







神经网络基础
前馈神经网络
前馈网络中各个神经元按接受信息的先后分为不同的组。每一组可以看作
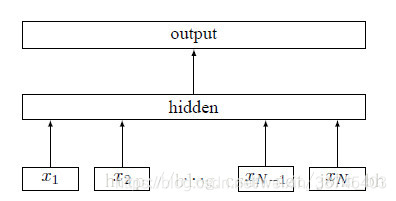
一个神经层。每一层中的神经元接受前一层神经元的输出,并输出到下一层神经元。整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有向无环路图表示。前馈网络包括全连接前馈网络和卷积神经网络等。其可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。见下图:
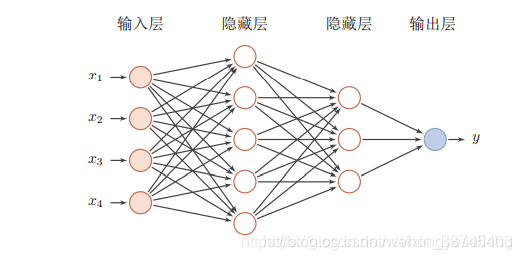 注意:如上图所示前馈神经网络,该网络公有三层结构,通常输入层不计入层数。
注意:如上图所示前馈神经网络,该网络公有三层结构,通常输入层不计入层数。
激活函数
激活函数需要具备以下几点性质:
1.连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
2.激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
3.激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
常用的激活函数包括:sigmoid函数、tanh函数、ReLU函数。
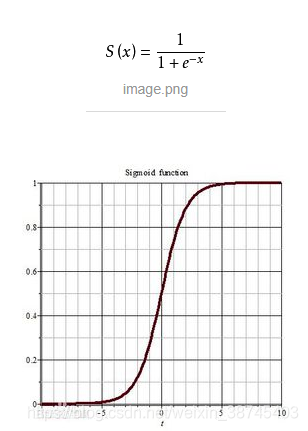
sigmoid函数
sigmoid函数一般是大家接触机器学习模型时最早学习到的激励函数模型。它的优点是整个区间都可导。
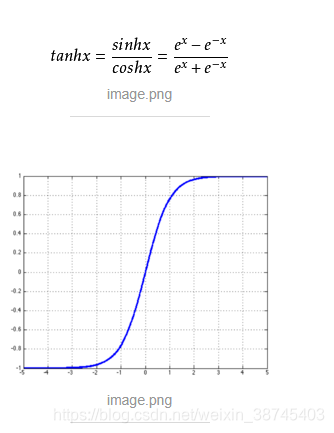
tanh函数
sigmoid函数的缺点是它不关于原点对称。我们对sigmoid函数进行平移,使其中心对称,得到tahn函数,其表现比sigmoid函数更好。
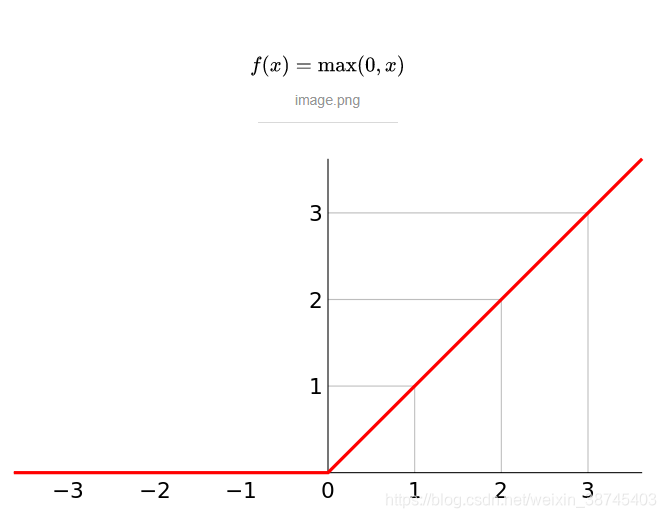
 ReLU函数
ReLU函数
tanh函数与sigmoid函数共同的缺点: 当它们倾向于比较大或者比较小的数的时候,整个函数的变化比较平缓,会影响到网络的学习效率。所以在实际工作中用得更多的是ReLU函数。
感知机
感知机是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取+1和-1);
感知机目的在求一个可以将实例分开的超平面,为了求它,我们用到基于误分类的损失函数和梯度下降的优化策略。
正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。
这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。
接下来我们会讨论怎样应用正则化和什么叫做正则化均值,然后将开始讨论怎样使用正则化来使学习算法正常工作,并避免过拟合。
参考:机器学习之正则化(Regularization)、吴恩达的视频
FastText的原理
fastText方法包含三部分,模型架构,层次SoftMax和N-gram子词特征。
模型架构
fasttext算法是一种有监督的结构,它通过上下文预测标签即文本的类别。
利用FastText模型进行文本分类
注意:win无法直接用pip install fasttext安装fasttext,我首先在python的第三方安装包网站https://www.lfd.uci.edu/~gohlke/pythonlibs/#fasttext*
下载fasttext‑0.8.22‑cp36‑cp36m‑win_amd64.whl后再本地安装
代码参考(下次进行实战):
https://www.jianshu.com/p/01a5ca060f07


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









