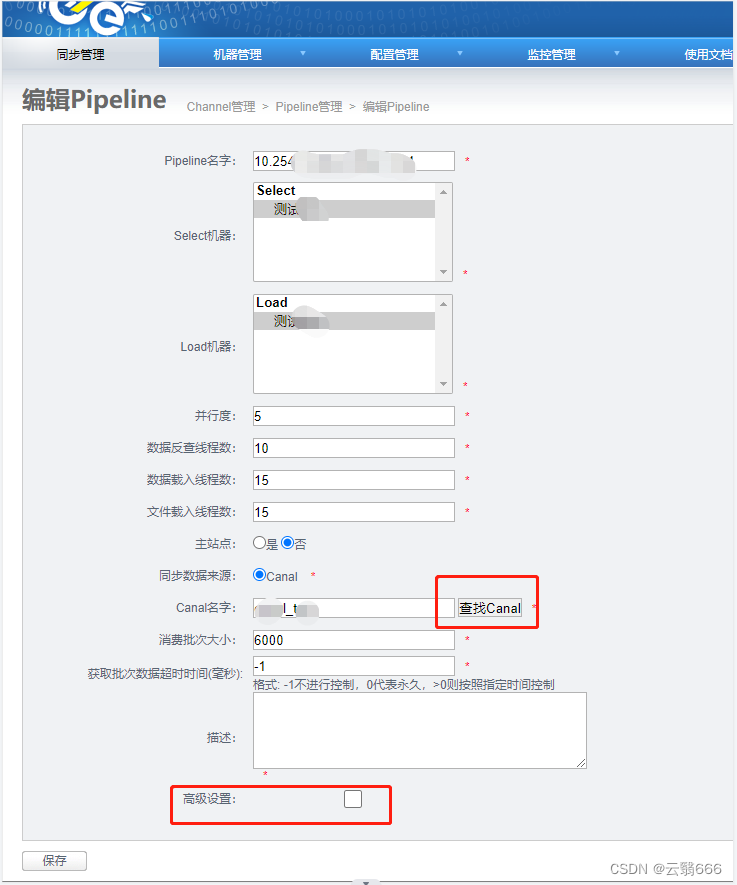
高级设置中,注意以下几个参数:

4.6、添加同步映射规则
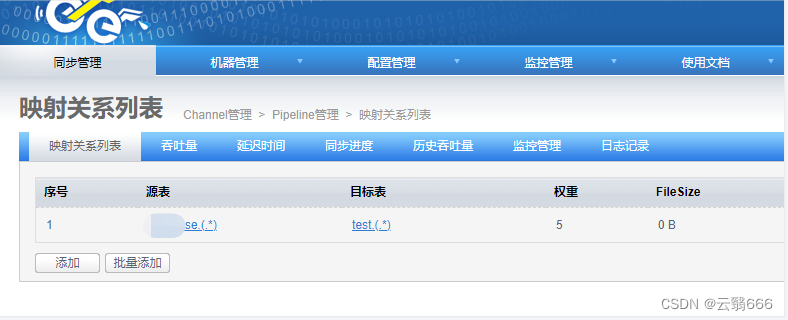

源数据表和目标数据表的选择,选择的是4.2中新建的数据表
注意,如果是mysql到mysql ,两个白方框里面什么都不用写
4.7、启动&&检查
启动channel,是的运行状态变为运行
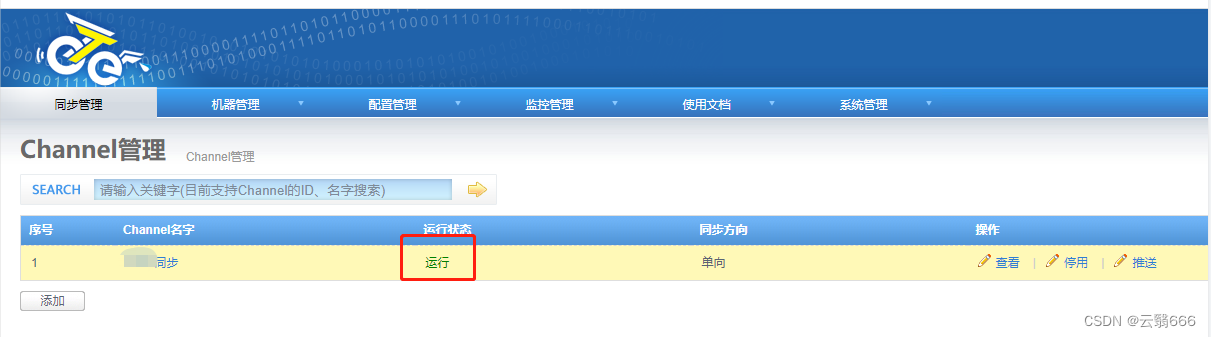
检查Pipeline是否正常


4.8、同步验证
在源数据库中,增加数据,然后会同步到目标库对应的表中

















 6890
6890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









