




 本文介绍了金融数据处理中的事件采样方法,对比了无脑型下采样和基于事件采样的优缺点,重点探讨了基于事件采样的金融含义,如结构性突破和市场微观结构。通过实例展示了如何从标普500价值股ETF的tick数据中,进行数据清洗、整合和异常值处理,最终采用CUSUM Filter进行事件采样,得出更高质量的训练样本。
本文介绍了金融数据处理中的事件采样方法,对比了无脑型下采样和基于事件采样的优缺点,重点探讨了基于事件采样的金融含义,如结构性突破和市场微观结构。通过实例展示了如何从标普500价值股ETF的tick数据中,进行数据清洗、整合和异常值处理,最终采用CUSUM Filter进行事件采样,得出更高质量的训练样本。

本文是 AFML 系列的第三篇
基于事件采样
在上贴〖从 Tick 到 Bar〗里,我们已经会从「异质」的 tick 数据采样出「同质」的 bar 数据。当数据太多时,传统 (非深度) 机器学习算法的表现会有上限,如下图的红线所示。
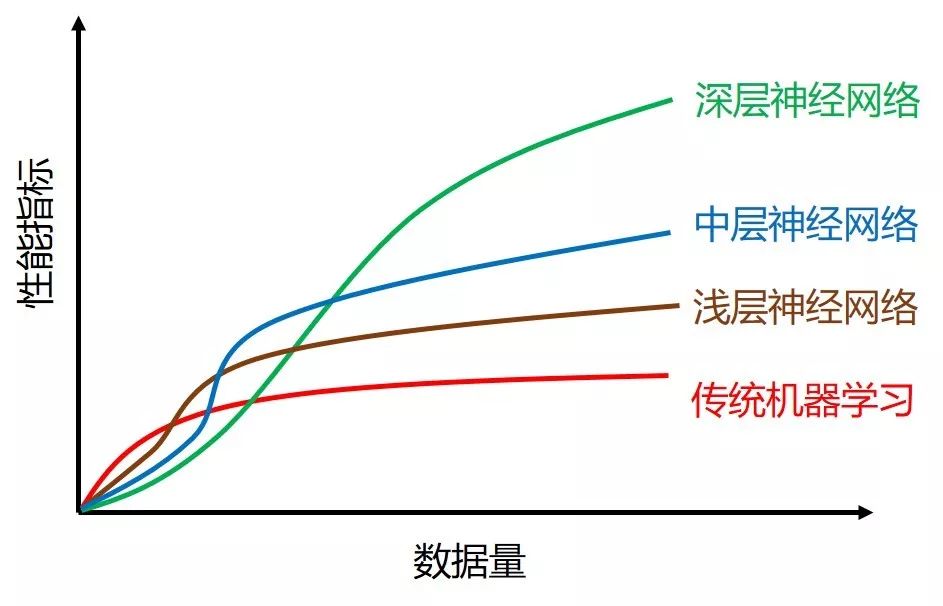
这时减少数据量并发掘出更好特征的数据才能使机器学习算法取得好效果。通常有两种方法:
无脑型下采样(downsampling)
基于事件采样(event-based sampling)
第一种又可细分为线性等分采样(linspace sampling) 和均匀采样(uniform sampling)。它们虽然可以做到减少数据量,但是采样数据的方法都没有金融含义支撑,线性等分采样过于简单,均匀采样过于随机。 因此本帖来看看第二种基于事件采样,即背后有金融含义支撑的采样方法。
想想投资组合经理买卖是不是通常发生在特定事件发生后,如
结构性突破 (structural break):均值回归模式 → 动量模式
市场微观结构 (market microstructure ):FIX 信息
这些事件通常伴随着下面三种场景
宏观统计数据公布
波动率急剧增加
价格大幅偏离均衡水平
本帖内容很简单,只围绕着一个公式展开。但困难的是当我用标普 500 价值股 ETF的高频 tick 的数据的时候,做了很多数据处理的工作。这些很麻烦但又非常重要,因此我也想将这个处理数据的完整过程记录下来,防止以后再踩坑。
首先引入 datetime, numpy, pandas, matplotlib, seaborn 等必要的包,并定义我最喜欢的一些颜色 (看过我盘一盘 Python 系列的读者应该知道我的喜好  )。
)。
from datetime import datetimeimport numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inlineimport seaborn as sns
dt_hex = '#2B4750' # darkteal, RGB = 43,71,80r_hex = '#DC2624' # red, RGB = 220,38,36g_hex = '#649E7D' # green, RGB = 100,158,125tl_hex = '#45A0A2' # teal, RGB = 69,160,162tn_hex = '#C89F91' # tan, RGB = 200,159,145
此外我还会用两个额外的工具包 mlfinlab 和 pathlib ,到使用它们的时候再解释。
1.1
源数据
我们使用的标普 500 价值股 ETF (IVE) tick 级别的数据从来自以下链接。
http://www.kibot.com/free_historical_data.aspx
想投资指数就可以买 ETF。比如我看好美国股票市场,但又不想投资个股,那么可以投资标普 500 指数,用的金融工具就是其 ETF,代号为 IVE。
今天 (2019 年 8 月 1 日) 下载 IVE 的数据是从
2009 年 9 月 28 日早上 9:30
到
2019 年 7 月 31 日下午 16:00
数据存在 txt 格式,如下图所示 (注意最后三条数据的时间晚于下午 16:00,但是成交量为 0)。

1.2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









