







 本文详述了在Istio服务网格上运行Apache Kafka的基准测试,探讨了性能影响。测试表明,在Istio上运行Kafka不会显著增加性能开销,且Pipeline平台支持创建跨多云和混合云的Kafka集群。测试涉及单集群和多集群场景,展示了在启用mTLS的情况下,Kafka性能优于直接使用SSL/TLS。
本文详述了在Istio服务网格上运行Apache Kafka的基准测试,探讨了性能影响。测试表明,在Istio上运行Kafka不会显著增加性能开销,且Pipeline平台支持创建跨多云和混合云的Kafka集群。测试涉及单集群和多集群场景,展示了在启用mTLS的情况下,Kafka性能优于直接使用SSL/TLS。

作者:Balint Molnar
编者按
本文是一篇Kafka的基准测试分析报告,作者详细介绍了测试的环境和配置选择,并在单集群、多集群、多云、混合云等各种场景下进行了A/B测试和性能分析,评估了Istio的引入对性能的影响情况。最后对作者所在公司Banzai Cloud的云产品进行了介绍。
我们的容器管理平台Pipeline以及CNCF认证的Kubernetes发行版PKE的一个关键特性是,它们能够在多云和混合云环境中无缝地构建并运行。虽然Pipeline用户的需求因他们采用的是单云方法还是多云方法而有所不同,但通常基于这些关键特性中的一个或多个:
多云应用管理
一个基于Istio的自动化服务网格,用于多云和混合云部署
基于Kubernetes federation v2(集群联邦)的联合资源和应用部署
随着采用基于Istio operator的多集群和多混合云的增加,对运行接入到服务网格中的分布式或去中心化的应用的能力的需求也增加了。我们的客户在Kubernetes上大规模运行的托管应用之一是Apache Kafka。我们认为,在Kubernetes上运行Apache Kafka最简单的方法是使用Banzai Cloud的Kafka spotguide来构建我们的Kafka operator。然而,到目前为止,我们的重点一直是自动化和操作单个集群Kafka部署。
TLDR
我们已经添加了在Istio上运行Kafka所需的支持 (使用Kafka 和 Istio operator,并通过 Pipeline编排).
在Istio上运行Kafka不会增加性能开销 (不同于典型的mTLS,在SSL/TLS上运行Kafka是一样的)。
