







找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
所有数字都是正整数。
解集不能包含重复的组合。
示例 1:
输入: k = 3, n = 7
输出: [[1,2,4]]
示例 2:
输入: k = 3, n = 9
输出: [[1,2,6], [1,3,5], [2,3,4]]class Solution:
def combinationSum3(self, k: int, n: int) -> List[List[int]]:
res=[]
def dfs(count,i,tmp,target):
if count==k:
if target==0:
res.append(tmp)
return
for j in range(i,10):
if j>target:
break
dfs(count+1,j+1,tmp+[j],target-j) #此处应该j+1 ,如果选用J,会导致结果由重复数字
dfs(0,1,[],n)
return res
0,1,,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
示例 1:
输入: n = 5, m = 3
输出: 3
示例 2:
输入: n = 10, m = 17
输出: 2
class Solution:
def lastRemaining(self, n: int, m: int) -> int:
res=[i for i in range(n)]
lp=0
while n>1:
lp=(lp+m-1)%n
res.pop(lp)
n-=1
return res[0]给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
示例 1:
输入:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
输出: [1,2,3,6,9,8,7,4,5]
示例 2:
输入:
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12]
]
输出: [1,2,3,4,8,12,11,10,9,5,6,7]
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix:
return []
res=[]
x,y,count,=0,0,0
rows,cols=len(matrix),len(matrix[0])
label=set()
dx,dy=[0,1,0,-1],[1,0,-1,0]
for i in range(rows*cols):
#移动总次数
res.append(matrix[x][y])
label.add((x,y))
next_x,next_y=x+dx[count],y+dy[count]
if 0<=next_x<rows and 0<=next_y<cols and (next_x,next_y) not in label:
x,y=next_x,next_y
else:
count=(count+1)%4
x,y=x+dx[count],y+dy[count]
return res
在一排树中,第 i 棵树产生 tree[i] 型的水果。
你可以从你选择的任何树开始,然后重复执行以下步骤:
把这棵树上的水果放进你的篮子里。如果你做不到,就停下来。
移动到当前树右侧的下一棵树。如果右边没有树,就停下来。
请注意,在选择一颗树后,你没有任何选择:你必须执行步骤 1,然后执行步骤 2,然后返回步骤 1,然后执行步骤 2,依此类推,直至停止。
你有两个篮子,每个篮子可以携带任何数量的水果,但你希望每个篮子只携带一种类型的水果。
用这个程序你能收集的水果总量是多少?
示例 1:
输入:[1,2,1]
输出:3
解释:我们可以收集 [1,2,1]。
示例 2:
输入:[0,1,2,2]
输出:3
解释:我们可以收集 [1,2,2].
如果我们从第一棵树开始,我们将只能收集到 [0, 1]。
示例 3:
输入:[1,2,3,2,2]
输出:4
解释:我们可以收集 [2,3,2,2].
如果我们从第一棵树开始,我们将只能收集到 [1, 2]。
示例 4:
输入:[3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:我们可以收集 [1,2,1,1,2].
如果我们从第一棵树或第八棵树开始,我们将只能收集到 4 个水果。
class Solution:
def totalFruit(self, tree: List[int]) -> int:
label=0
count=1
dic={tree[0]}
res=0
for i in range(1,len(tree)):
if tree[i] in dic:
count+=1
elif len(dic)<2:
dic.add(tree[i])
count+=1
else:
res=max(count,res)
count=i-label+1 #集合加入新元素,因此count+1
dic={tree[i-1],tree[i]}
if tree[i]!=tree[i-1]:
label=i
return max(count,res)给出 N 名运动员的成绩,找出他们的相对名次并授予前三名对应的奖牌。前三名运动员将会被分别授予 “金牌”,“银牌” 和“ 铜牌”("Gold Medal", "Silver Medal", "Bronze Medal")。
(注:分数越高的选手,排名越靠前。)
示例 1:
输入: [5, 4, 3, 2, 1]
输出: ["Gold Medal", "Silver Medal", "Bronze Medal", "4", "5"]
解释: 前三名运动员的成绩为前三高的,因此将会分别被授予 “金牌”,“银牌”和“铜牌” ("Gold Medal", "Silver Medal" and "Bronze Medal").
