






背景:
大模型体现在模型太大单卡无法满足,因此引入分布式。有些分布式算法如Tensor Parallelism存在通信与计算的数据依赖,在编译器层面消减这种依赖,重复利用硬件的通信与计算并行资源,可以达到更好的性能。
Async-TP算法层面

1、Async-TP算法核心在于拆散通信操作,人为创造通信与计算的并行空间。
与Megatron的SP+TP的组合相比:将allgather\reduce_scatter通信拆分为局部的send\recv,并手动做reduce(累加)。
2、torch.compile能够开启pass config._micro_pipeline_tp,在编译时能够自动寻找Async-TP的优化点,并完成自动的替换
CUDA Async-TP优化-竞争的P2P内存搬运
最native的算法并非能默认获得好的性能,存在如下问题:
问题:
1、NCCL send/recv kernel使用SMs,导致 Matmul的可用SM的减少,性能下降。事实上计算、通信相互抢占SM资源影响
同时计算分块的长尾,也会加剧这一点。
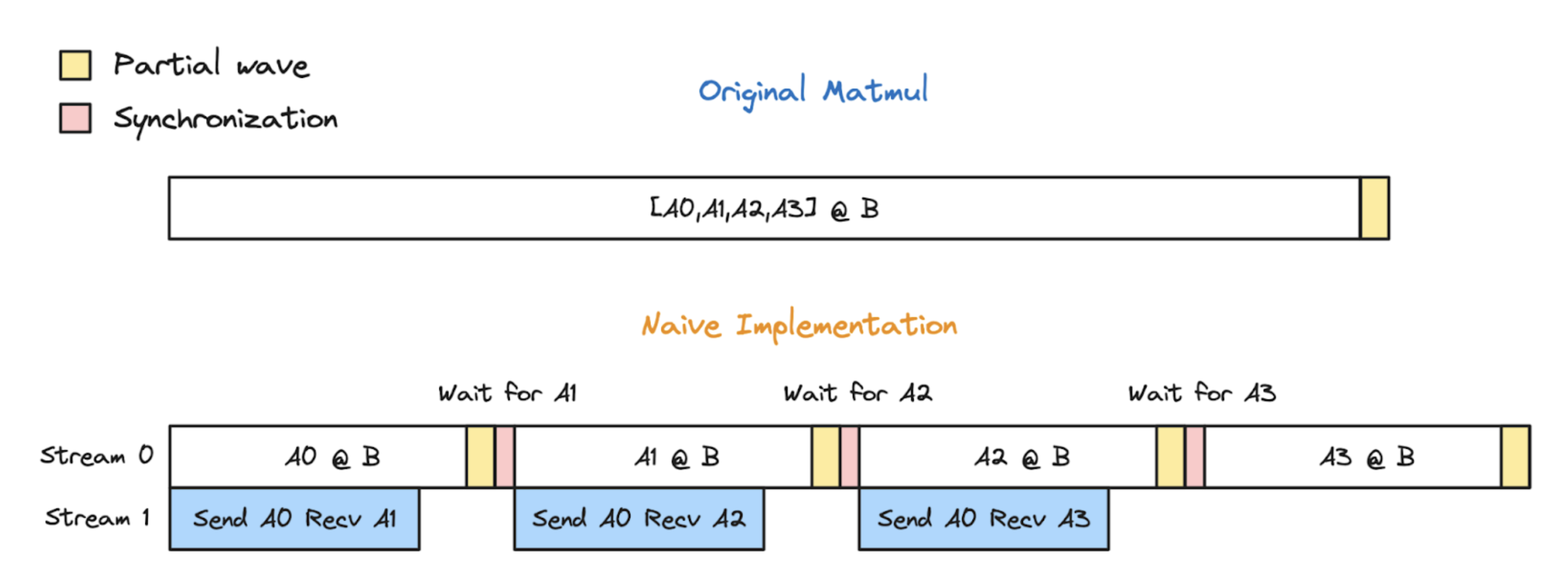
2、send/recv需要双向确认通信完成,在并发的内存实验中并非最佳实现。
torch的解决方案
P2P的内存拷贝尽量不用SM,改用CE(Copy Engines)。
方案的核心在于:不再下发send/recv kernels改用tensor.to(device)的D2D拷贝
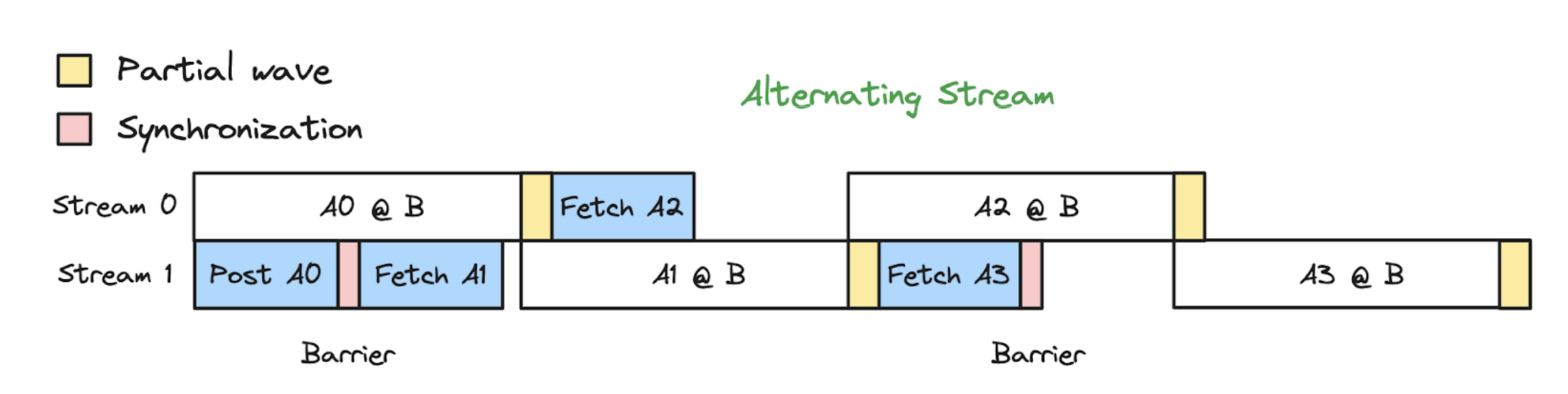
•copy_触发的to是在连续的tensor场景不使用SM的,使用CE(cuda接口)。
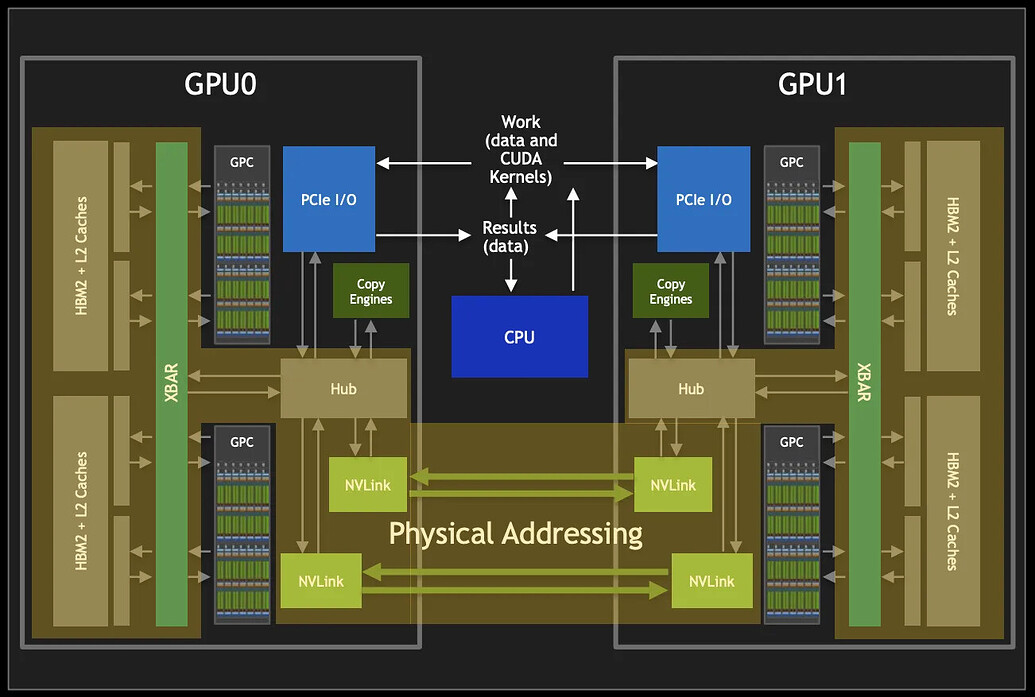
•cuda的接口是用了cuMemExportToShareableHandle ,因此此时的P2P拷贝是不过Host的栈,而是使用基于虚拟内存DMA的搬运(不用SM,占PCIE带宽)
