







Doris分析型数据库
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即时查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Doris的几种数据源导入方案
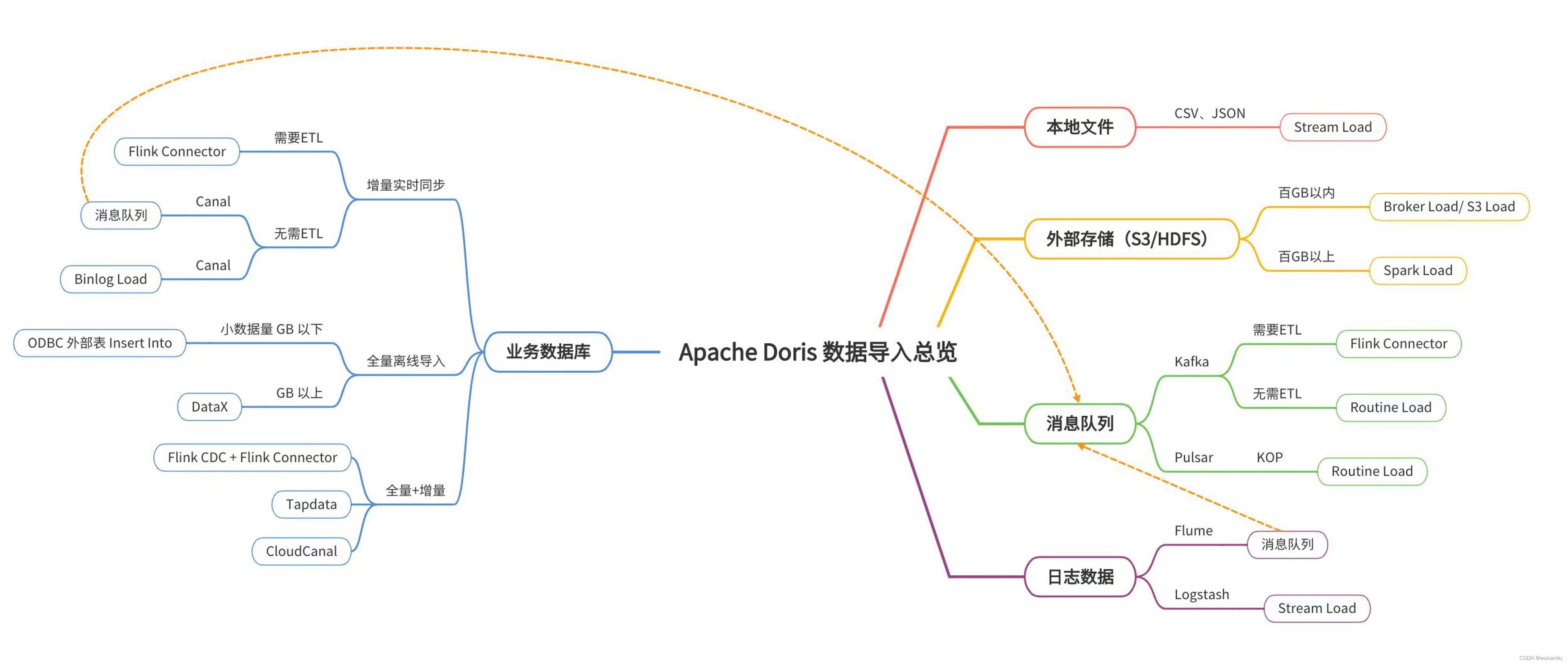
1、Doris数据仓库的第一种导入方案(Stream Load):
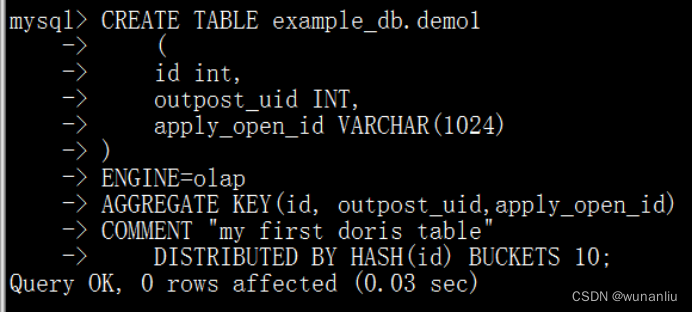
创建Doris 基础的分桶表,OLAP类型
CREATE TABLE example_db.test
(
id int,
outpost_uid INT,
create_time DATETIME,
apply_open_id VARCHAR(1024),
scan_result INT,
reason VARCHAR(1024),
phone VARCHAR(100),
tz_place_id VARCHAR(100),
address_id INT,
u_id INT,
case_type INT
)
ENGINE=olap
AGGREGATE KEY(id, outpost_uid,create_time,apply_open_id,scan_result,reason,phone,tz_place_id,address_id,u_id,case_type)
COMMENT "my first doris table"
DISTRIBUTED BY HASH(id) BUCKETS 10;将需要的TXT的文件,上传到服务器某一个文件夹下面。