余下的两名运动员,我们只需要通过他们的成绩计算将其相对名次即可。class Solution:
def findRelativeRanks(self, nums: List[int]) -> List[str]:
rank_map = {1:"Gold Medal", 2:'Silver Medal', 3:'Bronze Medal'}
rank_dic = {score: rank+1 for rank,score in enumerate(sorted(nums, reverse=True))}
res=[]
for index in nums:
if rank_dic[index] in rank_map:
res.append(rank_map[rank_dic[index]])
else:
res.append(str(rank_dic[index]))
return res
给你一个字符串 s ,它只包含三种字符 a, b 和 c 。
请你返回 a,b 和 c 都 至少 出现过一次的子字符串数目。
示例 1:
输入:s = "abcabc"
输出:10
解释:包含 a,b 和 c 各至少一次的子字符串为 "abc", "abca", "abcab", "abcabc", "bca", "bcab", "bcabc", "cab", "cabc" 和 "abc" (相同字符串算多次)。
示例 2:
输入:s = "aaacb"
输出:3
解释:包含 a,b 和 c 各至少一次的子字符串为 "aaacb", "aacb" 和 "acb" 。
示例 3:
输入:s = "abc"
输出:1
class Solution:
def numberOfSubstrings(self, s: str) -> int:
#利用滑窗和规律
lp,rp=0,2
count=0
n=len(s)
if n<3:
return 0
while lp<n-2:
tmp=s[lp:rp+1]
if 'a' in tmp and 'b' in tmp and 'c' in tmp:
count+=n-rp #末尾统计带‘abc'的
lp+=1
else:
rp+=1
if rp==n:
break
return count返回与给定先序遍历 preorder 相匹配的二叉搜索树(binary search tree)的根结点。
(回想一下,二叉搜索树是二叉树的一种,其每个节点都满足以下规则,对于 node.left 的任何后代,值总 < node.val,而 node.right 的任何后代,值总 > node.val。此外,先序遍历首先显示节点的值,然后遍历 node.left,接着遍历 node.right。)
示例:
输入:[8,5,1,7,10,12]
输出:[8,5,10,1,7,null,12]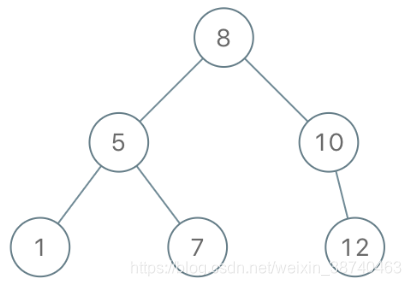
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def bstFromPreorder(self, preorder: List[int]) -> TreeNode:
if len(preorder)==0:
return None
root=TreeNode(preorder[0])
# for i in range(len(preorder)):
# if preorder[i]>root.val:
# lp=preorder[1:i]
# rp=preorder[i:]
lp=[index for index in preorder if index>root.val]
rp=[index for index in preorder if index<root.val]
root.left=self.bstFromPreorder(rp)
root.right=self.bstFromPreorder(lp)
return root 给定一个非空且只包含非负数的整数数组 nums, 数组的度的定义是指数组里任一元素出现频数的最大值。
你的任务是找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
示例 1:
输入: [1, 2, 2, 3, 1]
输出: 2
解释:
输入数组的度是2,因为元素1和2的出现频数最大,均为2.
连续子数组里面拥有相同度的有如下所示:
[1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2]
最短连续子数组[2, 2]的长度为2,所以返回2.
