






 本节课程深入讲解Scikit-Learn中的元估计器,包括ensemble集成学习、multiclass多类别分类、multioutput多输出分类、model_selection模型选择和pipeline数据预处理流水线。通过具体示例如BaggingClassifier、AdaBoostClassifier等,展示如何使用这些高级API提升机器学习效率。
本节课程深入讲解Scikit-Learn中的元估计器,包括ensemble集成学习、multiclass多类别分类、multioutput多输出分类、model_selection模型选择和pipeline数据预处理流水线。通过具体示例如BaggingClassifier、AdaBoostClassifier等,展示如何使用这些高级API提升机器学习效率。

这是 Python 数据机器学习系列的第二节《Scikit-Learn 中》
Python 数据可视化
Seaborn 下
Bokeh
Plotly
Cufflinks
PyEcharts
Python 数据分析
Python 基础
Sklearn 中核心 API 接口是估计器,而高级 API 接口是元估计器 (meta-estimator)。元估计器由很多基估计器 (base estimator) 组成。类比高阶函数将低阶函数当参数,元估计器将估计器当参数,其代码范式如下:
meta_estimator( base_estimator )
本课讨论五种元估计器,它们分别是
用来集成子模型的 ensemble
用来多类别和多标签分类的 multiclass
用来多输出分类的 multioutput
用于模型选择的 model_selection
用于数据预处理流水线的 pipeline
本课会用以下 Sklearn 中的模型来举例说明如何使用上述五种元估计器:
ensemble.BaggingClassifier
ensemble.AdaBoostClassifier
ensemble.VotingClassifier
ensemble.StackingClassifier
multiclass.OneVsOneClassifier
multiclass.OneVsRestClassifier
