



 本文详细介绍了Apache Hive数据仓库的部署步骤,包括下载、配置环境变量、安装MySQL及驱动,以及配置hive-site.xml。此外,还讲解了Hive的架构、数据存储方式和SQL操作,以及如何通过元数据管理实现大数据的统计分析。
本文详细介绍了Apache Hive数据仓库的部署步骤,包括下载、配置环境变量、安装MySQL及驱动,以及配置hive-site.xml。此外,还讲解了Hive的架构、数据存储方式和SQL操作,以及如何通过元数据管理实现大数据的统计分析。
介绍——官网:hive.apache.org
(1)hive介绍
Apache Hive数据仓库
有助于使用SQL读取,编写和管理驻留在分布式存储中的大型数据集,SQL来完成大数据的统计分析
目前市面上使用多的分布式存储
distributed storage:HDFS S3 OSS COS
hdfs://hadoop000:8020/xxxxx
s3a://…
s3n://
访问Hive的方式:A command line tool and JDBC driver
(2)hive作用
Apache社区的顶级项目
Hive:facebook 解决海量的结构化日志的统计问题
刚开始时是作为Hadoop项目的一个子项目的,后面才单独成为一个项目
Hive是构建在Hadoop之上的数据仓库 适合处理离线
Hive是一个客户端,不是一个集群,把SQL提交到Hadoop集群上去运行
Hive是一个类SQL的框架, HQL和SQL的关系
Hive职责:SQL ==> MR/Spark
Hive底层支持的引擎:MR/Spark/Tez
***** 统一的元数据管理常用框架,
可互相关联,是由于基于元数据管理
SQL on Hadoop : Spark SQL/Hive/Impala/Presto
一、部署架构
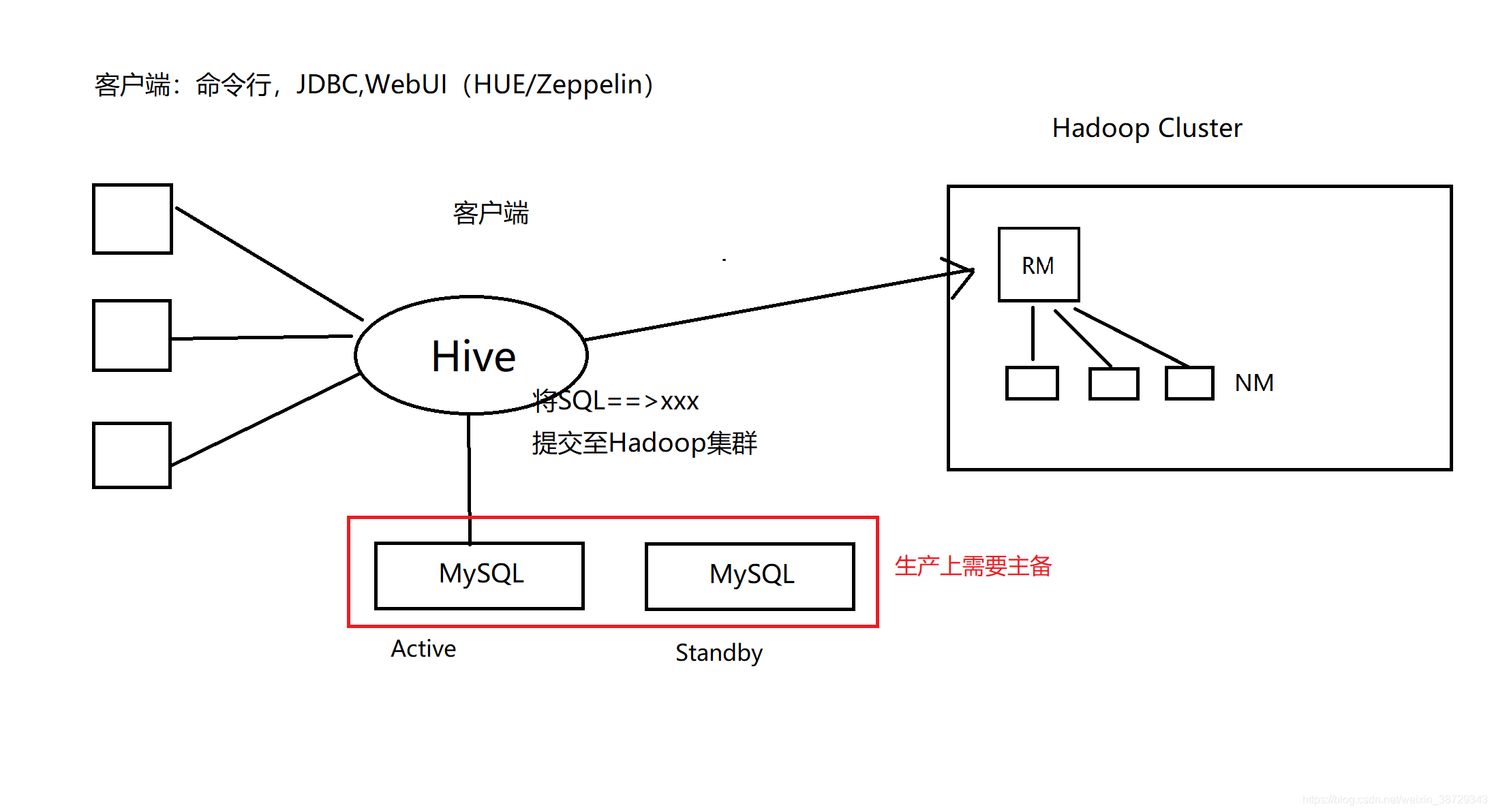 元数据:描述数据的数据
元数据:描述数据的数据
例如mysql里面存很多行多列的数据,这张表里面表名、表字段类型
Hive数据分为两部分HDFS + 元数据(MySQL)
people.txt + people(id:int,name:string,age:int)
(1)为什么能用SQL来进行大数据统计分析?
因为有元数据的支撑,我们知道HDFS上的数据每一列字段名是什么,
字段类型是什么,数据在HDFS的什么位置
(2)mysql需要主备
二:Hive部署
1)下载:http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz
2)解压: tar -zvxf hive-1.1.0-cdh5.15.1.tar.gz -C ~/app/
3)将HIVE_HOME配置到系统环境变量(~/.bash_profile)
