







ElasticSearch简介
Elasticsearch 基于java,是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
ElasticSearch的适用场景
传统的关系性数据库MySQL、oracle、PostgreSQL更擅长的是事务类型的操作,可以确保数据的安全和一致性;如果是有事务要求,如商品的下单支付等业务操作,无疑使用MySQL。而ES更擅长的是海量数据的搜索,分析和计算;如果是复杂搜索,无疑可以使用Elasticsearch。
ElasticSearch安装
elasticSearch下载
官网地址:https://www.elastic.co/cn/downloads/
单机版安装
因为ElasticSearch不支持Root用户直接操作,因此我们需要创建一个elsearch用户
# 添加新用户
useradd elsearch
# 创建一个soft目录,存放下载的软件
mkdir /soft
# 进入,然后通过xftp工具,将刚刚下载的文件拖动到该目录下
# 推荐一个好用的终端工具termius,sftp功能特别好用
cd /soft
# 解压缩
tar -zxvf elasticsearch-7.9.1-linux-x86_64.tar.gz
#重命名
mv elasticsearch-7.9.1/ elsearch因为刚刚我们是使用root用户操作的,所以我们还需要更改一下/soft文件夹的所属,改为elsearch用户
chown elsearch:elsearch /soft/ -R然后在切换成elsearch用户进行操作
# 切换用户 su - elsearch 然后我们就可以对我们的配置文件进行修改了
# 进入到 elsearch下的config目录 cd /soft/elsearch/config
#打开配置文件
vim elasticsearch.yml
#设置ip地址,任意网络均可访问
network.host: 0.0.0.0
vim config/elasticsearch.yml
修改项为:
network.host: 0.0.0.0
http.port: 9200
同时我们可以修改它的发布地址:network.publish_host: 要发布的IP地址
修改完成之后重启es发现我们使用浏览器仍然不能访问我们的es服务,通过查看,原来是阿里云默认没有对外开放端口,在阿里云控制台的安全组配置中添加新的配置。
重启之后发现还是放不了,这个时候忍不住说一声万恶的服务为什么还访问不了!!!
再次检查发现防火墙的原因。打开防火墙端口!打开防火墙端口!打开防火墙端口!重要的事情说三遍!
添加的命令如下 firewall-cmd --zone=public --add-port=9200/tcp
(防火墙的几个简单命令:启动: systemctl start firewalld 查看状态: systemctl status firewalld
