







 本文详细介绍了Hive中的Lag和Lead分析函数,这两种函数可以高效地在查询中获取同一字段的前N行和后N行数据,替代了表自联接,提高了数据统计分析的效率。通过具体实例,展示了如何使用Lag和Lead函数进行数据处理。
本文详细介绍了Hive中的Lag和Lead分析函数,这两种函数可以高效地在查询中获取同一字段的前N行和后N行数据,替代了表自联接,提高了数据统计分析的效率。通过具体实例,展示了如何使用Lag和Lead函数进行数据处理。
介绍:
Hive的分析函数又叫窗口函数,在oracle中就有这样的分析函数,主要用来做数据统计分析的。
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率,其中over()表示当前查询的结果集对象,括号里面的语句则表示对这个结果集进行处理。
函数介绍
LAG
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
参数1为列名,参数2为往上第n行(可选,默认为1),参数3为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
LEAD
与LAG相反
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
参数1为列名,参数2为往下第n行(可选,默认为1),参数3为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL
1、创建元数据 lag_lead.txt 文件
以"\t"分隔
slm 2018-12-26 01:10:00 1
slm 2018-12-26 02:11:00 2
slm 2018-12-26 03:22:00 3
slm 2018-12-26 04:10:00 4
slm 2018-12-26 05:10:00 5
hh 2018-12-26 01:10:00 1
hh 2018-12-26 02:11:00 2
hh 2018-12-26 03:22:00 3
hh 2018-12-26 04:10:00 4
hh 2018-12-26 05:10:00 5
2、把元数据传到集群中
3、创建hive表
create table leg_lead(
name string,
time string,
id string
) row format delimited fields terminated by '\t';
4、加载数据到hive表
load data local inpath '/home/hadoop/lag_lead.txt' into table leg_lead;
5、lag使用
select name, time ,lag(time,1) over(partition by name order by time asc ) as rtime from leg_lead;
查询结果 :
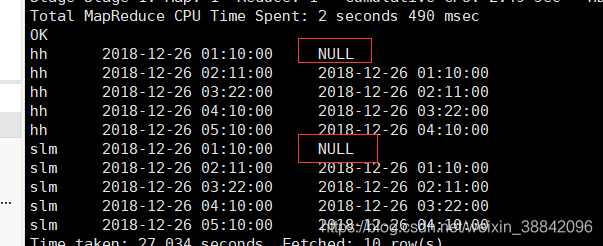
上面lad函数中默认没有的值为null
6、lead 使用
select name, time ,lead(time,2) over(partition by name order by time asc ) as rtime from leg_lead;
查询结果
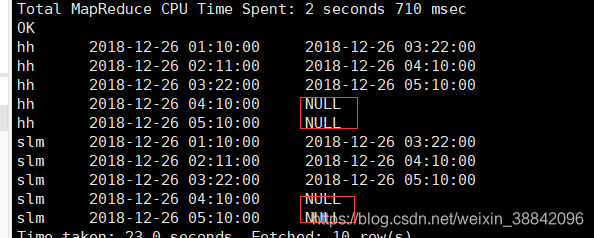
上面lead函数默认值为null

















 4465
4465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









