






 本文提供了详细的Linux系统资源监控方法,包括如何查看CPU、内存、硬盘等关键信息,并介绍了常用的命令如vmstat、iostat等,帮助读者有效监控Linux系统的整体性能。
本文提供了详细的Linux系统资源监控方法,包括如何查看CPU、内存、硬盘等关键信息,并介绍了常用的命令如vmstat、iostat等,帮助读者有效监控Linux系统的整体性能。
Linux 整理笔记
获取服务器信息
注意:总核数 = 物理CPU个数 * 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 * 每颗物理CPU的核数 * 超线程数
CPU相关操作
(1)查看物理cpu个数
cat /proc/cpuinfo| grep “physical id”| sort| uniq| wc -l

(2)查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep “cpu cores”| uniq

(3)查看逻辑CPU的个数
cat /proc/cpuinfo| grep “processor”| wc -l

(4)查看Linux版本信息
uname -a 查看内核信息
cat /etc/redhat-release 查看发行版本信息


(5)查看服务器内存
free -g
total: 内存总量
used: 已使用
free: 未使用
shared: 多进程共享的内存总量
-buffers/cache: 已使用内存
+buffers/cache: 可用内存
可用内存=free+buffers+cached(642=67+217+357)

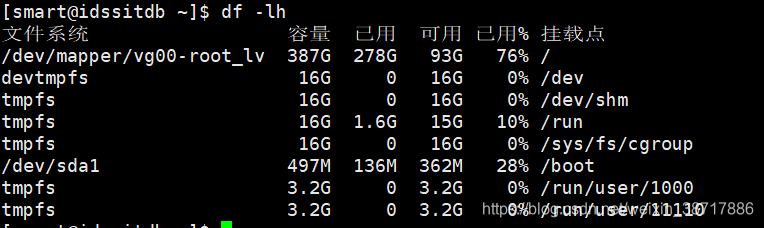
(6)查看服务器硬盘使用情况
查看文件系统的磁盘空间占用情况
df -lh
查看硬盘及分区信息
fdist -l
查看硬盘的I/O性能
注:-d显示磁盘状态,-x显示跟io相关的扩张数据,-k以KB为单位,10表示每隔10秒刷新一次,2表示刷新2次,默认一直刷新
iostat -d -x -k 10 2
参数说明:
rrqm/s: 每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge)
wrqm/s: 每秒进行merge的写操作数
r/s: 每秒完成的读I/O设备的次数
w/s: 每秒完成的写I/O设备的次数
rkB/s: 每秒读取多少KB
wkB/s: 每秒写多上KB
avgrq-sz: 平均每次设备I/O操作的数据大小(扇区)
avgqu-sz: 平均I/O队列长度
await: 平均每次设备I/O操作的等待时间ms
svctm: 平均每次设备I/O操作时间ms
%util: 一秒钟有百分之多上时间用于I/O操作
平时只要关注%util,await两个参数即可
%util越接近100%,说明产生的I/O请求越多,越容易满负荷
await 取决于svctm,最好低于5ms,如果大于5ms说明I/O压力大,可以考虑更换响应速度更快的硬盘.

(7)使用vmstat监控Linux系统的整体性能
vmstat 1 4 ##每秒1次,一共四次。
参数介绍:
procs:
r: 等待运行的进程数
b: 处于非中断睡眠状态的进程数
memory:
swpd: 虚拟内存使用情况(KB)
free: 空闲内存(KB)
swap:
si: 从磁盘交换到内存的交换页数量
so: 从内存交换到磁盘的交换页数量
io:
bi: 发送到设备的块数(块/s)
bo: 从块设备接收到的块数(块/s)
system:
in: 每秒中断数
cs: 每秒的环境上下文切换数
cpu:(cpu总使用的百分比)
us: cpu使用时间
sy: cpu系统使用时间
id: 闲置时间
标准情况下r和b的值应为:r<5,b约为0.
如果us+sy<70%,系统性能较好
如果us+sy>85,系统性能糟糕.

(8)查看系统位数
查看系统32、64位
getconf LONG_BIT

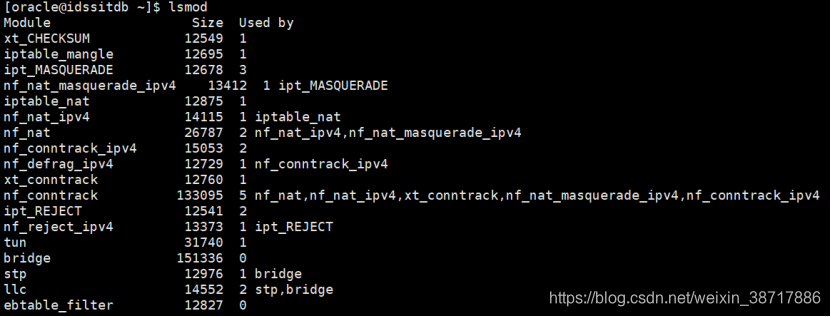
(9)查看系统已经载入的相关模块
lsmod


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









