












写个小应用,记得把settings里面的改成Flase
ROBOTSTXT_OBEY = False# -*- coding: utf-8 -*-
import scrapy
class SiSpider(scrapy.Spider):
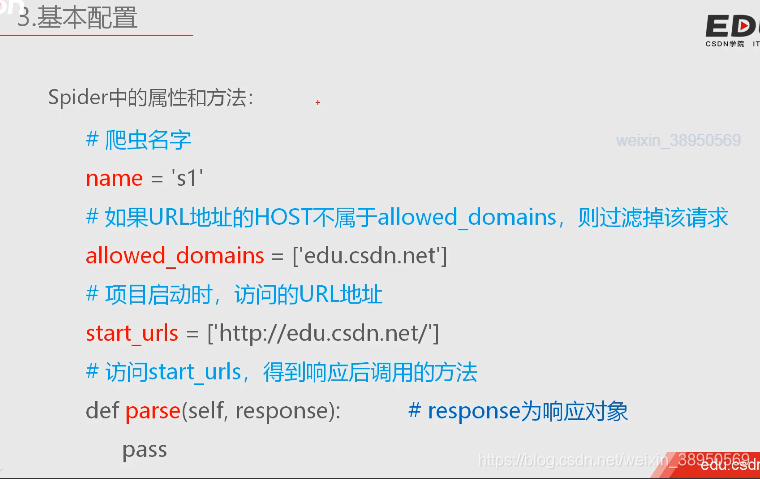
#文件的名字 要和这个name值对应
name = 'si'
allowed_domains = ['blog.youkuaiyun.com']
# start_urls = ['http://blog.youkuaiyun.com/']
def start_requests(self):
yield scrapy.Request(
#这里是url,不是urls
url='http://blog.youkuaiyun.com/',
callback=self.parse2
)
def parse2(self, response):
print('+'*60)
#extract()得到里面的内容
print(response.xpath('//div[@class="nav_com"]//li/a/text()').extract())
print('+' * 60)
现在使用 DownloaderMiddleware 进行装饰,添加 headers
首先:在settings文件中,将这段话取消注释
#开启DOWNLOADER_MIDDLEWARES中间件
DOWNLOADER_MIDDLEWARES = {
's1.middlewares.S1DownloaderMiddleware': 543,
}在middlewares.py文件中找到项目名+DownloaderMiddleware的类,重写下面process_request函数
#记得导包
from scrapy.http.headers import Headers
from s1 import user_agent
import urllib.request as u
#一般重写这里
def process_request(self, request, spider):
#这里是bytes类型,所以要导入Headers的包
request.headers = Headers(
{
'User_Agent': user_agent.get_user_agent_pc(),
}
)
#设置代理IP
request.meta['proxy'] ='http://'+ ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=06b5d4a85d10b5cbe9db1e5a3b9fa2e1&sep=4').read().decode('utf-8').strip()
# print('IP:'+request.meta['proxy'])
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
调试的时候一直要在控制台写scrapy crawl 项目名,比较烦,可以在spiders下创建一个文件,里面写:
from scrapy import cmdline
cmdline.execute('scrapy crawl si'.split())别忘debug加入这个文件,然后就OK了,不应在一直写命令行了。。
继续pipelines(管道文件)的配置:
首先将settings中的这里解除注释
ITEM_PIPELINES = {
's1.pipelines.S1Pipeline': 300,
}
修改上面si(项目文件)文件中代码:
def parse2(self, response):
print('+'*60)
#得到里面的内容
data = response.xpath('//div[@class="nav_com"]//li/a/text()').extract()
item= {}
item['data'] = data
#yield如果是Request对象,就会把这个对象交给schedllner(调度器)
#如果yield的是字典,就会交给管道文件
yield item
print('+' * 60)继续修改pipelines.py文件中的代码:
class S1Pipeline(object):
def process_item(self, item, spider):
print('='*100)
#item这里是字典,我们将其改为字符串,逗号隔开保存到本地
print(item)
data = item['data']
save_data = ','.join(data)
with open('data.text', 'w', encoding='utf-8') as da:
da.write(save_data)
return item

















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