停止: systemctl disable firewalld 禁用: systemctl stop firewalld)在Elasticsearch中如果,network.host不是localhost或者127.0.0.1的话,就会认为是生产环境,会对环境的要求比较高,我们的测试环境不一定能够满足,一般情况下需要修改2处配置,如下:
# 修改jvm启动参数
vim conf/jvm.options
#根据自己机器情况修改
-Xms128m
-Xmx128m然后在修改第二处的配置,这个配置要求我们到宿主机器上来进行配置
# 到宿主机上打开文件
vim /etc/sysctl.conf
# 增加这样一条配置,一个进程在VMAs(虚拟内存区域)创建内存映射最大数量
vm.max_map_count=655360
# 让配置生效
sysctl -p启动ElasticSearch
首先我们需要切换到 elsearch用户
su - elsearch然后在到bin目录下,执行下面
# 进入bin目录
cd /soft/elsearch/bin
# 后台启动
./elasticsearch -d
或者
# 正常启动
./elasticsearch访问ip+9200
如果出现了下面的信息,就表示已经成功启动了
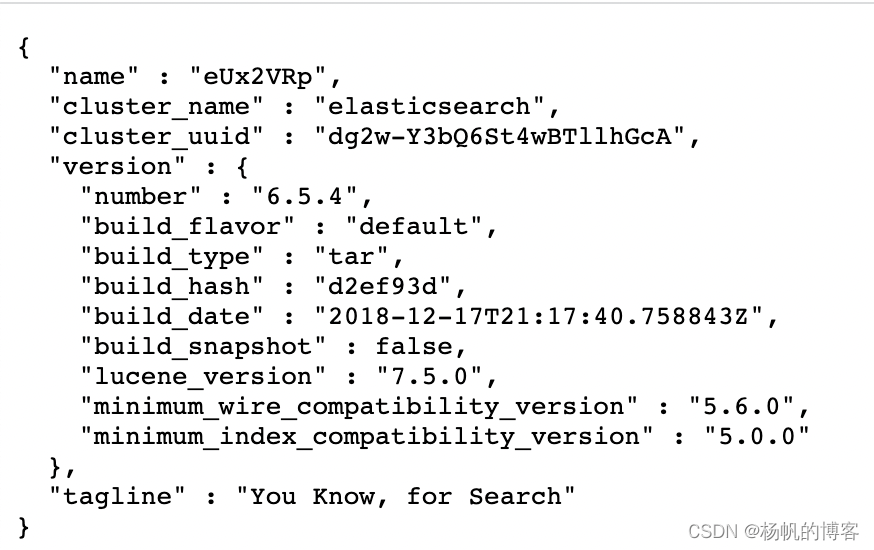
ElasticSearchHead可视化工具
通过chrome插件安装,在google浏览器的应用市场里搜索Multi Elasticsearch Head安装即可
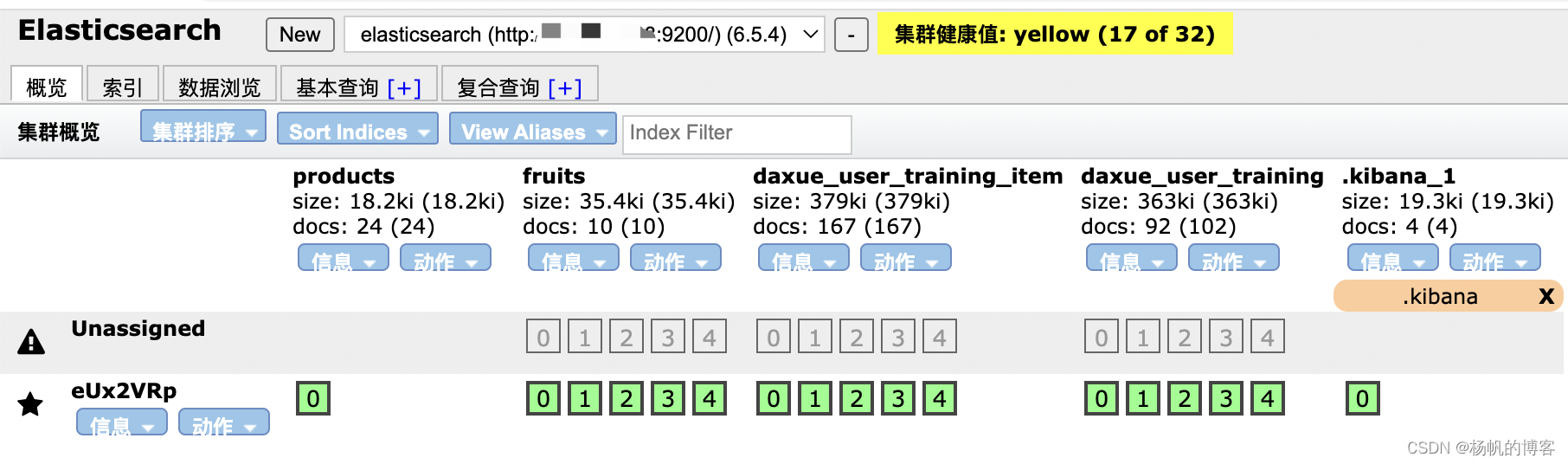
ElasticSearch中的基本概念
索引
- 引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。
- 可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。
- Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
文档
- 存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
- Elasticsearch和MongoDB中的文档类似,都可以有不同的结构,但Elasticsearch的文档中,相同字段必须有相同类型。
- 文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。 每个字段的类型,可以是文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数 组。
映射
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做 映射(mapping)。一般由用户自己定义规则。
文档类型
- 在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评 论。
- 每个文档可以有不同的结构。
- 不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫title的字段必须具有相同的类型。
