







 本文详细介绍了Python3中文件操作的基础知识,包括不同模式(r、r+、a、a+、w+等)下的读写操作,以及二进制模式(rb、wb)的应用。重点讲解了read()、readline()、readlines()方法的区别,文件指针的使用,如tell()、seek()、flush()和truncate()方法,强调了在读写文件时内存消耗和效率的考虑。此外,还讨论了with语句在文件操作中的作用。
本文详细介绍了Python3中文件操作的基础知识,包括不同模式(r、r+、a、a+、w+等)下的读写操作,以及二进制模式(rb、wb)的应用。重点讲解了read()、readline()、readlines()方法的区别,文件指针的使用,如tell()、seek()、flush()和truncate()方法,强调了在读写文件时内存消耗和效率的考虑。此外,还讨论了with语句在文件操作中的作用。
文章目录
- 前言
- 一、文件基本操作 --- r读模式
- 二、文件基本操作 --- 读写模式r+(常用)
- 三、文件基本操作 --- 追加读模式a+(常用)
- 四、文件基本操作 --- 写读模式w+(不常用)
- 五、文件基本操作 --- 二进制格式_读模式rb(open时,不能用encoding参数)
- 六、文件基本操作 --- 二进制格式_读模式wb(open时,不能用encoding参数)
- 七、文件基本操作 --- 其他操作(常用操作)
- 八、文件基本操作 --- 其他操作(不常用操作)
- 1. detach()方法:文件编辑过程中,更换文件编码格式
- 2. encoding()方法:打印当前文件,编码格式
- 3. buffer()方法
- 4. errors()方法:用于异常处理
- 5. fileno():返回文件句柄在内存中的编号,调用操作系统接口获取的
- 6. name():以str类型,返回文件名称
- 7. isatty():判断当前文件是否为终端设备,如打印机等,底层开发时才会用到
- 8. seekable():判断是否可以使用seek方法
- 9. readable():判断文件是否可读
- 10. writeable():判断文件是否可写
- 11. closed():判断文件是否已关闭
- 12. readinto():可以直接将二进制数据写入到可变缓冲区中,很少使用
- 九、文件基本操作 --- with语句
- 总结
前言
首先要知道,对文件操作基本流程:
1、打开文件,得到文件句柄并赋值给一个变量
2、通过句柄对文件进行操作
3、关闭文件
文件操作方法注释等更多详情,可参考:alex大王第二周博客
打开文件的模式有:
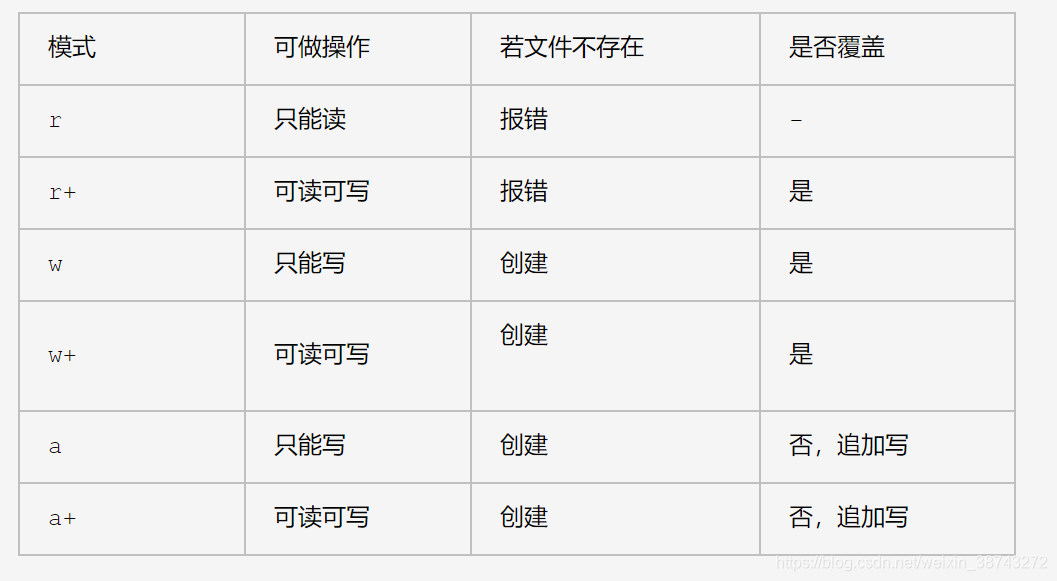
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【不可读;不存在则创建;存在则只追加内容;】
- 附:mode 的值包括 ‘r’ ,表示文件只能读取;‘w’ 表示只能写入(现有同名文件会被覆盖);‘a’ 表示打开文件并追加内容,任何写入的数据会自动添加到文件末尾。‘r+’ 表示打开文件进行读写。mode 实参是可选的,省略时的默认值为 ‘r’。