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.15.1
export PATH=
H
I
V
E
H
O
M
E
/
b
i
n
:
HIVE_HOME/bin:
HIVEHOME/bin:PATH
4)将MySQL驱动拷贝到$HIVE_HOME/lib
5)安装MySQL
6)修改hive的配置文件 hive-site.xml
7)启动hive
#将下载好的Hive包下载到software文件夹并解压
[hadoop@hadoop001 software]$ ll
total 429956
drwxr-xr-x. 15 hadoop hadoop 4096 Jul 6 17:59 hadoop-2.6.0-cdh5.7.0
-rw-r--r--. 1 hadoop hadoop 311585484 Jul 2 15:24 hadoop-2.6.0-cdh5.7.0.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Aug 9 2018 hive-1.1.0-cdh5.15.1
-rw-r--r--. 1 hadoop hadoop 128670894 Jul 16 13:25 hive-1.1.0-cdh5.15.1.tar.gz
#将解压文件创建软连接到app目录下
[hadoop@hadoop001 ~]$ cd /home/hadoop/software
[hadoop@hadoop001 software]$ ln -s /home/hadoop/software/hive-1.1.0-cdh5.15.1 /home/hadoop/app/hive
[hadoop@hadoop001 software]$ cd
[hadoop@hadoop001 ~]$ cd /home/hadoop/app/
[hadoop@hadoop001 app]$ ll
total 0
lrwxrwxrwx. 1 hadoop hadoop 43 Jul 2 10:36 hadoop -> /home/hadoop/software/hadoop-2.6.0-cdh5.7.0
lrwxrwxrwx. 1 hadoop hadoop 42 Jul 16 13:52 hive -> /home/hadoop/software/hive-1.1.0-cdh5.15.1
[hadoop@hadoop001 app]$ cd hive
[hadoop@hadoop001 hive]$ ll
#配置Hive的环境变量vi ~/.bash_profile
[hadoop@hadoop001 hive]$ cat ~/.bash_profile
...
export HIVE_HOME=/home/hadoop/app/hive
export PATH=${HIVE_HOME}/bin:$PATH
...