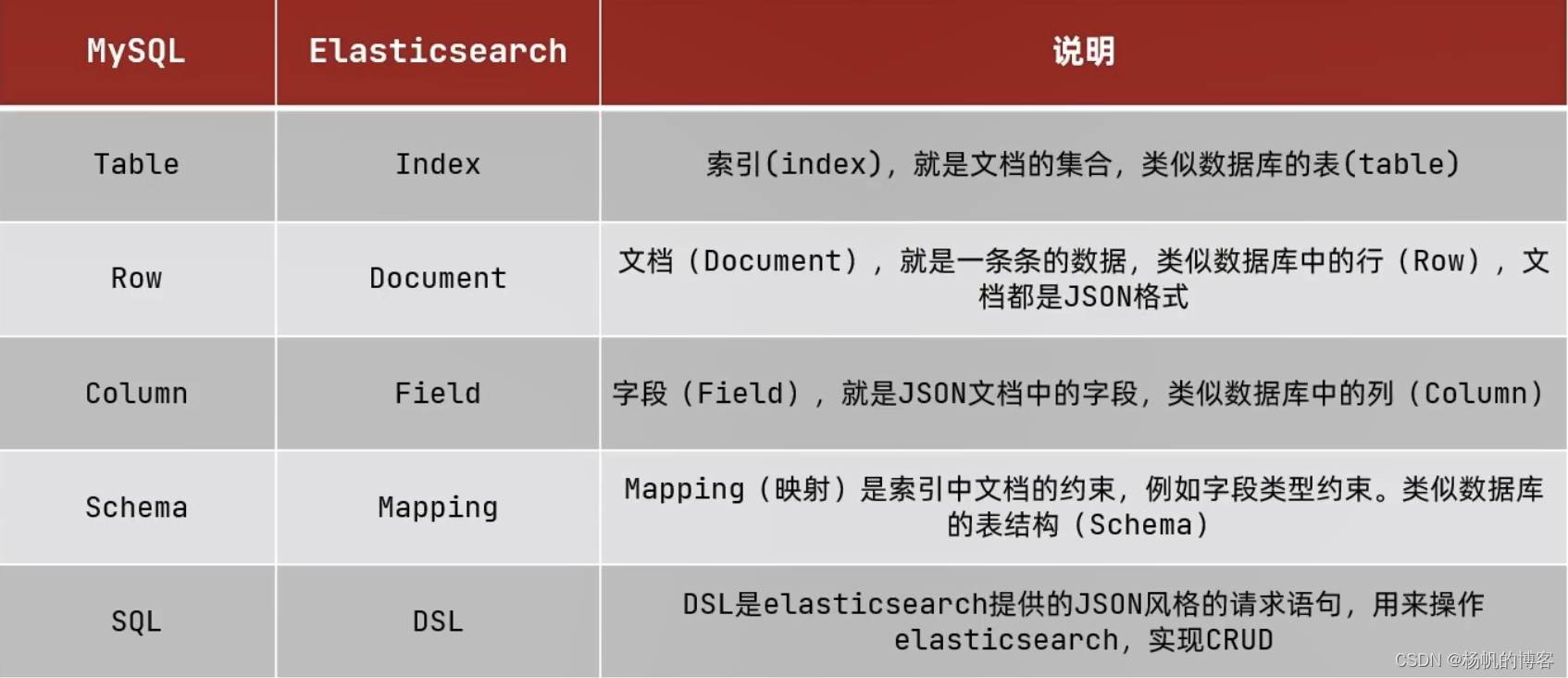
ElasticSearch和Mysql的对比
Restful API
在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
创建空索引
PUT /fruits
{
"settings": {
"index": {
"number_of_shards": "2", #分片数
"number_of_replicas": "0" #副本数
}
}
}
删除索引
#删除索引
DELETE /fruits
{
"acknowledged": true
}
创建映射文件
PUT fruits/
{
"properties": {
"title": {
"type": "text"
},
"price": {
"type": "long"
},
"description": {
"type": "text"
}}
}
获取映射Mapping文件
GET fruits/_mapping
"mappings": {
"fruit": {
"properties": {
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"doc": {
"properties": {
"id": {
"type": "text"
},
"price": {
"type": "long"
},
"title": {
"type": "text"
}
}
},
"id": {
"type": "text"
},
"price": {
"type": "long"
},
"title": {
"type": "text"
}
}
}
}
开启某个字段的Fielddata属性
POST /fruits/_mapping
{
"properties": {
"email": {
"type": "long",
"fielddata": true
}
}
}
插入数据
{"index":{"_index":"fruits","_type":"fruit"}}
{"id":"1001","title":香蕉","price":7500,"description":"香蕉很甜"}
更新数据—全量更新
put /fruits/fruit/1005
{
"id": "1005",
"title": "西红柿",
"price": 6000,
"description": "你以为你还是水果啊"
}
更新数据—增量更新
ElasticSearch查询
结构化查询
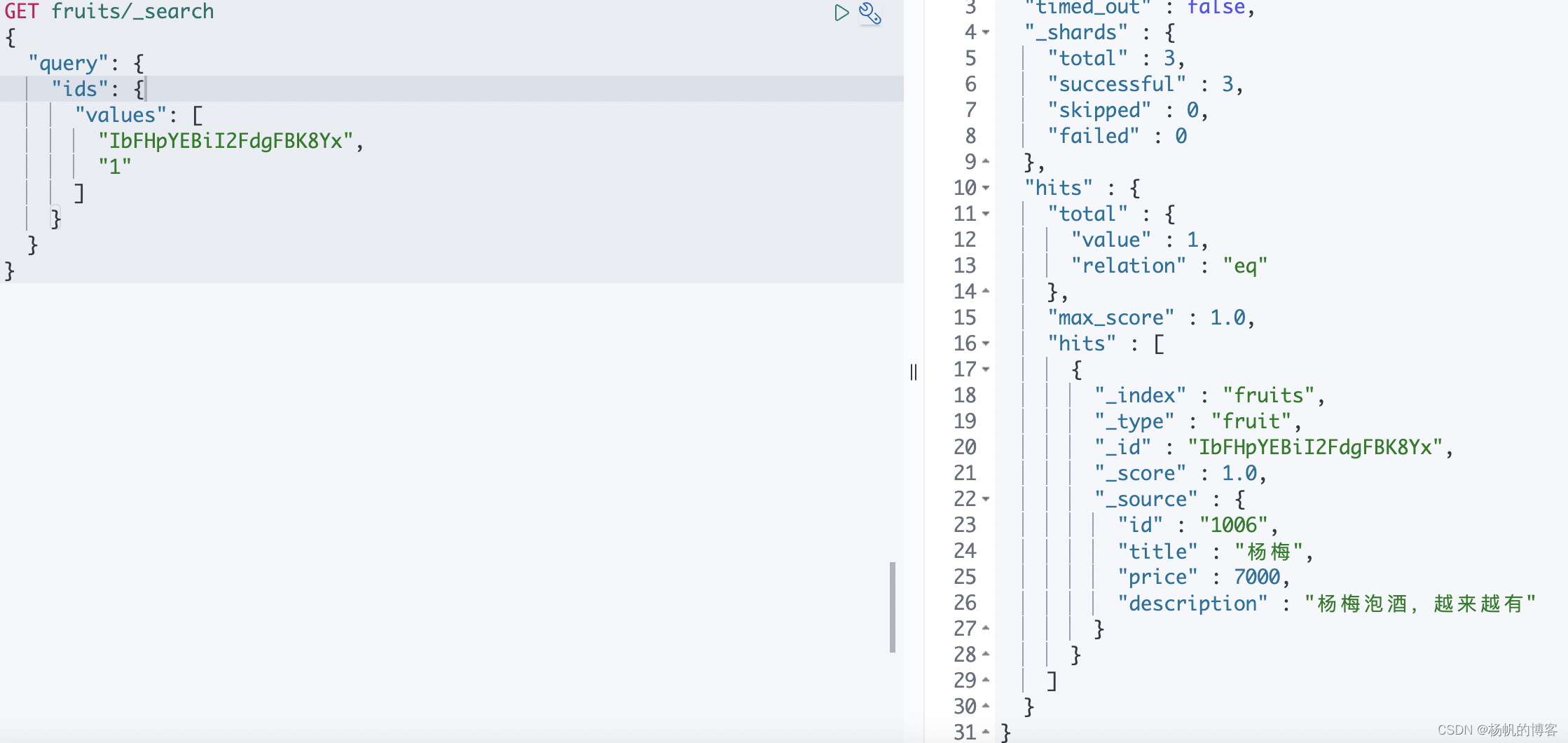
ids 查询
通过文档 id 进行查询返回,这里的 id 为文档中的 _id。
GET fruits/_search
{
"query": {
"ids": {
"values": [
"IbFHpYEBiI2FdgFBK8Yx",
"1"
]
}
}
}
term查询
term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型);需要注意的是term只能精确匹配一个单词,搜索前不会对搜索词进行分词拆解。