- 通常,文件以 text mode 打开,即,从文件中读取或写入字符串时,都以指定编码方式进行编码。如未指定编码格式,默认值与平台相关 (参见 open())。在 mode 中追加的 ‘b’ 则以 binary mode 打开文件:此时,数据以字节对象的形式进行读写。该模式用于所有不包含文本的文件。
- 在文本模式下读取文件时,默认把平台特定的行结束符(Unix 上为 \n, Windows 上为 \r\n)转换为 \n。在文本模式下写入数据时,默认把 \n 转换回平台特定结束符。这种操作方式在后台修改文件数据对文本文件来说没有问题,但会破坏 JPEG 或 EXE 等二进制文件中的数据。注意,在读写此类文件时,一定要使用二进制模式。
“+” 表示可以同时读写某个文件
- r+,读写文件【1. 无法新建文件 2. 可读;可覆盖写;可追加写】
- w+,写读文件【1. 可以新建文件 2. 可读;可覆盖写;】
- a+,追加写文件【1. 可以新建文件 2. 可读;可追加写】
- "U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
总结:
# lyrics.txt原文:
这天,酒店老板正在大厅巡视。
来了一乞丐上前说道:“老板给个牙签行吗?”
老板给他一个打发走了。
一会儿,又来一个乞丐,也是来要牙签的。
老板心想现在这乞丐怎么不要饭改要牙签了?
也同样给他一个打发走了,没过多旧,又来一个乞丐。
老板对他说:“你也是来要牙签的吗?”
乞丐说:“有个人吐了,可我晚了一步,已经被前面两个乞丐把能吃的都吃了,现在只剩下汤了。你能给我个吸管吗?
一、文件基本操作 — r读模式
- 文件读取规则:文件维护着类似指针一样的东西,文件打开时,指针会处于文件开始位置,文件首次读取时(首次调用read方法时),会从头开始一行一行读取,读取到哪个地方,指针就会移动到哪个地方,指针除非调用seek方法移回去,否则不会自动回到开始位置!!!
1. read()方法(只适合读小文件)
- read方法会从当前位置读取整个文件剩余内容,按照str类型,返回读取内容
- 根据文件读取规则,首次读取时,文件指针会移动到文件尾部,如果第二次读取前没有使用seek方法移动文件指针,则第二次读取内容为""
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
first_read = f.read()
print("-----first_read-----%s, %s" % (type(first_read), first_read))
second_read = f.read()
print("-----second_read-----%s, >>>%s<<<" % (type(second_read), second_read))
f.close() # 关闭文件
# 输出:
-----first_read-----<class 'str'>, 这天,酒店老板正在大厅巡视。
来了一乞丐上前说道:“老板给个牙签行吗?”
老板给他一个打发走了。
一会儿,又来一个乞丐,也是来要牙签的。
老板心想现在这乞丐怎么不要饭改要牙签了?
也同样给他一个打发走了,没过多旧,又来一个乞丐。
老板对他说:“你也是来要牙签的吗?”
乞丐说:“有个人吐了,可我晚了一步,已经被前面两个乞丐把能吃的都吃了,现在只剩下汤了。你能给我个吸管吗?