使用 Pipeline,你可以创建跨多云和混合云环境的Kafka集群。
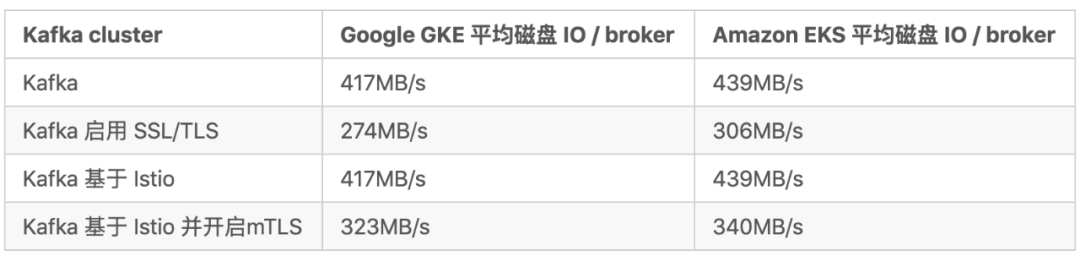
带有生产者ACK设置为all的3个broker、3个partition和3个replication因子场景的指标预览:
单集群结果
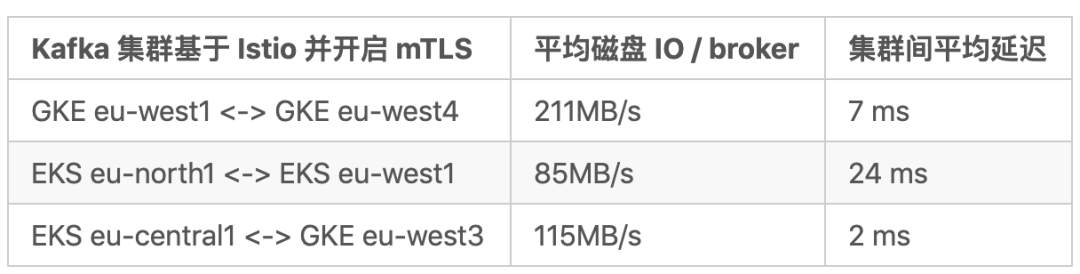
多集群结果
在Istio服务网格上运行Kafka
Kafka社区对如何利用更多的Istio功能非常感兴趣,例如开箱即用的Tracing,穿过协议过滤器的mTLS等。尽管这些功能有不同的需求,如Envoy、Istio和其他各种GitHub repos和讨论板上所反映的那样。大部分的这些特性已经在我们的Pipeline platform的Kafka spotguide中,包括监控、仪表板、安全通信、集中式的日志收集、自动伸缩,Prometheus警报,自动故障恢复等等。我们和客户错过了一个重要的功能:网络故障和多网络拓扑结构的支持。我们之前已经利用Backyards和Istio operator解决过此问题。现在,探索在Istio上运行Kafka的时机已经到来,并在单云多区、多云,特别是混合云环境中自动创建Kafka集群。
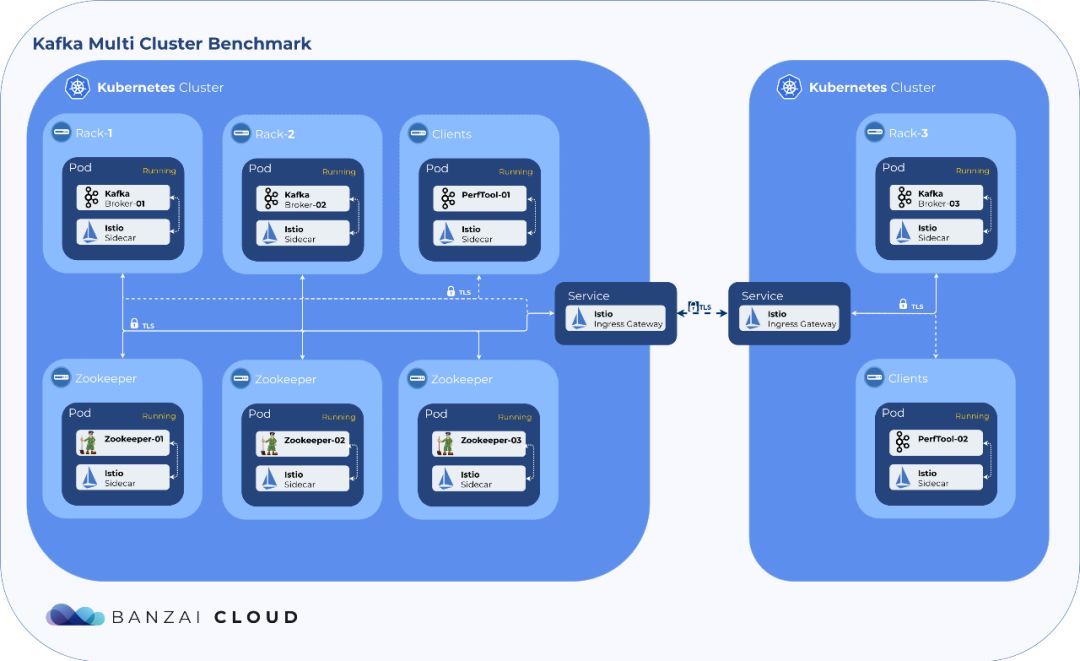
让Kafka在Istio上运行并不容易,需要时间以及在Kafka和Istio方面的大量专业知识。经过一番努力和决心,我们完成了要做的事情。然后我们以迭代的方式自动化了整个过程,使其在Pipeline platform上运行的尽可能顺利。对于那些想要通读这篇文章并了解问题所在的人——具体的来龙去脉——我们很快将在另一篇文章中进行深入的技术探讨。同时,请随时查看相关的GitHub代码库。
认知偏差
认知偏差是一个概括性术语,指的是信息的上下文和结构影响个人判断和决策的系统方式。影响个体的认知偏差有很多种,但它们的共同特征是,与人类的个性相一致,它们会导致判断和决策偏离理性的客观。
自从Istio operator发布以来,我们发现自己陷入了一场关于Istio的激烈辩论中。我们已经在Helm(和Helm 3)中目睹了类似的过程,并且很快意识到关于这个主题的许多最激进的观点并不是基于第一手的经验。当我们与对Istio的复杂性有一些疑问的人产生共鸣的时候——
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