GET fruits/_search
{
"query": {
"term": {
"title.keyword": {
"value": "西红柿"
}
}
}
}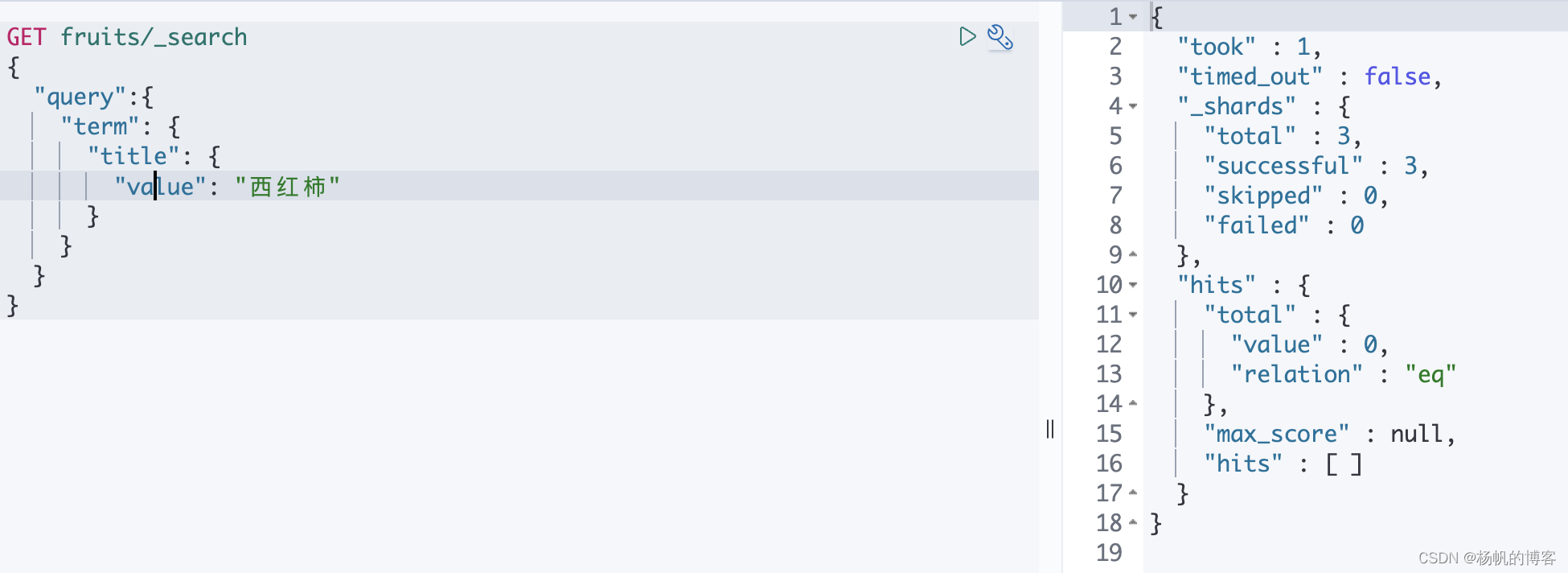
查询的结果如下,明明es中是有这条数据,为什查询不到呢?此时需要注意的是英文中的词和汉语中的词的概念,英文中的词一般指的是两个空格之间的单词,中文的词在es中并非是我们日常的词语而是单个的汉字,因此我们在使用“西红柿”查询时是无法查询到的。
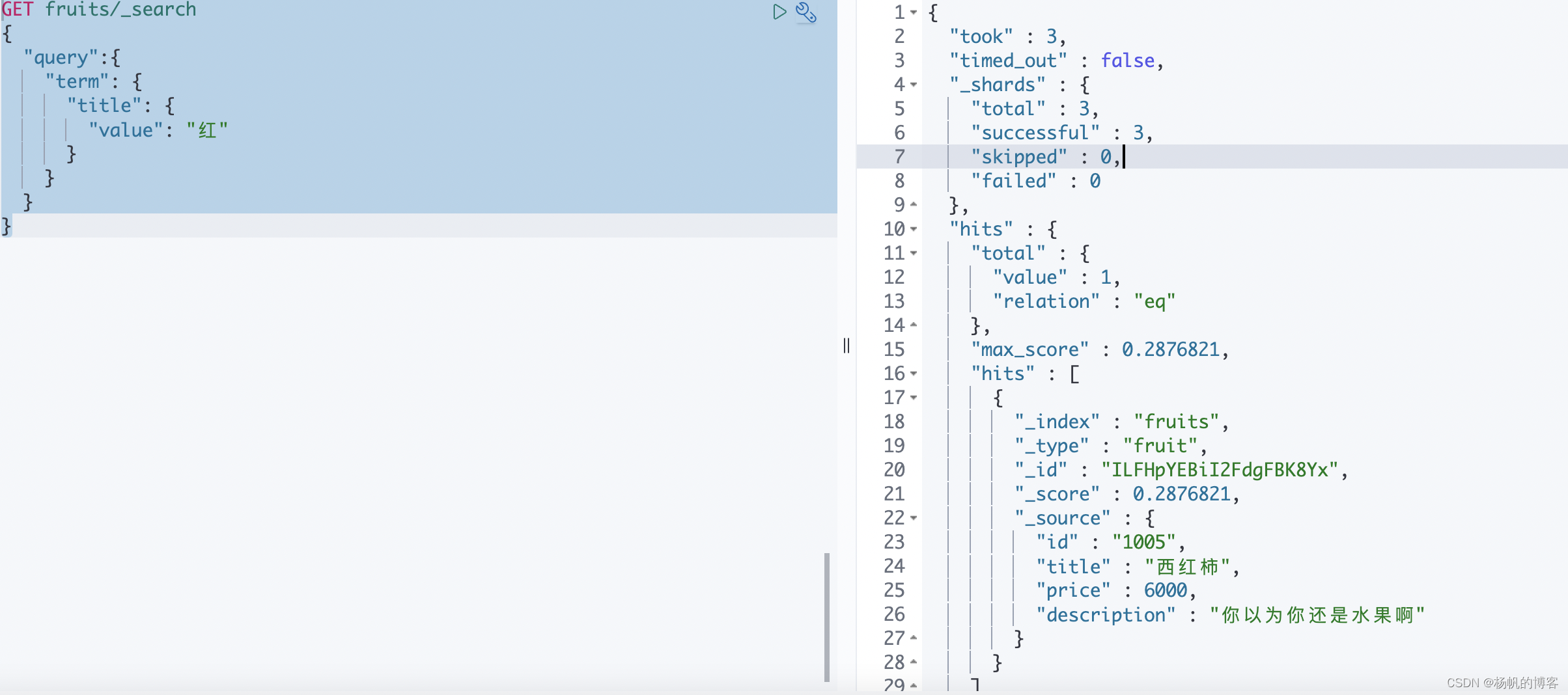
下面使用单个词进行匹配,是可以查询到的
GET fruits/_search
{
"query":{
"term": {
"title": {
"value": "红"
}
}
}
}
如果我们真的有多个词进行匹配的场景可以考虑使用match_phrase 这个后面有专门的介绍
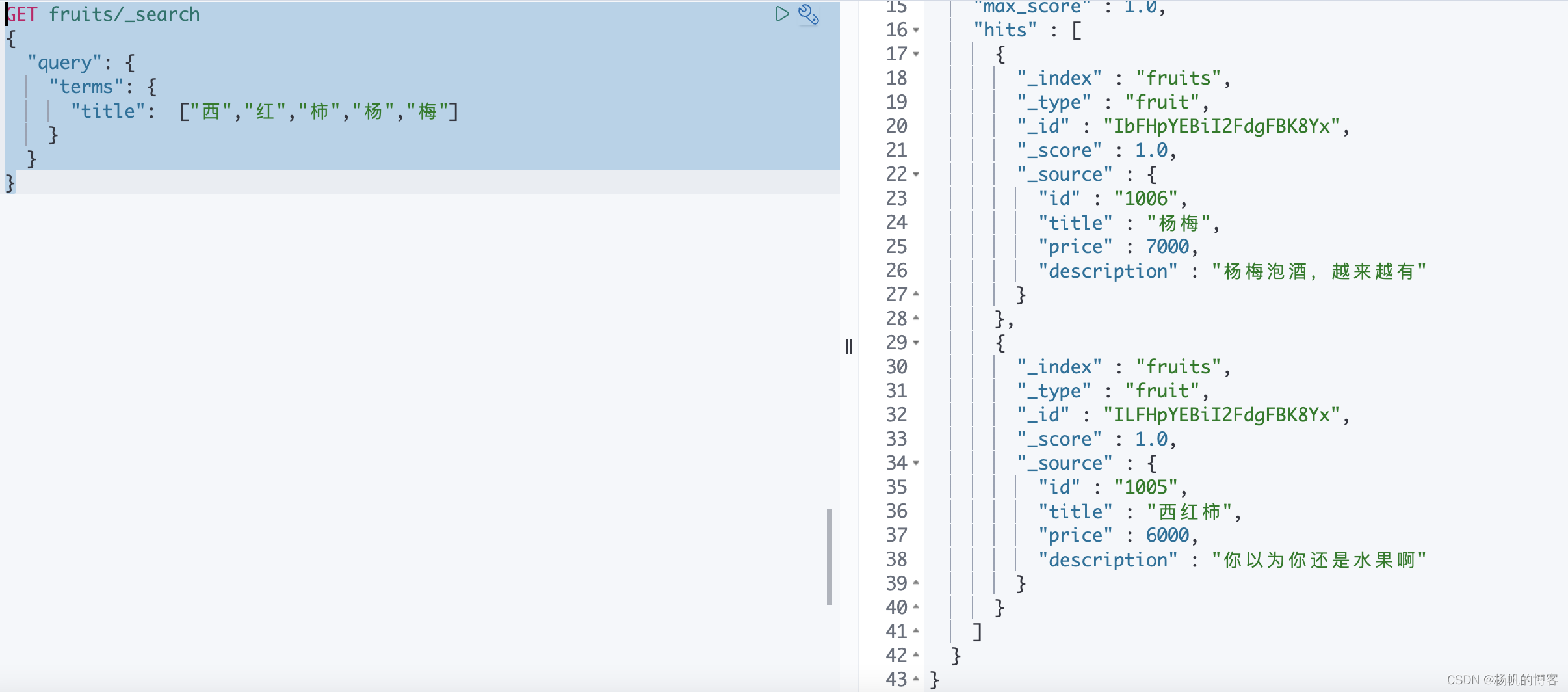
terms查询
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件,terms里的[]多个是或者的关系,只要满足了其中一个词就可以了。 如果某个字段指定了多个值,那么文档需要一起去做匹配,跟mysql中的in查询类似
GET fruits/_search
{
"query": {
"terms": {
"title": ["西","红","柿","杨","梅"]
}
}
}
range查询
range 过滤允许我们按照指定范围查找一批数据,类似于mysql中between and语法及value> 0 and value < 10语法;
范围操作符包含:
- gt : 大于
- gte:: 大于等于
- lt : 小于
- lte: 小于等于
GET fruits/_search
{
"query": {
"range": {
"price": {
"gte": 7500,
"lt": 9000
}
}
}
}exists 查询
exists 查询可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL 条件
GET fruits/_search
{
"query": {
"exists": {
"field": "description"
}
}
}match查询
match进行搜索时,会先进行分词拆分,拆完后,再来匹配。
match 查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match 一下查询字符:
GET fruits/_search
{
"query": {
"match": {
"description": "苹果很脆"
}
}
}如果用match 下指定了一个确切值,在遇到数字,日期,布尔值或者not_analyzed 的字符串时,它将为你搜索你给定的值:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