-----second_read-----<class 'str'>, >>><<<
2. readline()方法
- 每次只读一行,并以str类型返回
- 根据文件读取规则,首次读取时,文件指针会移动到第二行首,第二次读取前如果没有使用seek方法移动文件指针,第二次使用readline方法读取内容为第二行内容
- 如果想要读取多行,可以使用循环
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
first_line = f.readline()
print(type(first_line), first_line)
second_line = f.readline()
print(type(second_line), second_line)
f.close() # 关闭文件
# 输出:
<class 'str'> 这天,酒店老板正在大厅巡视。
<class 'str'> 来了一乞丐上前说道:“老板给个牙签行吗?”
3. readlines()方法(只适合读小文件)
- 将文件内容全部读出,并以list方式返回
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
# 打开文件
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 读取文件
lines = f.readlines()
print(type(lines), lines)
# 关闭文件
f.close()
# 输出:
<class 'list'> ['这天,酒店老板正在大厅巡视。\n', '来了一乞丐上前说道:“老板给个牙签行吗?”\n', '老板给他一个打发走了。\n', '一会儿,又来一个乞丐,也是来要牙签的。\n', '老板心想现在这乞丐怎么不要饭改要牙签了?\n', '也同样给他一个打发走了,没过多旧,又来一个乞丐。\n', '老板对他说:“你也是来要牙签的吗?”\n', '乞丐说:“有个人吐了,可我晚了一步,已经被前面两个乞丐把能吃的都吃了,现在只剩下汤了。你能给我个吸管吗?']
4. 读文件方法, 内存消耗对比(重要!)
- 大文件时, 推荐使用for line in f方法,此时f为迭代器,读取文件,将文件内容一行一行全部读出到内存,且仅内存中,仅保存一行,大文件时,内存消耗也不大,效率高
- 读取文件,内存消耗对比,更多详情,可参考:https://www.cnblogs.com/happenlee/p/9528136.html
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
# 打开文件
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 读取文件, 将文件内容全部读出到内存, 大文件时, 内存消耗大
for line in f.readlines():
print(type(line), line.strip())
print("分隔符".center(50, "-"))
# 大文件时, 推荐使用
# 读取文件, 将文件内容一行一行全部读出到内存, 且仅内存中, 仅保存一行, 大文件时, 内存消耗也不大
# 将文件指针, 指回文章首行, 否则无法读出
f.seek(0)
for line in f:
print(type(line), line.strip())
# 关闭文件
f.close()
# 输出:
<class 'str'> 这天,酒店老板正在大厅巡视。
<class 'str'> 来了一乞丐上前说道:“老板给个牙签行吗?”
<class 'str'> 老板给他一个打发走了。
<class 'str'> 一会儿,又来一个乞丐,也是来要牙签的。
<class 'str'> 老板心想现在这乞丐怎么不要饭改要牙签了?
<class 'str'> 也同样给他一个打发走了,没过多旧,又来一个乞丐。
<class 'str'> 老板对他说:“你也是来要牙签的吗?”
<class 'str'> 乞丐说:“有个人吐了,可我晚了一步,已经被前面两个乞丐把能吃的都吃了,现在只剩下汤了。你能给我个吸管吗?
-----------------------分隔符------------------------
<class 'str'> 这天,酒店老板正在大厅巡视。
<class 'str'> 来了一乞丐上前说道:“老板给个牙签行吗?”
<class 'str'> 老板给他一个打发走了。
<class 'str'> 一会儿,又来一个乞丐,也是来要牙签的。
<class 'str'> 老板心想现在这乞丐怎么不要饭改要牙签了?
<class 'str'> 也同样给他一个打发走了,没过多旧,又来一个乞丐。
<class 'str'> 老板对他说:“你也是来要牙签的吗?”
<class 'str'> 乞丐说:“有个人吐了,可我晚了一步,已经被前面两个乞丐把能吃的都吃了,现在只剩下汤了。你能给我个吸管吗?