multioutput.MultiOutputClassifier
model_selection.GridSearchCV
model_selection.RandomizedSearchCV
pipeline.Pipeline
pipeline.FeatureUnion
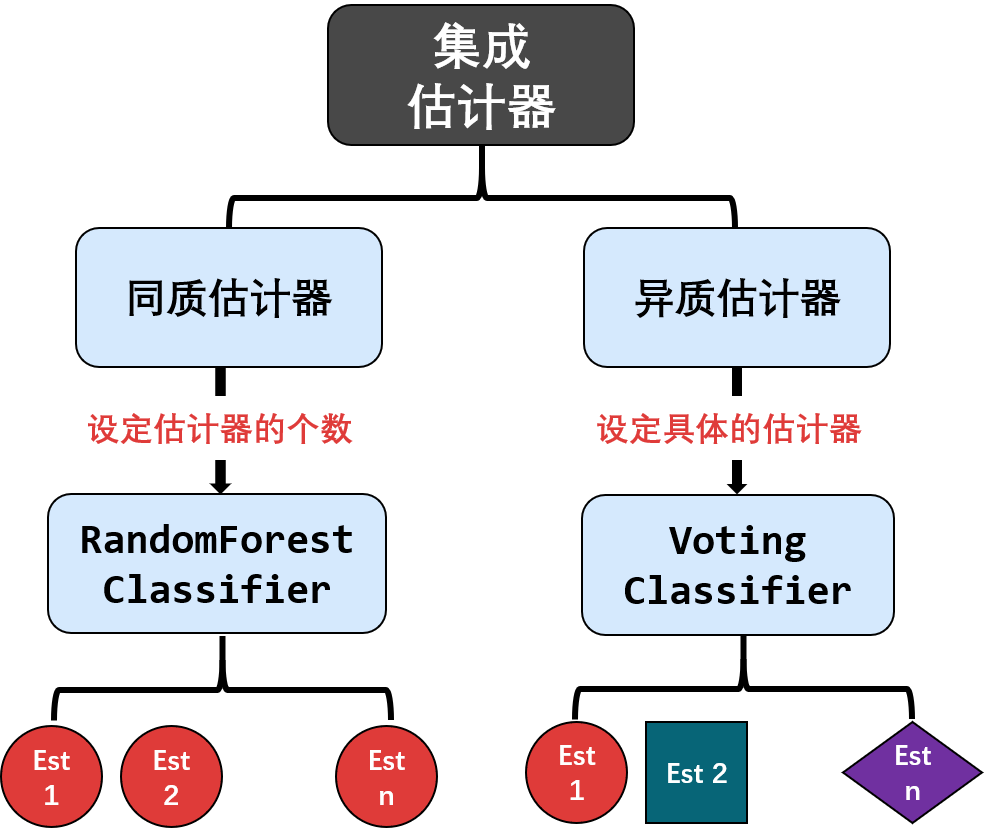
集成估计器
集成估计器是用来做集成学习,该估计器里面有若干个分类器 (classifier) 或回归器 (regressor)。
分类器统计每个子分类器的预测类别数,再用「多数投票」原则得到最终预测。
回归器计算每个子回归器的预测平均值。
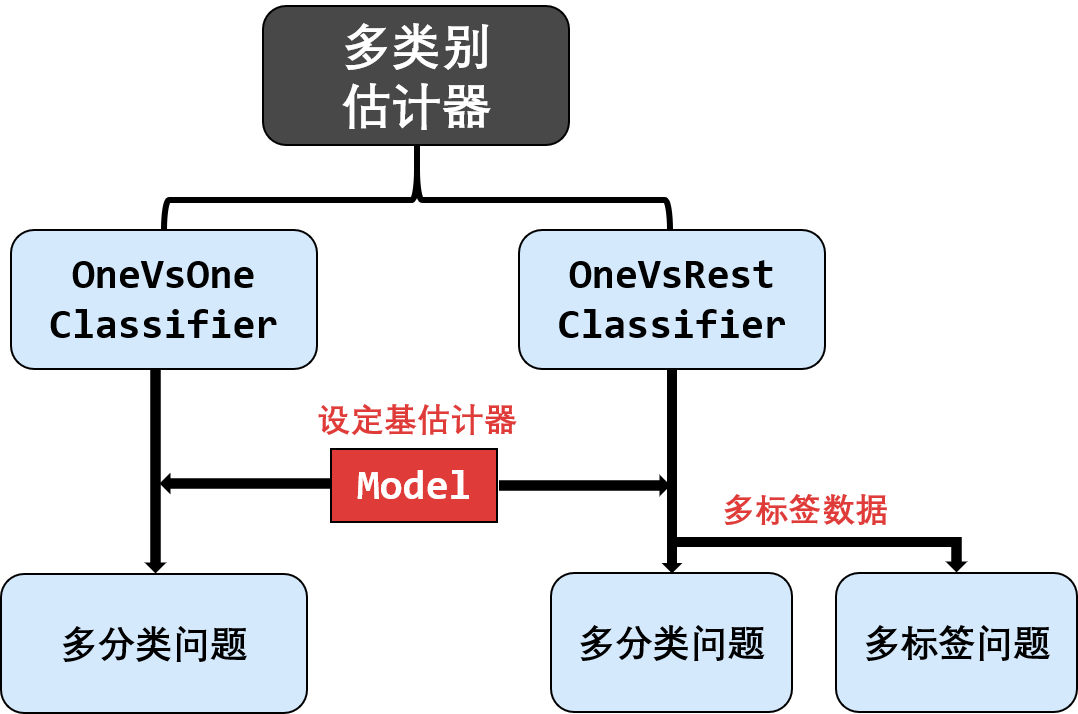
多类估计器
多类估计器可以处理多类别 (multi-class) 和多标签 (multi-label) 的分类问题。
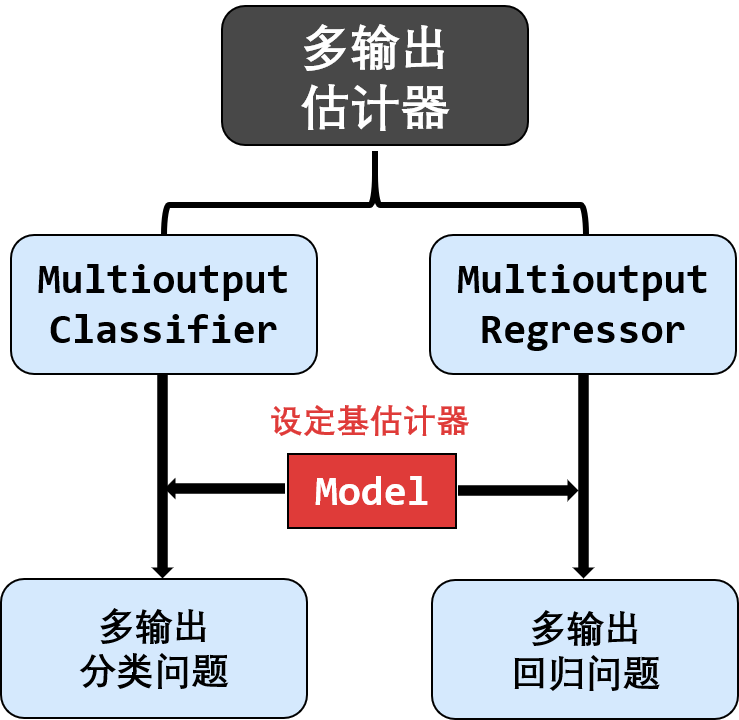
多输出估计器
多输出估计器可以处理多输出 (multi-output) 的分类问题。