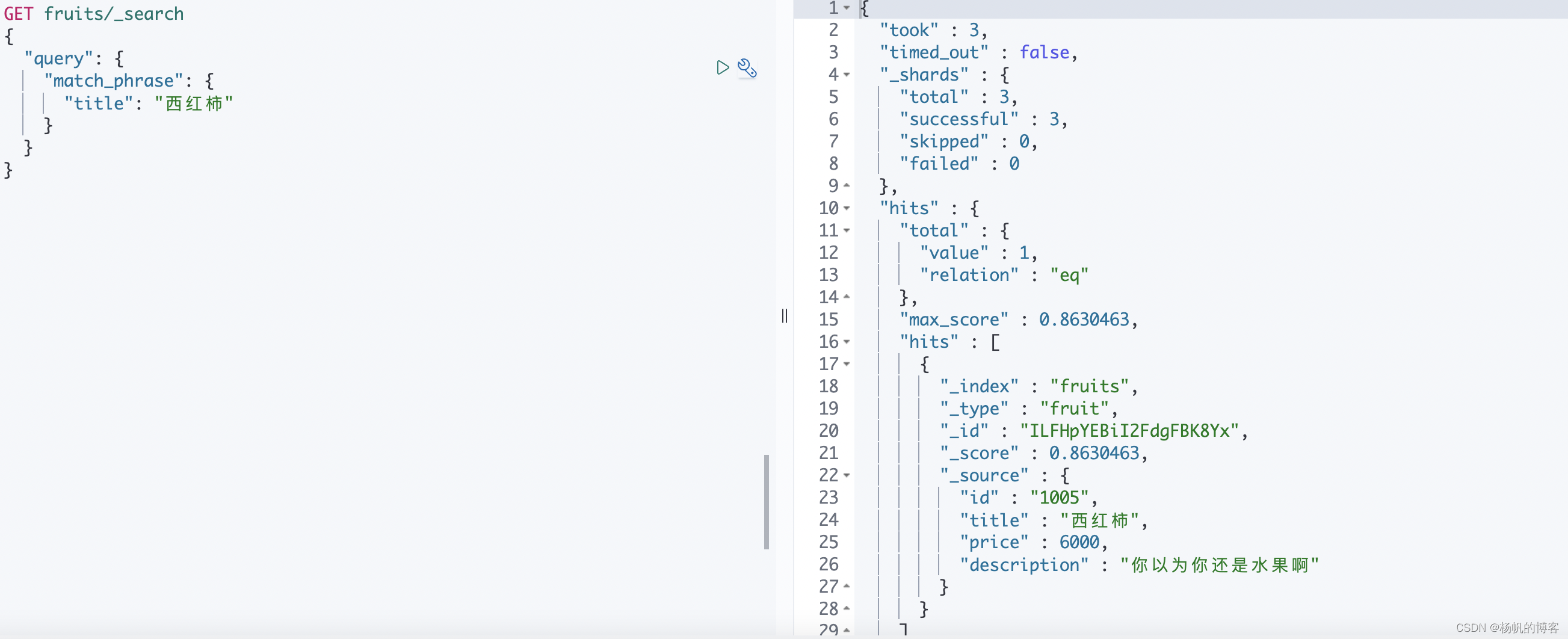
{ "match": { "tag": "full_text" }}match_phrase
match_phrase 称为短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致,这倒是有点前mysql中的like的前后%的形式:%关键字%
GET fruits/_search
{
"query": {
"match_phrase": {
"title": "西红柿"
}
}
}
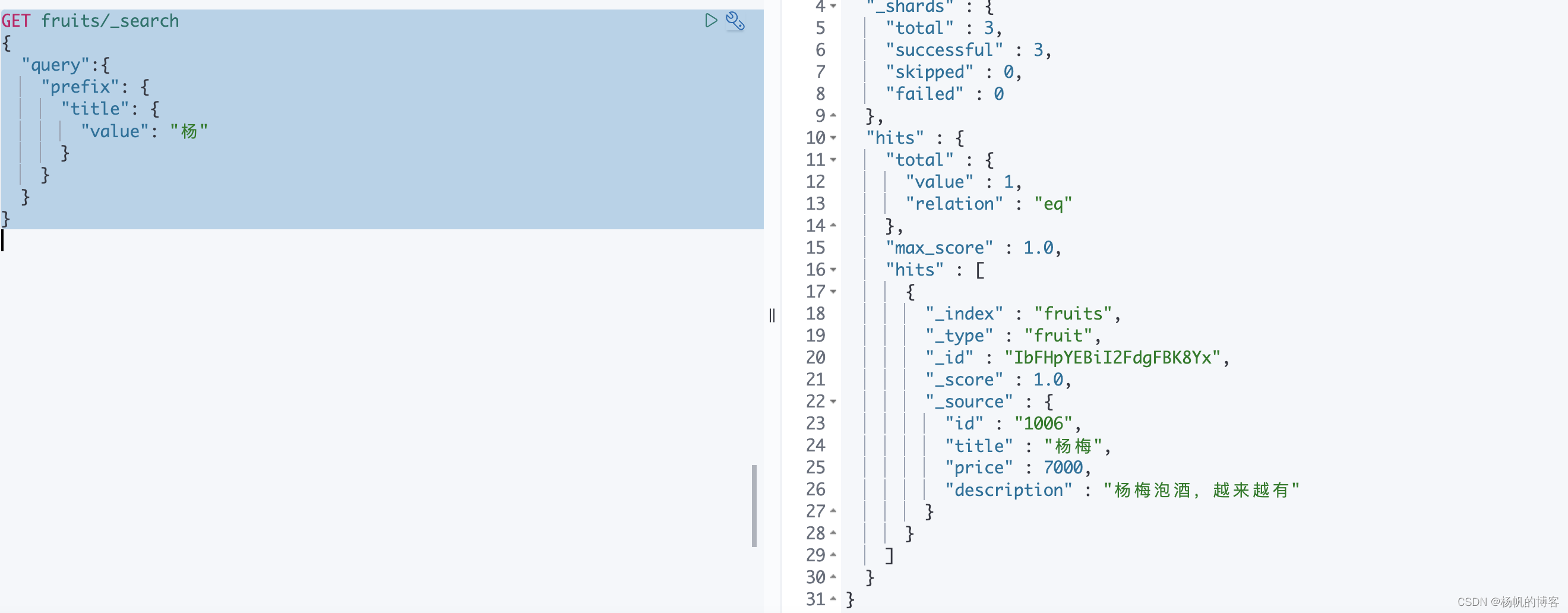
prefix
通过指定字段的前缀进行查询
GET fruits/_search
{
"query":{
"prefix": {
"title": {
"value": "杨"
}
}
}
}
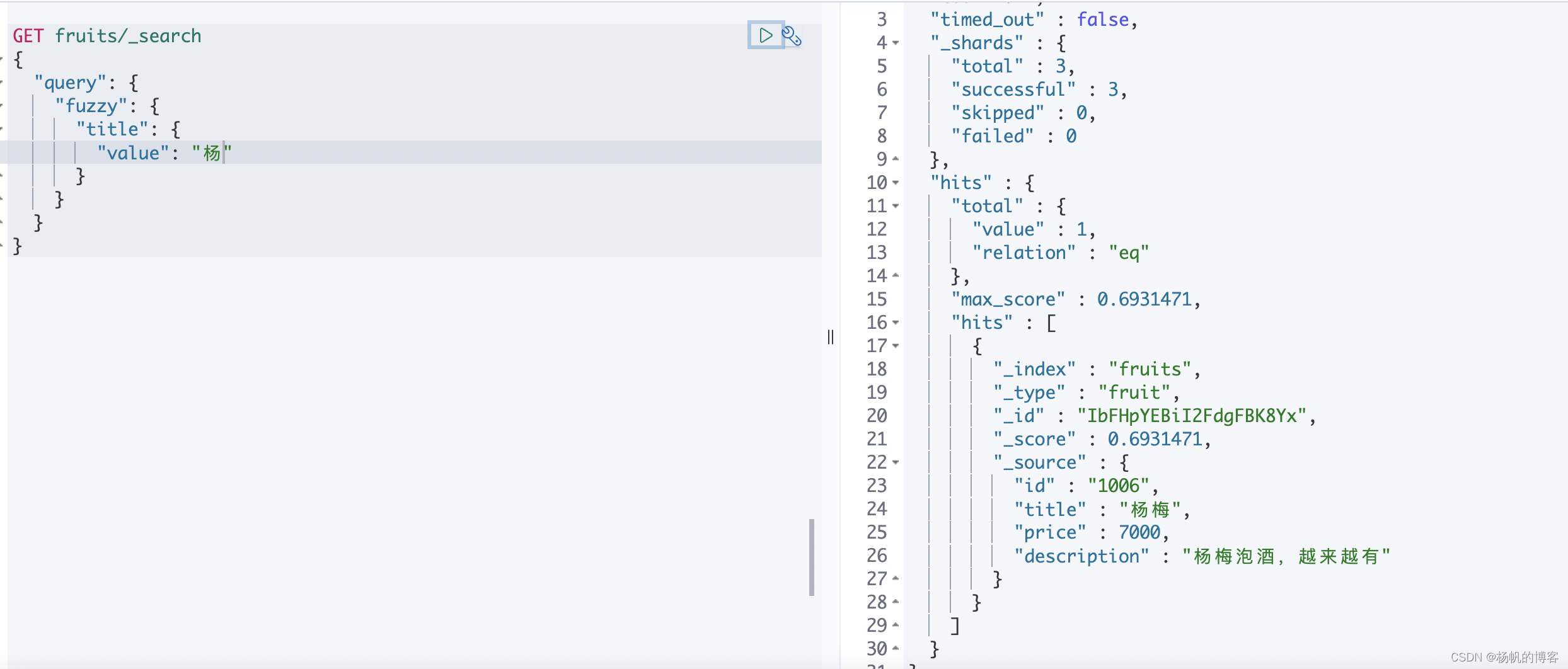
fuzzy查询
用于近似查询,一般情况下有一个单词错误的情况下,fuzzy 查询可以找到另一个近似的词来代替,主要有以下场景:
- 修改一个单词,如:
box—>fox。 - 移除一个单词,如:
black–>lack。 - 插入一个单词,如:
sic–>sick。 - 转换两个单词顺序,如:
act–>cat。
为了可以查询到这种近似的单词,fuzzy 查询需要创建一个所有近似词的集合,这样搜索的时候就可以采用精确查询找到近似的词来代替查询。
GET fruits/_search
{
"query": {
"fuzzy": {
"title": {
"value": "杨"
}
}
}
}
bool查询
- bool 查询可以用来合并多个条件查询结果的布尔逻辑,它包含一下操作符:
- must :: 多个查询条件的完全匹配,相当于 and 。
- must_not :: 多个查询条件的相反匹配,相当于 not 。
- should :: 至少有一个查询条件匹配, 相当于 or 。
GET fruits/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title.keyword": {
"value": "杨梅"
}
}
}
],
"should": [
{
"term": {
"title.keyword": {
"value": "苹果"
}
}
}
],
"must_not": [
{
"term": {
"id": {
"value": "1003"
}
}
}
]
}
}
}过滤查询
GET fruits/_search
{
"query": {
"bool": {
"filter": {
"term": {
"title.keyword": "杨梅"
}
}
}
}
}查询和过滤的对比
- 一条过滤语句会询问每个文档的字段值是否包含着特定值。
- 查询语句会询问每个文档的字段值与特定值的匹配程度如何。