/home/wx_outpost_scan.txt书写Doris 数据倒入脚本命令
curl -u root:doris密码 -H "label:liuwunan2" -H "column_separator:," -T /home/wx_outpost_scan.txt http://BE_IP:8040/api/example_db/aaaaa/_stream_load
Demo操作:
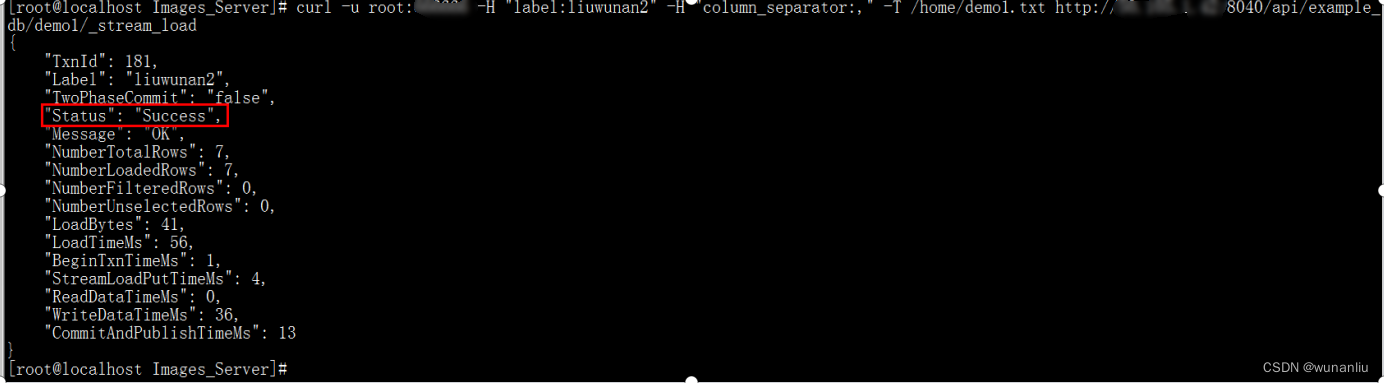
数据样例对比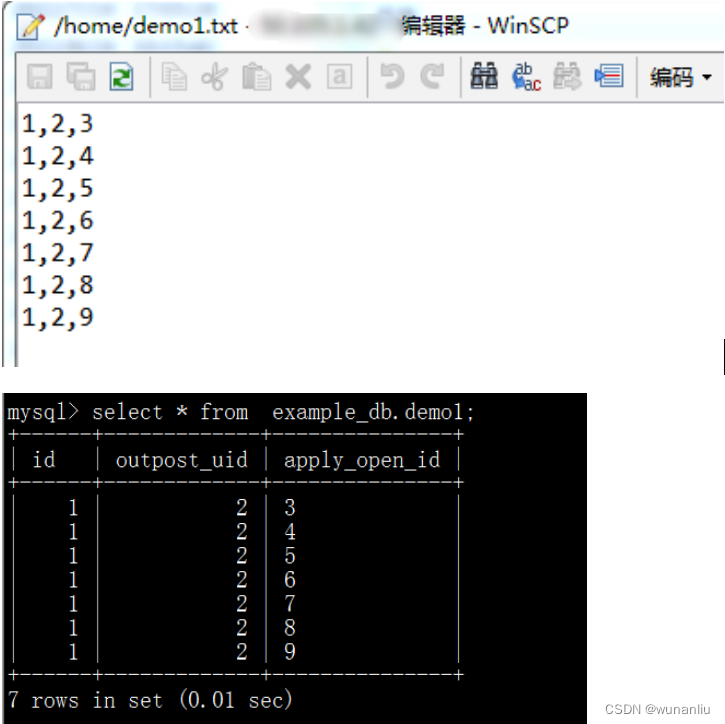
查看日志:
show load order by createtime desc limit 1\G备注说明:
数据倒入,此处需要注意一个问题:
column_separator 用于指定倒入文件中的列的分隔符,默认为\t,如果是不可见字符,则需要加\x作为前缀,使用十六进制来表示分隔符。
如Hive文件分隔符\x01,则需要指定为-H “column_separator:\x01”。
2、HDFS文本文件导入Doris中(Broker Load):
HDFS文件倒入Doris
需要启动apache_hdfs_broker组件:
直接启动,不需要修改配置文件 组件服务:BrokerBootstrap,【切记后台守护进程运行】
第1步:创建Doris表(指定对应字段)
create table student1
(
phone varchar(50) ,
user_name String ,
id_card varchar(50),
times date
)
DUPLICATE KEY(phone)