5. 文件读操作汇总
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
# 打开文件,f称作文件句柄,国内使用的windows默认编码格式是gbk的,打开文件时,必须指定encoding="utf-8",否在无法打开
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 读第1行
first_line = f.readline()
print('first line:', first_line)
# 读第2行
second_line = f.readline()
print('second line:', second_line)
print('我是分隔线'.center(50, '-'))
# 读取剩下的所有内容,文件大时不要用
data = f.read()
# 打印文件
print(data)
# 关闭文件
f.close()
# 输出:
first line: 这天,酒店老板正在大厅巡视。
second line: 来了一乞丐上前说道:“老板给个牙签行吗?”
----------------------我是分隔线-----------------------
老板给他一个打发走了。
一会儿,又来一个乞丐,也是来要牙签的。
老板心想现在这乞丐怎么不要饭改要牙签了?
也同样给他一个打发走了,没过多旧,又来一个乞丐。
老板对他说:“你也是来要牙签的吗?”乞丐说:“有个人吐了,可我晚了一步,已经被前面两个乞丐把能吃的都吃了,现在只剩下汤了。你能给我个吸管吗?
二、文件基本操作 — 读写模式r+(常用)
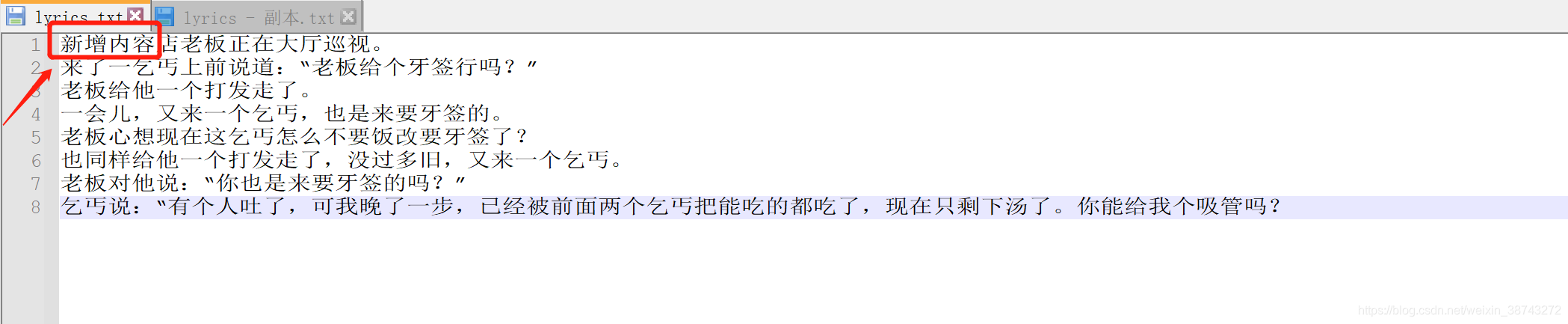
- write()不能实现插入写,它总是覆盖写或追加写;
- 如果文件一打开,直接write(),则从开头覆盖写;
- 如果文件一打开,用f.seek()指定文件指针位置,然后执行f.write()则从指针位置写(覆盖写);
- 如果文件打开后先执行了readline(), 然后再执行write(),实现的是追加写,此时,文件指针也会移动到文件末尾位置
- 更多详情,可参考:https://www.cnblogs.com/huahuayu/p/8093867.html
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r+",
encoding="utf-8")
# r+模式, 直接write, 实现从开头开始覆盖写
f.write("新增内容")
# 关闭文件
f.close()
如果文件一打开,直接write(),则从开头覆盖写
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r+",
encoding="utf-8")
# seek的参数是字节, 由于utf-8编码时, 一个中文字符为3字节, 此处应该会从第三个字符开始覆盖写
f.seek(6)
# r+模式, 如果文件一打开,用f.seek()指定文件指针位置,然后执行f.write()则从指针位置写(覆盖写)
f.write("新增内容")
# 关闭文件
f.close()

if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r+",
encoding="utf-8")
print("开始读文件前:%s" % f.tell())
# 如果文件打开后先执行了readline(), 然后再执行write(),实现的是追加写,此时,文件指针也会移动到文件末尾位置
print(f.readline())
print("读第一行后:%s" % f.tell())
# r+模式, 如果文件一打开,用f.seek()指定文件指针位置,然后执行f.write()则从指针位置写(覆盖写)
f.write("新增内容")
print("write追加写后:%s" % f.tell())
# 确认文件指针是否到达文件末尾
print(">>>%s<<<" % f.readline())
# 关闭文件
f.close()
# 输出:
开始读文件前:0
这天,酒店老板正在大厅巡视。
读第一行后:44
write追加写后:563
>>><<<
write新内容后的文件展示:write的内容会追加到文件最后,且调用write后,文件指针也会移动到文件末尾位置

三、文件基本操作 — 追加读模式a+(常用)
- 文件打开后起始指针为文件末尾,readline()将读不到数据;
- write()始终是追加写,即使将文件指针指到中间再执行write()仍然追加写
- 更多详情,可参考:https://www.cnblogs.com/huahuayu/p/8093867.html