- 一条查询语句会计算每个文档与查询语句的相关性,会给出一个相关性评分 _score,并且 按照相关性对匹 配到的文档进行排序。 这种评分方式非常适用于一个没有完全配置结果的全文本搜索。
- 一个简单的文档列表,快速匹配运算并存入内存是十分方便的, 每个文档仅需要1个字节。这些缓存的过滤结果集与后续请求的结合使用是非常高效的。
- 查询语句不仅要查找相匹配的文档,还需要计算每个文档的相关性,所以一般来说查询语句要比 过滤语句更耗时,并且查询结果也不可缓存。
- 做精确匹配搜索时,最好用过滤语句,因为过滤语句可以缓存数据。
ElasticSearch聚合
聚合语法
聚合的请求参数是以json的形式体现的,聚合的具体关键字是aggregations 或 aggs 同时要个每个聚合起一个别名,并且相同层级下的聚合名称不能相同,然后就要指定聚合的类型以及和该类型相关的字段选项。如果聚合是在某个查询条件下面进行的,那么和查询不匹配的文档不会计算在内的
下面展示了聚合的基本结构
"aggregations" : { #①聚合的关键字,也可以缩写为aggs
"<aggregation_name>":{ #②聚合的自定义名称
"<aggregation_type>" : { #③聚合的类型,指标相关的,如 max、
# min、avg、sum,桶相关的 terms、filter 等
<aggregation_body> # ④聚合体:对哪些字段进行聚合,取字段的值
},
"<sub_aggregation_name>":{ #⑤子聚合
"<aggregation_type>" : {
<aggregation_body>
}
}
}
}
①aggregations 的键,可以缩写为 aggs:聚合的关键字
②聚合的名称,可以在请求的返回中看到这个名字,要求同一次请求中每个聚合的名称都不相同
③聚合的类型
Bucket(分桶)
terms聚合
"_count": "desc":按照聚合的key的数量进行排序
"_term": "desc":按照聚合的key进行排序
GET fruits/_search
{
"size": 0,
"aggs": {
"title": {
"terms": {
"field": "title.keyword",
"size": 10,
"order": {
"_count": "desc",
"_term": "desc"
}
}
}
}
}"aggregations" : {
"title" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "杨梅",
"doc_count" : 2
},
{
"key" : "橘子",
"doc_count" : 2
},
{
"key" : "苹果",
"doc_count" : 2
},
{
"key" : "菠萝",
"doc_count" : 2
},
{
"key" : "西红柿",
"doc_count" : 2
},
{
"key" : "西红柿1111",
"doc_count" : 1
}
]
}
}
聚合之后求每个聚合下的平均值、最大值、最小值
GET fruits/_search
{
"size": 0,
