







建好的代码如下
val result1 =sparksession.sql("select dxkk")//假设这个sql很耗时,1h
val executorBalanced = new BalancedClickhouseDataSource(jdbcLink, properties)
val executorConn = executorBalanced.getConnection.asInstanceOf[ClickHouseConnectionImpl]
//写入clickhouse
properties.put("driver",driver)
properties.put("socket_timeout","300000")
properties.put("rewriteBatchedStatements","true")
properties.put("batchsize","200000")
properties.put("numPartitions","5")
dropPartitons(executorConn,table1,getAfterDay(Day, -3))
dropPartitons(executorConn, table1, Day)
//注意这个就是罪魁祸首
print(result1.count())
result1.write.mode("append").jdbc(jdbcLink, table1, properties)
注意上面的result.count就是耗时的罪魁祸首,有count时候,sparkUI的stage图如下:
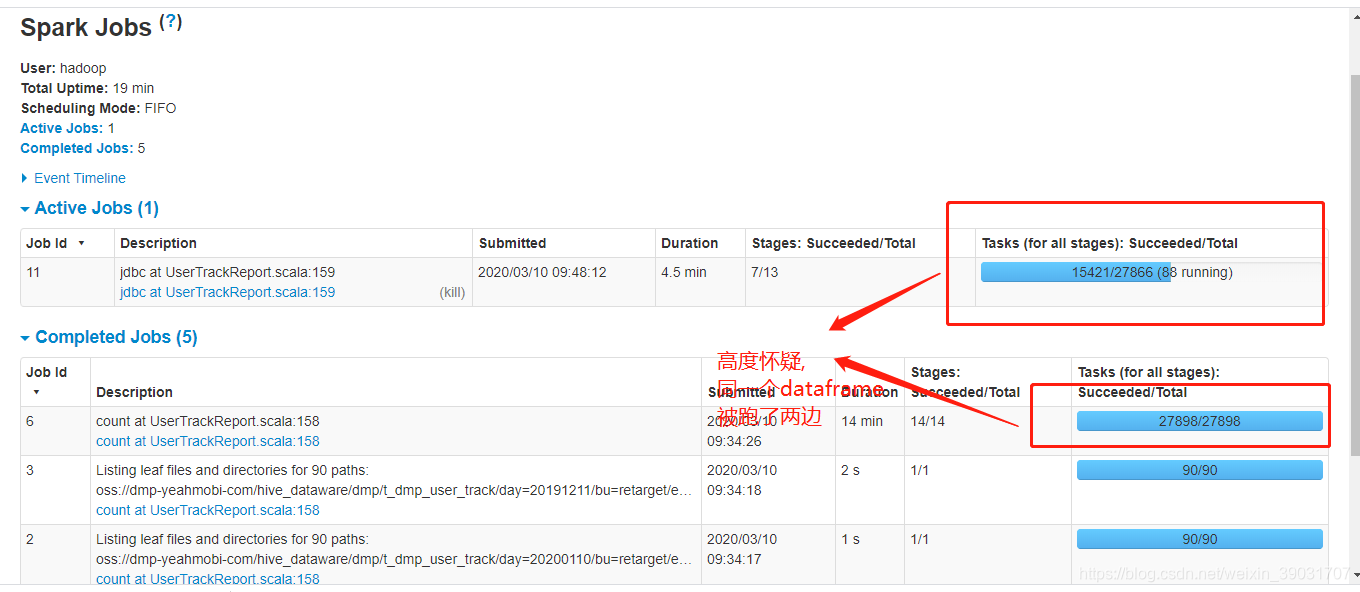
把count去掉后,图如下:
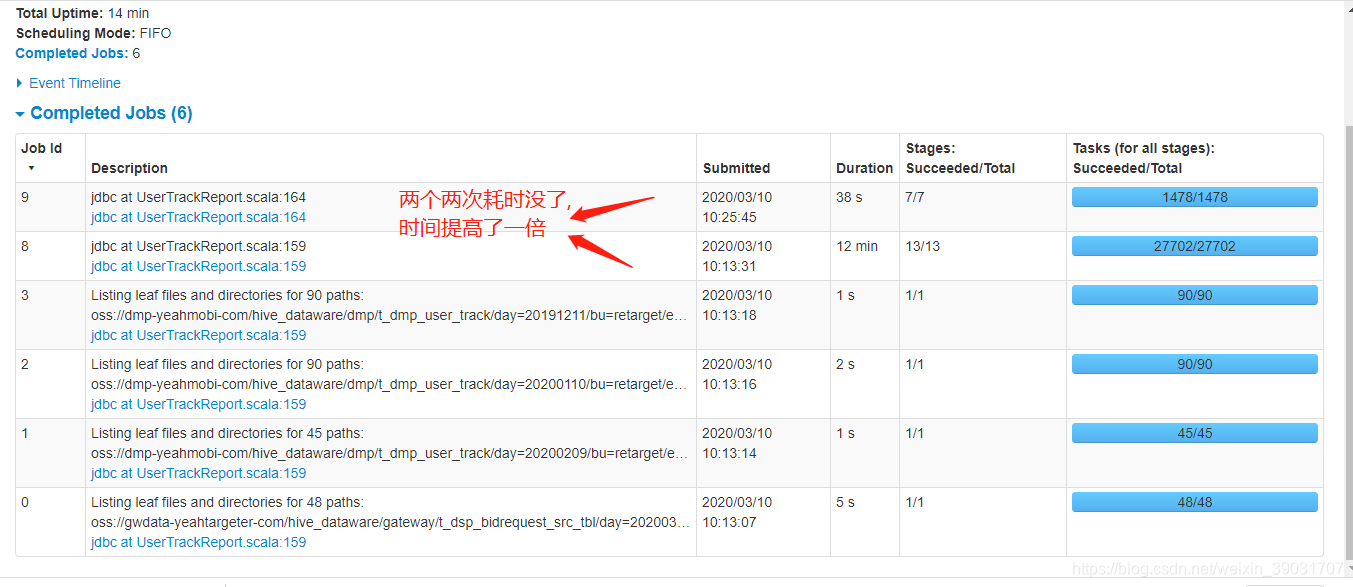
sql只被执行了一次,耗时没了,
解决方案1.把cunt去掉
解决方案2.给result上就爱presist做持久化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