#官网下载MySQL官网驱动
#解压后将驱动拷贝到$HIVE_HOME/lib
[hadoop@hadoop001 lib]$ ll mysql*
-rw-r--r--. 1 hadoop hadoop 872303 Jul 16 19:08 mysql-connector-java-5.1.27-bin.jar
#Hive没有hive-site.xml文件,可以将hdfs-site.xml文件cp至hive的conf目录下
#将cp的文件重新命名,并调整参数
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop001:3306/ruozedata_d7?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>
#启动Hive
[hadoop@hadoop001 ~]$ hive
which: no hbase in (/home/hadoop/app/hive/bin:/home/hadoop/app/hadoop/bin:/home/hadoop/app/hadoop/sbin:/usr/local/mysql/bin:/usr/java/jdk1.8.0_45/bin:/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin)
19/07/16 22:52:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Logging initialized using configuration in jar:file:/home/hadoop/software/hive-1.1.0-cdh5.15.1/lib/hive-common-1.1.0-cdh5.15.1.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive>
完成Hive的部署
三、Hive
1、(1)Hive的文件位置
默认的Hive数据存放在HDFS上:/user/hive/warehouse
/user/hive/warehouse这个路径是有参数是可以进行控制的,
Hive数据存放的HDFS的路径,如果要调整,就把这个参数设置到hive-site.xml中去
<property>
<name>hive.metastore.warehouse.dir</name>
<value>xxxx</value>
</property>
default数据库对应的目录是hive.metastore.warehouse.dir
所以创建一张表,Hive中的表其实对应的就是HDFS上的一个目录,默认文件的名字就是tablename
(2)Hive的信息配置
hive的信息是可以配置在hive-site.xml里面 全局
同时命令行中也能设置 当前session
第一种方式:
以set hive.cli.print.current.db为例,在命令行里面设置用set,可调整 =
set 参数; 查看当前参数的值
set 参数=值; 真正的设置参数对应的值
第二种方式:
了解 hive --hiveconf k=v --hiveconf k=v
(3)Hive的存储方式:
Hive中的数据在HDFS上都是以文件夹/文件的方式存储的
database
table
partition
bucket
注:location默认的是在hdfs上use/werehost上面,自己指定的是不带DB的,需要创建
例如:create table xxx(id int,name string)
(4)删除:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
DROP DATABASE IF EXISTS d7_hive2 CASCADE;
数据库删除的时候,只要库下有表,默认就不能删除
CASCADE慎用
2、SQL:DDL DML
DDL:数据定义语言,例如创建修改删除
DDL:create delete alter
DML: SQL
每一个SQL语句底层都有相应的元数据信息做关联
在Hive里面创建的表在mysql中查看
mysql> use ruozedata_d7
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_ruozedata_d7 |
+---------------------------+
| bucketing_cols |
| cds |
| columns_v2 |
| database_params |
| dbs |
| func_ru |
| funcs |
| global_privs |
| part_col_stats |
| partition_key_vals |
| partition_keys |
| partition_params |
| partitions |
| roles |
| sd_params |
| sds |
| sequence_table |
| serde_params |
| serdes |
| skewed_col_names |
| skewed_col_value_loc_map |
| skewed_string_list |
| skewed_string_list_values |
| skewed_values |
| sort_cols |
| tab_col_stats |
| table_params |
| tbls |
| version |
+---------------------------+
29 rows in set (0.00 sec)
查看数据库在HDFS对应的文件路径
mysql> select * from dbs;
+-------+-----------------------+-------------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://hadoop001:9000/user/hive/warehouse | default | public | ROLE |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+
1 row in set (0.00 sec)
查看HIVE版本信息
mysql> select * from version;
+--------+-----------------+-------------------+-----------------------------------+
| VER_ID | SCHEMA_VERSION | SCHEMA_VERSION_V2 | VERSION_COMMENT |
+--------+-----------------+-------------------+-----------------------------------+
| 1 | 1.1.0-cdh5.15.1 | NULL | Set by MetaStore hadoop@10.9.0.62 |
+--------+-----------------+-------------------+-----------------------------------+
1 row in set (0.00 sec)
查看对应的表数据
mysql> select * from tbls;
+--------+-------------+-------+------------------+--------+-----------+-------+-----------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+--------+-----------+-------+-----------+---------------+--------------------+--------------------+
| 1 | 1563267428 | 1 | 0 | hadoop | 0 | 1 | ruozedata | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+--------+-----------+-------+-----------+---------------+--------------------+--------------------+
1 row in set (0.00 sec)
查看对应表的字段信息
mysql> select * from columns_v2;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | age | int | 2 |
| 1 | NULL | id | int | 0 |
| 1 | NULL | name | string | 1 |
+-------+---------+-------------+-----------+-------------+
3 rows in set (0.00 sec)

















 3316
3316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