"aggs": {
"title": {
"terms": {
"field": "title.keyword",
"size": 10,
"order": {
"_count": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
},
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}"aggregations" : {
"title" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "杨梅",
"doc_count" : 2,
"max_price" : {
"value" : 7000.0
},
"min_price" : {
"value" : 7000.0
},
"avg_price" : {
"value" : 7000.0
},
"sum_price" : {
"value" : 14000.0
}
},
{
"key" : "橘子",
"doc_count" : 2,
"max_price" : {
"value" : 7500.0
},
"min_price" : {
"value" : 7500.0
},
"avg_price" : {
"value" : 7500.0
},
"sum_price" : {
"value" : 15000.0
}
},
{
"key" : "苹果",
"doc_count" : 2,
"max_price" : {
"value" : 8500.0
},
"min_price" : {
"value" : 8500.0
},
"avg_price" : {
"value" : 8500.0
},
"sum_price" : {
"value" : 17000.0
}
},
{
"key" : "菠萝",
"doc_count" : 2,
"max_price" : {
"value" : 6500.0
},
"min_price" : {
"value" : 6500.0
},
"avg_price" : {
"value" : 6500.0
},
"sum_price" : {
"value" : 13000.0
}
},
{
"key" : "西红柿",
"doc_count" : 2,
"max_price" : {
"value" : 6000.0
},
"min_price" : {
"value" : 6000.0
},
"avg_price" : {
"value" : 6000.0
},
"sum_price" : {
"value" : 12000.0
}
},
{
"key" : "西红柿1111",
"doc_count" : 1,
"max_price" : {
"value" : 6000.0
},
"min_price" : {
"value" : 6000.0
},
"avg_price" : {
"value" : 6000.0
},
"sum_price" : {
"value" : 6000.0
}
}
]
}