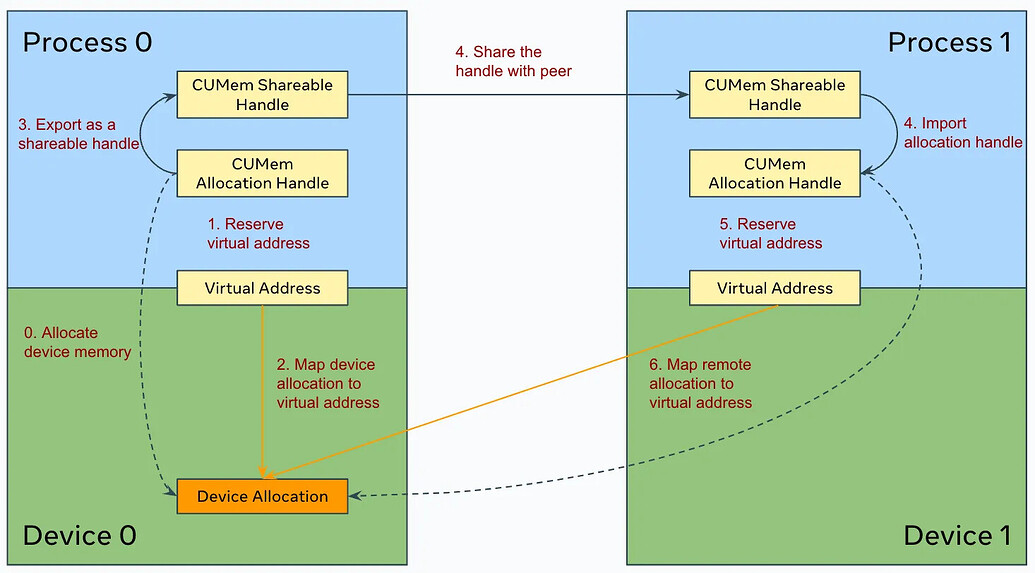
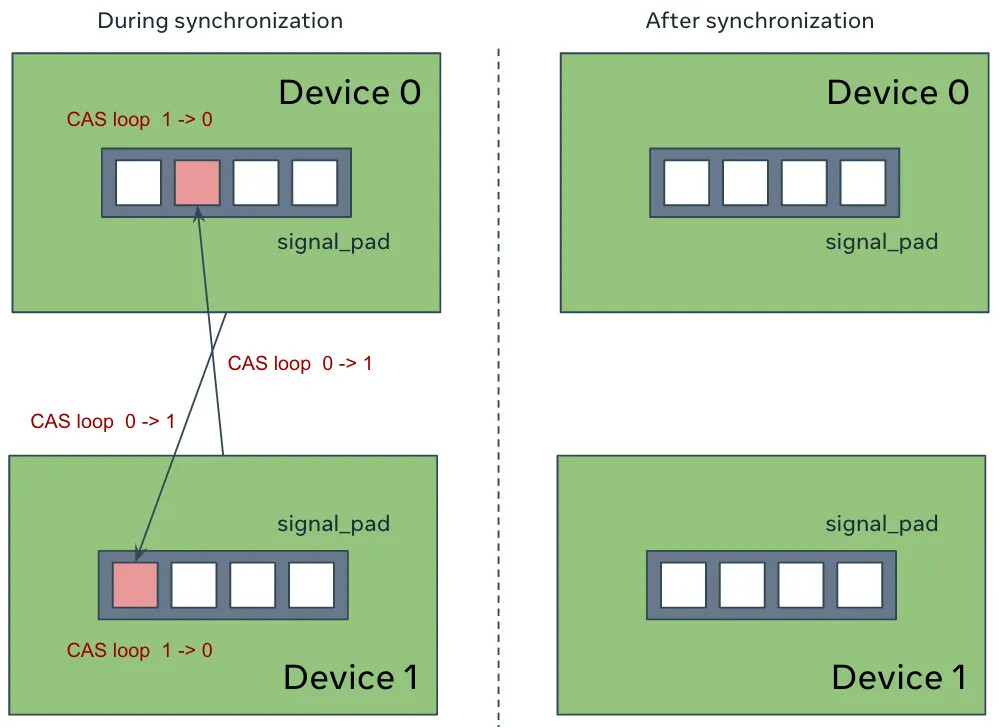
send/recv需要双向确认通信完成,拷贝也需要确认过拷贝是否完成,pytorch使用信号垫的方式完成确认。
参考文章
https://dev-discuss.pytorch.org/t/pytorch-symmetricmemory-harnessing-nvlink-programmability-with-ease/2798
https://discuss.pytorch.org/t/distributed-w-torchtitan-introducing-async-tensor-parallelism-in-pytorch/209487


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









