



 本文介绍了如何选择适合口语练习的剧集,详细讲解了如何从字幕库获取和处理瑞克和莫蒂的字幕文件,包括使用mkvtoolnix提取字幕,用Python脚本去除帧数、时间轴和空行,并在Word中录制宏统一格式。最后,建议如何利用抓取的字幕和音频进行有效的口语练习。
本文介绍了如何选择适合口语练习的剧集,详细讲解了如何从字幕库获取和处理瑞克和莫蒂的字幕文件,包括使用mkvtoolnix提取字幕,用Python脚本去除帧数、时间轴和空行,并在Word中录制宏统一格式。最后,建议如何利用抓取的字幕和音频进行有效的口语练习。

通过阅读剧本或者字幕来练习口语是一个有趣且高效的方法,我选择的是瑞克和莫蒂,下文记录一下全过程。
一、选它的理由:
1、对话密集,短对话多
这点很重要,因为这是练习口语的需要。我并不想向过去一样背诵新概念或者是长篇的英文课文,所以排除叙述性太强的例如BBC或者英文纪录片。
有一些剧的特点是人物都比较高冷,对话不多,而我希望在我一集一集的练习时间中人物最好无时无刻不再说话,这样 瑞克和莫蒂 每集二十分钟的连贯对话就是非常好的选择。当然如 老友记 或者其他比较生活化的剧集也十分不错。
2、故事性强,可以N刷
要拿一部剧的剧本来作为练习素材,喜欢这部剧是非常重要的。最好是平常都有n刷的剧再好不过。在通读完字幕后再刷完全可以找生肉练习听力。
二、如何获取字幕文件
1、字幕库直接搜索
字幕库
这个网站的字幕我感觉是比较齐全的了,可以看到上面的字幕文件,有以下两种,.srt就是从MKV视频中提取出来的字幕格式,.ass是外挂字幕的格式。

.srt格式如下:

.ass格式如下:

我后续所有的字幕文件都使用的是.srt格式的,因为.srt的格式比较方便写个脚本处理,而且.ass文件可以从网页上一键转换成.srt文件。
字幕格式转换
2、从mkv格式视频中抓取字幕
即便是上面提到的字幕库,在上面搜索瑞克和莫蒂也缺少第三季的字幕素材(现在我已经上传)。遇到这种情况,就需要从mkv视频中抓取字幕。
1)下载mkvtoolnix,
2)打开MKVExtractGUI.2.3.0.0.简体汉化版
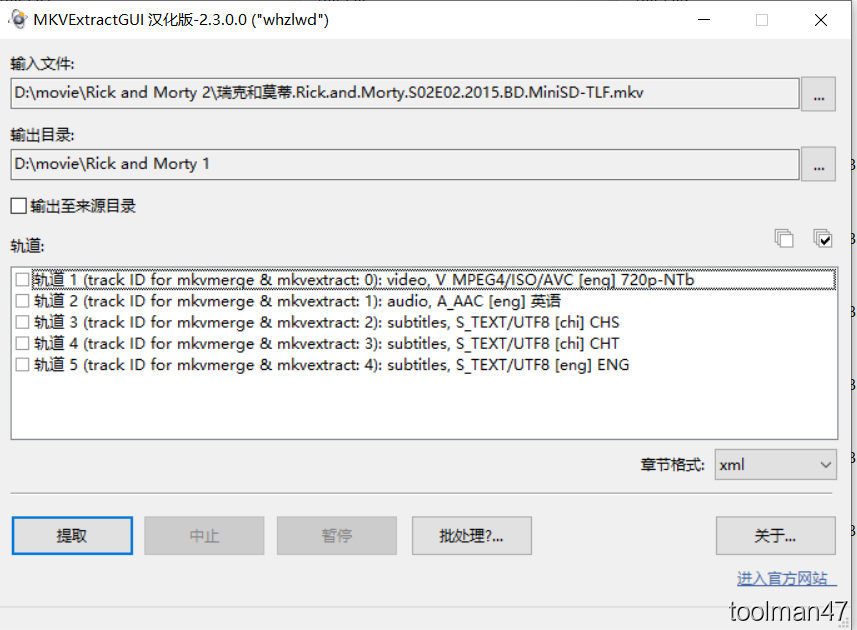
拖入要处理的视频,就可以看到如下分轨,即可提取出字幕文件和音频文件。
ps:如果没有MKVExtractGUI.2这个软件需要单独下载然后拖入mkvtoolnix的文件夹。
pps:当然只需要音频文件的不用这么麻烦,任意格式视频和格式工厂就可以搞定。
三、如何处理字幕文件
1、去掉字幕文件中的帧数、时间轴和空行
由于我也是初次使用python,所以这个小脚本可能写得不太好,但是可以用,每一步骤我都尽力标注了一下方便后面修改:
import os
import re
import numpy as np
path = os.getcwd() # 定位到当前地址
name = 0
for h in os.listdir(path):
if re.match('.*.srt', h): #匹配剧本文件
name = name + 1
orifile = open ( h ,'r+') #encoding取决于文档编码格式
insfile = open (str(name) + '.txt' , 'w+') #由于这里原文档编码格式不同的话写入会乱码,所以建立临时文档
#outfile = open ('S03','a') #都输出到同一个文档内
if name < 10:
outfile = open ('S03E0' + str(name) + '.txt','a')
else:
outfile = open('S03E' + str(name) + '.txt', 'a')
content = orifile.read()
insfile.seek(0,0)
insfile.write('\n'+content)
#locate = re.search('1',content) #当文档前有多行空行时需要定位,一般不用
#coordinate = locate.start() - 1
#insfile.seek(coordinate,0)
insfile.seek(0, 0)
i = 0 #每隔固定行输出一行
j = 0 #多行错误
for line in insfile.readlines():
if line != '\n' and j == 1: #空行'\n' #当前帧多行
i = i - 1
print(line) #检查多行错误,有必要要的继续加进去
print(h)
#outfile.write(line)
j = 0
i = i + 1
if i == 5 : #每隔固定行输出一行
if line != '\n': #避免少行错误
outfile.write(line)
i = 0
j = 1 #避免多行错误
else: #当前帧少行
i = 1
j = 0 2、在word中录制宏来统一处理格式
这里我就不赘述了。
四、进行口语练习
通过上述的方法可以抓取其他你喜欢的剧集的字幕和音频。
现在拿到了剧本和音频,就可以跟读,角色扮演来练习口语,我的建议是把剧本打印出来,开通一个喜马拉雅或者其他FM的主播号,将音频做成专辑传上去,在实际练习时比较好控制进度条,语速,尤其是这种听书软件的+15s,-15s设计很好控制播放进度。需要注意的是版权问题,一定要上传成私密专辑。



















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