}stats分析
GET fruits/_search
{
"size": 0,
"aggs": {
"title": {
"terms": {
"field": "title.keyword",
"size": 10,
"order": {
"_count": "desc"
}
},
"aggs": {
"stat_price": {
"stats": {
"field": "price"
}
}
}
}
}
}"aggregations" : {
"title" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "杨梅",
"doc_count" : 2,
"stat_price" : {
"count" : 2,
"min" : 7000.0,
"max" : 7000.0,
"avg" : 7000.0,
"sum" : 14000.0
}
},
{
"key" : "橘子",
"doc_count" : 2,
"stat_price" : {
"count" : 2,
"min" : 7500.0,
"max" : 7500.0,
"avg" : 7500.0,
"sum" : 15000.0
}
},
{
"key" : "苹果",
"doc_count" : 2,
"stat_price" : {
"count" : 2,
"min" : 8500.0,
"max" : 8500.0,
"avg" : 8500.0,
"sum" : 17000.0
}
},
{
"key" : "菠萝",
"doc_count" : 2,
"stat_price" : {
"count" : 2,
"min" : 6500.0,
"max" : 6500.0,
"avg" : 6500.0,
"sum" : 13000.0
}
},
{
"key" : "西红柿",
"doc_count" : 2,
"stat_price" : {
"count" : 2,
"min" : 6000.0,
"max" : 6000.0,
"avg" : 6000.0,
"sum" : 12000.0
}
},
{
"key" : "西红柿1111",
"doc_count" : 1,
"stat_price" : {
"count" : 1,
"min" : 6000.0,
"max" : 6000.0,
"avg" : 6000.0,
"sum" : 6000.0
}
}
]
}
}cardinality(计算)
统计去重,相当于mysql的distinct语法
GET fruits/_search
{
"size": 0,
"aggs": {
"agg_price": {
"cardinality": {
"field": "price"
}
}
}
} "aggregations" : {
"agg_price" : {
"value" : 5
}
}
















 3284
3284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