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="a+",
encoding="utf-8")
print("开始读文件前:%s" % f.tell())
# 此处可以确认, a+打开文件时, 文件指针处于文件末尾
print(">>>%s<<<" % f.readline())
print("读第一行后:%s" % f.tell())
# 尝试使用seek方法, 将文件指针指向文件首部
f.seek(0)
print("使用seek方法将文件指针指向文件首部, 确认是否生效:%s" % f.tell())
f.write("新增内容")
# 再次确认文件指针位置
print(">>>%s<<<" % f.tell())
# 关闭文件
f.close()
# 输出:
开始读文件前:551
>>><<<
读第一行后:551
使用seek方法将文件指针指向文件首部, 确认是否生效:0
>>>563<<<

四、文件基本操作 — 写读模式w+(不常用)
- w+写读模式 == w写模式 + r读模式
- 使用写读模式,会新建文件,再将内容write到新文件中,write完成后,文件指针将移动到末尾,如果想要从头读取,需要使用f.seek(0)将文件指针移回到文件首字母位置,详见"写读模式w+_示例1"
- write的内容,只会往后追加,不会因为seek移动文件指针而修改前面已经write完成部分的内容,详见"写读模式w+_示例2"
写读模式w+_示例1
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="w+",
encoding="utf-8")
# 读3行
print(f.tell())
print(f.readline().rstrip())
print(f.tell())
print(f.readline().rstrip())
print(f.tell())
print(f.readline().rstrip())
# 写1行
print(f.tell())
# 写完后, 文件指针将移动到末尾
f.write("新增内容")
# 再读1行
print(f.tell())
print(f.readline().rstrip())
f.seek(0)
print(f.tell())
print(f.readline().rstrip())
# 关闭文件
f.close()
# 输出:
0
0
0
0
12
0
新增内容
写读模式w+_示例2
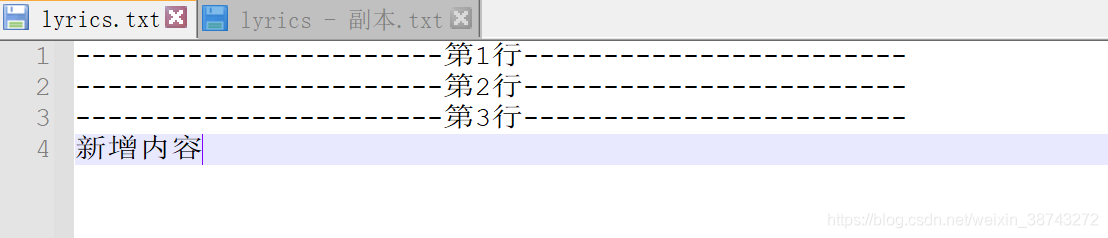
- write的内容,只会往后追加,不会因为seek移动文件指针而修改前面已经write完成部分的内容
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="w+",
encoding="utf-8")
# 写3行
print(f.tell())
f.write("%s\n" % "第1行".center(50, "-"))
print(f.tell())
f.write("%s\n" % "第2行".center(50, "-"))
print(f.tell())
f.write("%s\n" % "第3行".center(50, "-"))
# 移动文件指针到文件首部
f.seek(10)
# 读取首行
print(f.tell())
print(f.readline())
# 新增1行
f.write("新增内容")
# 关闭文件
f.close()
# 输出:
0
56
112
10
-------------第1行------------------------
write的内容,只会往后追加,不会因为seek移动文件指针而修改前面已经write完成部分的内容
五、文件基本操作 — 二进制格式_读模式rb(open时,不能用encoding参数)
- windows文件中\n会转为\r\n
- rb模式读文件场景:1. 网络传输(python3.x中,只能用二进制格式进行网络传输) 2. 下载视频等二进制文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="rb")
# 二进制读文件
print(f.readline())
print(f.readline())
print(f.readline())
# 关闭文件
f.close()