示例 2:
输入: [1,2,2,3,1,4,2]
输出: 6from collections import Counter
class Solution:
def findShortestSubArray(self, nums: List[int]) -> int:
counter=Counter(nums)
index=max(counter.values())
if index==1:
return 1
lis=[i for i,j in counter.items() if j==index]
res=float('inf')
for key in lis:
lp,rp=0,len(nums)-1
while key!=nums[lp]:
lp+=1
while key!=nums[rp]:
rp-=1
res=min(res,rp-lp+1)
return res爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。
最初,黑板上有一个数字 N 。在每个玩家的回合,玩家需要执行以下操作:
选出任一 x,满足 0 < x < N 且 N % x == 0 。
用 N - x 替换黑板上的数字 N 。
如果玩家无法执行这些操作,就会输掉游戏。
只有在爱丽丝在游戏中取得胜利时才返回 True,否则返回 false。假设两个玩家都以最佳状态参与游戏。
示例 1:
输入:2
输出:true
解释:爱丽丝选择 1,鲍勃无法进行操作。
示例 2:
输入:3
输出:false
解释:爱丽丝选择 1,鲍勃也选择 1,然后爱丽丝无法进行操作。如果N是奇数,因为奇数的所有因数都是奇数,因此 N 进行一次 N-x 的操作结果一定是偶数,所以如果 a 拿到了一个奇数,那么轮到 b 的时候,b拿到的肯定是偶数,这个时候 b 只要进行 -1, 还给 a 一个奇数,那么这样子b就会一直拿到偶数,到最后b一定会拿到最小偶数2,a就输了。
所以如果游戏开始时Alice拿到N为奇数,那么她必输,也就是false。如果拿到N为偶数,她只用 -1,让bob 拿到奇数,最后bob必输,结果就是true。
class Solution:
def divisorGame(self, N: int) -> bool:
给出一个区间的集合,请合并所有重叠的区间。
示例 1:
输入: [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入: [[1,4],[4,5]]
输出: [[1,5]]
解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
if not intervals:
return []
intervals=sorted(intervals,key=lambda x:x[0])
tmp=intervals[0]
res=[]
for i in range(1,len(intervals)):
if intervals[i][0]>tmp[1]:
res.append(tmp)
tmp=intervals[i]
else:
if tmp[1]<=intervals[i][1]:
if tmp[0]>intervals[i][0]:
tmp=[intervals[i][0],intervals[i][1]]
else:
tmp=[tmp[0],intervals[i][1]]
res.append(tmp)
return res
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
示例 1:
输入:
"bbbab"
输出:
4
一个可能的最长回文子序列为 "bbbb"。
示例 2:
输入:
"cbbd"
输出:
2
一个可能的最长回文子序列为 "bb"。
class Solution:
def longestPalindromeSubseq(self, s: str) -> int:
n=len(s)
if n==1:
return 1
dp=[[0]*n for i in range(n)]
for i in range(n):
dp[i][i]=1
for i in range(n-1,-1,-1):
for j in range(i+1,n):
if s[i]==s[j]:
dp[i][j]=dp[i+1][j-1]+2
else:
dp[i][j]=max(dp[i+1][j],dp[i][j-1])
return dp[0][n-1]
在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
示例 1:
输入:nums = [3,4,3,3]
输出:4
示例 2:
输入:nums = [9,1,7,9,7,9,7]
输出:1
class Solution:
def singleNumber(self, nums):
res = 0
for i in range(32):
cnt = 0 # 记录当前 bit 有多少个1
bit = 1 << i # 记录当前要操作的 bit
for num in nums:
if num & bit != 0: #按位与,判单当前位1的个数
cnt += 1
if cnt % 3 != 0:
print(res |bit)
res |= bit #当满足当前位1的个数是不是3的整数倍时,说明目标数在当前位为1,即用1不断与当前位或,老获取目标数
return res - 2 ** 32 if res > 2 ** 31 - 1 else res
Solution().singleNumber([4,4,4,3])[56-数组中除了两个元素只出现一次,剩下所有元素出现了两次,找到这两个元素]
我们进行一次全员异或操作,得到的结果就是那两个只出现一次的不同的数字的异或结果。
我们刚才讲了异或的规律中有一个任何数和本身异或则为0, 因此我们的思路是能不能将这两个不同的数字分成两组 A 和 B。分组需要满足两个条件. (1)两个只出现一次的数字分成不同组 (2)相同的数字分成相同组。这样每一组的数据进行异或即可得到那两个数字。
问题的关键点是我们怎么进行分组呢:由于异或的性质是,同一位相同则为 0,不同则为 1. 我们将所有数字异或的结果一定不是 0,也就是说至少有一位是 1. 我们从右向左找到第一个1出现的位置 idx = 1; while idx & res == 0: idx = idx << 1,分组的依据就来了,遍历nums,你取的那一位是 0 分成 1 组,那一位是 1 的分成一组。这样肯定能保证 相同的数字分成相同组, 不同的那两个数字也会被分成不同组。
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
res = 0
for i in nums:
res = res^i
idx = 1
while idx & res == 0: #找到两个不同数字,最小位上的区别(1与0) 例如 011 与 1001 则在10位上两个数出现第一次区别
idx = idx << 1
a,b = 0,0
for i in nums:
if i & idx==0: #利用10位将数组分开,分别得到两个数字
a = a^i
else:
b = b^i
return([a,b])
Solution().singleNumber([4,3,4,5])
树总结:
二叉树的前序遍历
给定一个二叉树,返回它的 前序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,2,3]
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
res=[]
def trival(root,res):
if not root:
return
res.append(root.val)
trival(root.left,res)