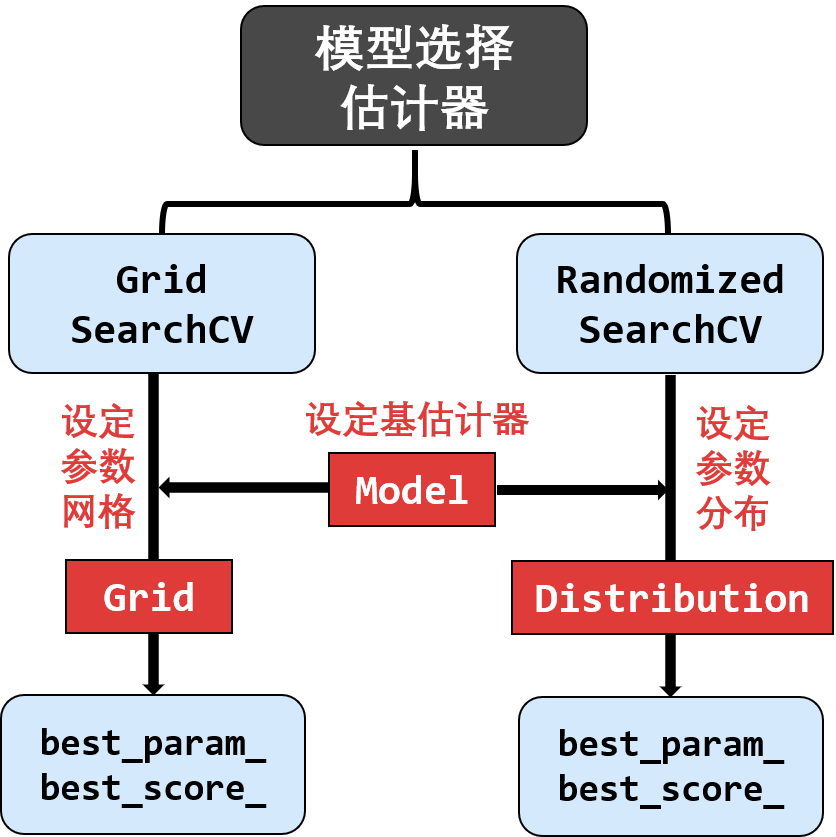
模型选择估计器
模型选择主要用于评估模型表现,常见的模型选择估计器包括:
cross_validate:评估交叉验证的表现。
learning_curve:建立学习曲线。
GridSearchCV:用交叉验证方法从网格中一组超参数搜索出最佳超参数。
RandomizedSearchCV:用交叉验证方法从一组随机超参数分布搜索出最佳超参数。
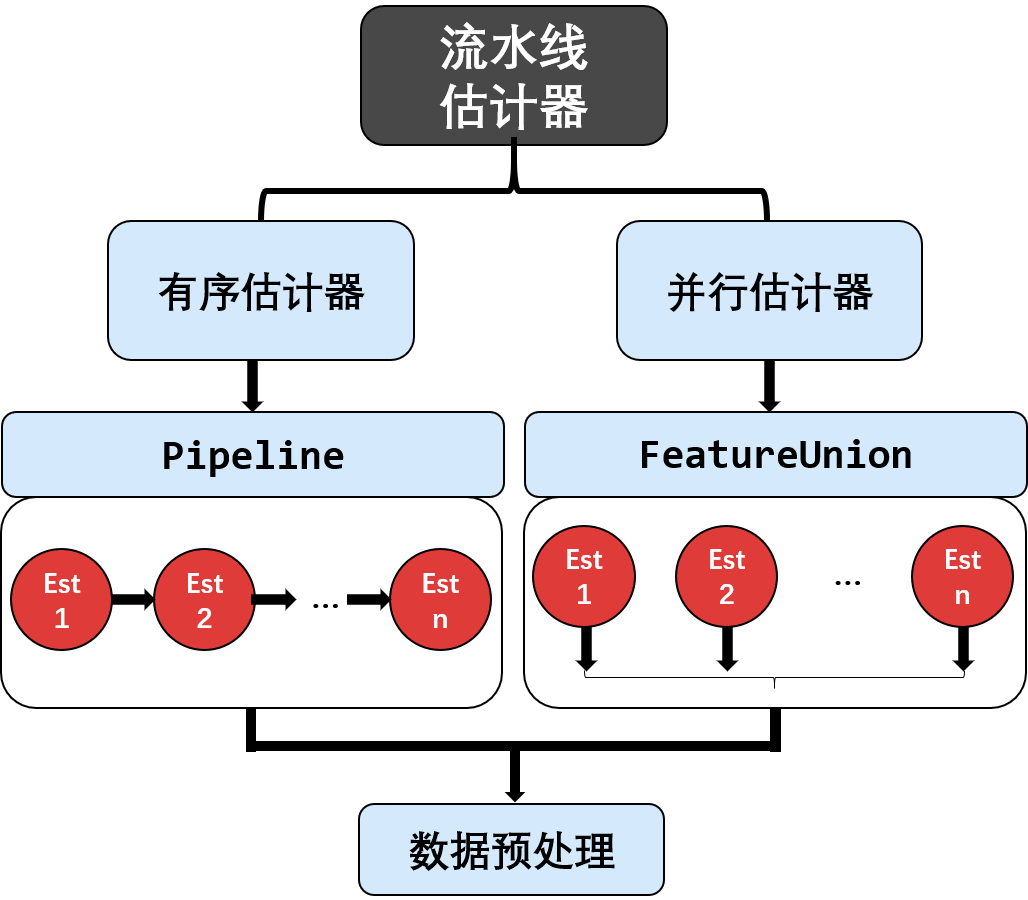
流水线估计器
流水线估计器把多个估计器串联 (Pipeline) 或并联 (FeatureUnion) 的方式组成一条龙服务。用好了它真的能大大提高效率。
想学就开始吧!
绝不会让你失望!
付费用户(付 1 赠 1)可以获得:
观看课程视频 (97 分钟)
Python 代码 (Jupyter Notebook)
Jupyter Notebook

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