DISTRIBUTED BY HASH(id_card) BUCKETS 10;第2步:创建HDFS数据导入的流
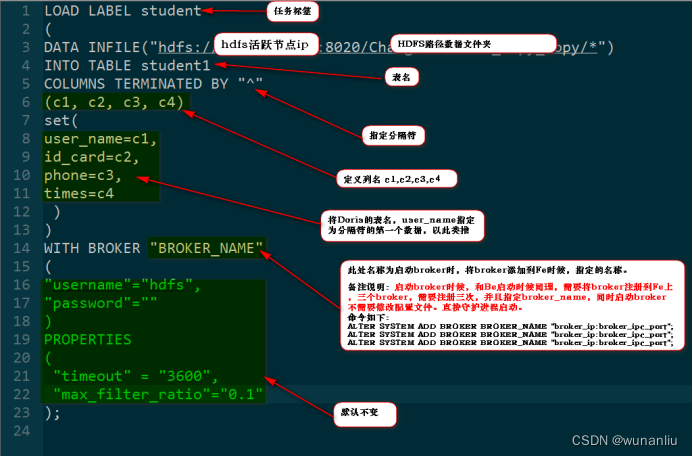
LOAD LABEL student
(
DATA INFILE("hdfs://HDFS_IP(活跃节点):8020/test_copy_copy/*")
INTO TABLE student1
COLUMNS TERMINATED BY "^"
(c1, c2, c3, c4)
set(
user_name=c1,
id_card=c2,
phone=c3,
times=c4)
)
WITH BROKER "BROKER_NAME"
(
"username"="hdfs",
"password"=""
)
PROPERTIES
(
"timeout" = "3600",
"max_filter_ratio"="0.1"
);解释说明:
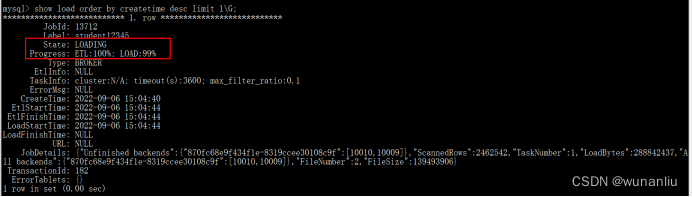
第3步:查看过程和结果
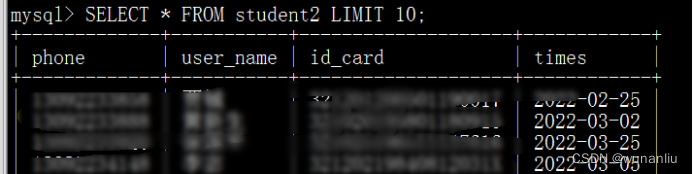
第4步:查看结果
3、Kafka实时接入数据进入Doris(Routine Load)
第1步:创建Doris 导入表
create table student222
(
id varchar(50),
user_name varchar(50) ,
times varchar(50)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4157
4157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