trival(root.right,res)
return res
trival(root,res)
return res
二叉树的层次遍历
定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:
return []
lis=[root]
res=[[root.val]]
while lis:
tmp=[]
tmp1=[]
for index in lis:
if index.left:
tmp.append(index.left)
tmp1.append(index.left.val)
if index.right:
tmp.append(index.right)
tmp1.append(index.right.val)
lis=tmp
if tmp1:
res.append(tmp1)
return res
递归:
“自顶向下” 的解决方案
“自顶向下” 意味着在每个递归层级,我们将首先访问节点来计算一些值,并在递归调用函数时将这些值传递到子节点。 所以 “自顶向下” 的解决方案可以被认为是一种前序遍历。
如,思考这样一个问题:给定一个二叉树,请寻找它的最大深度。
我们知道根节点的深度是1。 对于每个节点,如果我们知道某节点的深度,那我们将知道它子节点的深度。 因此,在调用递归函数的时候,将节点的深度传递为一个参数,那么所有的节点都知道它们自身的深度。 而对于叶节点,我们可以通过更新深度从而获取最终答案
“自底向上” 的解决方案
“自底向上” 是另一种递归方法。 在每个递归层次上,我们首先对所有子节点递归地调用函数,然后根据返回值和根节点本身的值得到答案。 这个过程可以看作是后序遍历的一种。
继续讨论前面关于树的最大深度的问题,但是使用不同的思维方式:对于树的单个节点,以节点自身为根的子树的最大深度x是多少?
如果我们知道一个根节点,以其左子节点为根的最大深度为l和以其右子节点为根的最大深度为r,我们是否可以回答前面的问题? 当然可以,我们可以选择它们之间的最大值,再加上1来获得根节点所在的子树的最大深度。 那就是 x = max(l,r)+ 1对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root:
return True
def helper(left,right):
if not left and not right:
return True
if not left or not right:
return False
if left.val==right.val:
return helper(left.left,right.right) and helper(right.left,left.right)
return False
return helper(root.left,root.right)
迭代法
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root:
return True
def helper(left,right):
stack=[left,right]
while stack:
left=stack.pop()
right=stack.pop()
if not left and not right:
continue
if (not left or not right) or (left.val!=right.val):
return False
stack+=[left.left,right.right,left.right,right.left]
return True
return helper(root.left,root.right)填充每个节点的下一个右侧节点指针
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
class Solution:
def connect(self, root: 'Node') -> 'Node':
if not root:
return root
if root.right:
root.left.next=root.right
if root.next:
root.right.next=root.next.left #A左子树的右子节点 指向 A右子树的左子节点
self.connect(root.left)
self.connect(root.right)
return root
填充每个节点的下一个右侧节点指针 II
给定一个二叉树
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
进阶:
你只能使用常量级额外空间。
使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。示例:

class Solution:
def dfs(self,root):
if not root:
return None
while root: #寻找此时root最右边的一个子树
if root.left:
return root.left
if root.right:
return root.right
root=root.next
return None
def connect(self, root: 'Node') -> 'Node':
if not root:
return None
if root.left:
if root.right:
root.left.next=root.right
else:
root.left.next=self.dfs(root.next)
if root.right:
root.right.next=self.dfs(root.next)
self.connect(root.right)
# 注意这里要先递归右子树,因为如果父节点右子树不存在的话,左子树的next需要找父节点next的子树,因此必须先把右边的next关系理顺
self.connect(root.left)
return root
路经总和
路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。class Solution:
def hasPathSum(self, root: TreeNode, sum: int) -> bool:
if not root:
return False
sum-=root.val
if sum==0 and not root.left and not root.right:
return True
else:
return self.hasPathSum(root.left,sum) or self.hasPathSum(root.right,sum)给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
class Solution:
def pathSum(self, root: TreeNode, sum: int) -> List[List[int]]:
self.res = []
def dfs(root,tmp,tol):
if not root:
return
# tmp+=[root.val]
tol-=root.val
if not root.left and not root.right and tol== 0:
tmp += [root.val]
self.res.append(tmp)
dfs(root.left,tmp+[root.val], tol)
dfs(root.right,tmp+[root.val], tol )
dfs(root, [], sum)
return self.res


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