# 输出:
b'\xe8\xbf\x99\xe5\xa4\xa9\xef\xbc\x8c\xe9\x85\x92\xe5\xba\x97\xe8\x80\x81\xe6\x9d\xbf\xe6\xad\xa3\xe5\x9c\xa8\xe5\xa4\xa7\xe5\x8e\x85\xe5\xb7\xa1\xe8\xa7\x86\xe3\x80\x82\r\n'
b'\xe6\x9d\xa5\xe4\xba\x86\xe4\xb8\x80\xe4\xb9\x9e\xe4\xb8\x90\xe4\xb8\x8a\xe5\x89\x8d\xe8\xaf\xb4\xe9\x81\x93\xef\xbc\x9a\xe2\x80\x9c\xe8\x80\x81\xe6\x9d\xbf\xe7\xbb\x99\xe4\xb8\xaa\xe7\x89\x99\xe7\xad\xbe\xe8\xa1\x8c\xe5\x90\x97\xef\xbc\x9f\xe2\x80\x9d\r\n'
b'\xe8\x80\x81\xe6\x9d\xbf\xe7\xbb\x99\xe4\xbb\x96\xe4\xb8\x80\xe4\xb8\xaa\xe6\x89\x93\xe5\x8f\x91\xe8\xb5\xb0\xe4\xba\x86\xe3\x80\x82\r\n'
六、文件基本操作 — 二进制格式_读模式wb(open时,不能用encoding参数)
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="wb")
# 二进制写文件
f.write("hello binary\n".encode(encoding="utf-8"))
# 关闭文件
f.close()
wb写完的文件

七、文件基本操作 — 其他操作(常用操作)
1. tell()方法:获取文件指针位置,按照字符个数计算
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 返回当前文件指针位置tell(), 按照字符个数计算
print(type(f.tell()), f.tell())
first_line = f.readline()
print("-----first_line-----%s, %s" % (type(first_line), first_line))
# 返回当前文件指针位置tell(), 按照字符个数计算
print(type(f.tell()), f.tell())
second_line = f.readline()
print("-----second_line-----%s, >>>%s<<<" % (type(second_line), second_line))
f.close() # 关闭文件
# 输出:
<class 'int'> 0
-----first_line-----<class 'str'>, 这天,酒店老板正在大厅巡视。
<class 'int'> 44
-----second_line-----<class 'str'>, >>>来了一乞丐上前说道:“老板给个牙签行吗?”
<<<
2. seek()方法:将文件指针指到指定位置,按照字符个数计算,0代表文件首字母
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 返回当前文件指针位置tell(), 按照字符个数计算
print(type(f.tell()), f.tell())
first_line = f.readline()
print("-----first_line-----%s, %s" % (type(first_line), first_line))
# 返回当前文件指针位置tell(), 按照字符个数计算
print(type(f.tell()), f.tell())
second_line = f.readline()
print("-----second_line-----%s, >>>%s<<<" % (type(second_line), second_line))
# 使用seek, 指回文件首字母, 首字母位置为0, 重新读文件
f.seek(0)
print(type(f.tell()), f.tell())
first_line = f.readline()
print("-----first_line-----%s, %s" % (type(first_line), first_line))
f.close() # 关闭文件
# 输出:
<class 'int'> 0
-----first_line-----<class 'str'>, 这天,酒店老板正在大厅巡视。
<class 'int'> 44
-----second_line-----<class 'str'>, >>>来了一乞丐上前说道:“老板给个牙签行吗?”
<<<
<class 'int'> 0
-----first_line-----<class 'str'>, 这天,酒店老板正在大厅巡视。
3. read()/readline()/readlines()带参数/不带参数区别
可参考:https://blog.youkuaiyun.com/sha_ka/article/details/104276513
f.read(size) 可用于读取文件内容,它会读取一些数据,并返回字符串(文本模式),或字节串对象(在二进制模式下)。 size 是可选的数值参数。省略 size 或 size 为负数时,读取并返回整个文件的内容;文件大小是内存的两倍时,会出现问题。size 取其他值时,读取并返回最多 size 个字符(文本模式)或 size 个字节(二进制模式)。如已到达文件末尾,f.read() 返回空字符串(’’)
1)read(size)方法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 读取16个"utf-8"编码的字符,本行读完后还不够,继续读取下一行数据,直至读取16个字符
print(f.read(16))
# 关闭文件
f.close()
# 输出:
这天,酒店老板正在大厅巡视。
来
2)readline(size)方法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 读取16个"utf-8"编码的字符,如果超过当前行中字符数,则读取完本行数据,不继续读下一行
print(f.readline(16))
# 关闭文件
f.close()
# 输出:
这天,酒店老板正在大厅巡视。
3)readlines(size)方法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 读取16个"utf-8"编码的字符,读完一行发现不足16个字符,则再读取下一行,直至读取总字符数比16字符多,才停止,并将读取行以list形式返回
print(f.readlines(16))
# 关闭文件
f.close()
# 输出:
['这天,酒店老板正在大厅巡视。\n', '来了一乞丐上前说道:“老板给个牙签行吗?”\n']
4. flush()方法:会将缓存中的内容,强制刷到硬盘中
- 写文件时,会将write的内容暂存在内存的缓存中,而不是每写一行就会往硬盘上刷(硬盘读写速度<内存读写速度),缓存有大小,只要write的内容达到缓存大小,即缓存满了,才会一次性将缓存中内容刷到硬盘中;
- 所以,我们在write编写文件时,并不是write一行,就会往硬盘中刷一行,而是会好多行好多行地往硬盘中刷;
- flush方法:会将缓存中的内容,强制刷到硬盘中,例如:存钱…
flush方法_示例1
1)只write写内容,在没有强制flush时,write的内容没有同步存到文件中

2)write写内容,且强制flush后,write的内容已经同步存到文件中

flush方法_示例2(简易版进度条)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
import sys
import time
if __name__ == '__main__':
for i in range(20):
sys.stdout.write("#")
# 强制flush缓存区中内容,否则可能会等缓存区满后,一次性打印
sys.stdout.flush()
time.sleep(0.1)
5. truncate()方法:用于截断文件并返回截断的字节长度
- Python 文件 truncate() 方法:用于截断文件并返回截断的字节长度。
- 指定长度的话,就从文件的开头开始截断指定长度,其余内容删除;不指定长度的话,就从文件开头开始截断到当前位置,其余内容删除。
truncate()方法_示例1:不指定长度的话,就从文件开头开始截断到当前位置,其余内容删除
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="a",
encoding="utf-8")
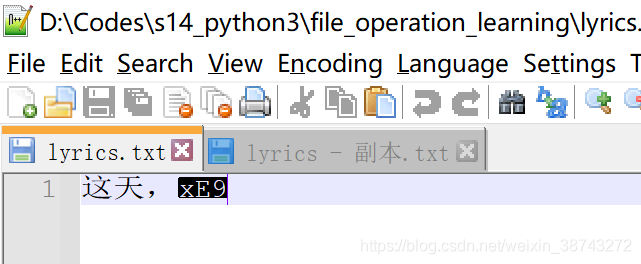
# truncate方法, 不指定长度的话,就从文件开头开始截断到当前位置,其余内容删除
f.seek(10)
f.truncate()
# 关闭文件
f.close()
截断后的文件:
truncate()方法_示例2:从文件开始位置截断10个字节
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="a",
encoding="utf-8")
# 如果写参数, 会清空文件内容, 则会从文件首部, 开始截断10个字节
f.truncate(10)
# 关闭文件
f.close()
截断后的文件:
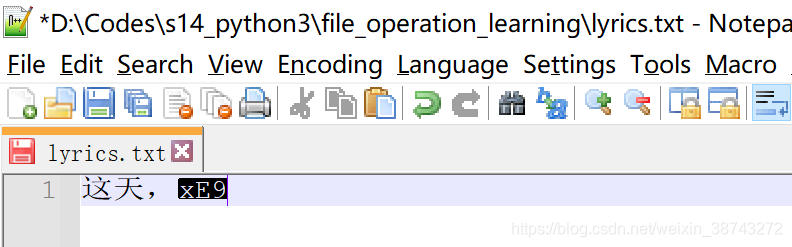
truncate()方法_示例3:从文件开始位置截断20个字节,不受seek影响
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="a",
encoding="utf-8")
# 将文件指针移动到10的位置
f.seek(10)
# 只从文件首部, 开始截断指定个数字节, 不受文件指针的影响
f.truncate(20)
# 关闭文件
f.close()
截断后的文件:
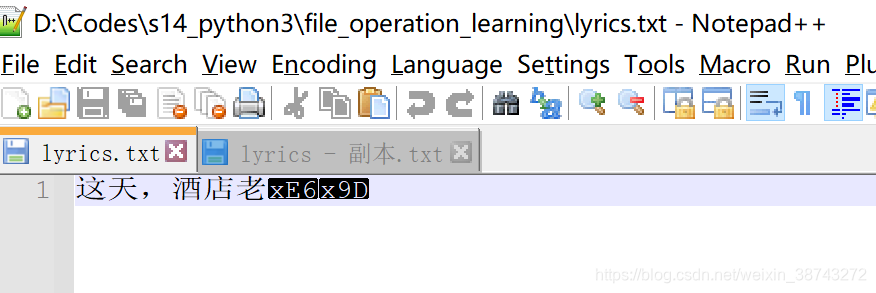
八、文件基本操作 — 其他操作(不常用操作)
1. detach()方法:文件编辑过程中,更换文件编码格式
2. encoding()方法:打印当前文件,编码格式
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 打印当前文件编码格式
print("%s, %s" %(type(f.encoding), f.encoding))
# 关闭文件
f.close()
# 输出:
<class 'str'>, utf-8
3. buffer()方法
4. errors()方法:用于异常处理
5. fileno():返回文件句柄在内存中的编号,调用操作系统接口获取的
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Mason
if __name__ == '__main__':
f = open(file=r'D:\Codes\s14_python3\file_operation_learning\lyrics.txt',
mode="r",
encoding="utf-8")
# 返回文件句柄在内存中的编号
print("%s, %s" %(type(f.fileno()), f.fileno()))
# 关闭文件
f.close()
# 输出:
<class 'int'>, 3
6. name():以str类型,返回文件名称
7. isatty():判断当前文件是否为终端设备,如打印机等,底层开发时才会用到
8. seekable():判断是否可以使用seek方法
- 如tty文件(终端设备文件)是无法将移动文件指针的
9. readable():判断文件是否可读
10. writeable():判断文件是否可写
11. closed():判断文件是否已关闭
12. readinto():可以直接将二进制数据写入到可变缓冲区中,很少使用
- python的file对象拥有readinto方法,可以直接将二进制数据写入到可变缓冲区中,实践中,写入 bytearray , bytearray 是字节数组,这个数组有多大,readinto方法就尝试将多少内容写入其中。通常,我们使用open函数打开一个文件,读取内容时,使用的都是read,readline,readlines,所返回的都是字符串,几乎不会使用到readinto方法。这是因为,我们所做的事情都偏向于业务应用,但如果你向更底层的技术去学习,就会认识到,对于数据的处理,我们需要更接近二进制的方式。
- 更多详情,可参考链接:http://coolpython.net/informal_essay/20-06/socket_readinto.html
九、文件基本操作 — with语句



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









