






文本处理工具和正则表达式
内容描述
- 文本编辑工具 VIM
- 各种文本工具
- 基本正则表达式和扩展正则表达式
- 文本处理三剑客之 grep
- 文本处理三剑客之 sed
- 文本处理三剑客之 awk
1 文本编辑工具之神 VIM
1.1 使用 vim 初步
1.1.1 vim 命令格式
vim [OPTION]...FILE...
常用选项
+# 打开文件后,让光标处于第 # 行的行首,+默认行尾
+/PATTERN 让光标处于第一个被 PATTERN 匹配行的行首
-b file 二进制方式打开文件
-d file1 file2 比较多个文件,相当于 vimdiff
-m file 只读打开文件
-e file 直接进入 ex 模式,相当于执行 ex file
-y file Easy mode (like "evim",modeless),直接可以操作文件,ctrl+o:wq | q! 保存和不保存退出
说明:
- 如果该文件存在,文件被打开并显示内容
- 如果该文件不存在,当编辑后第一次存盘时创建它
1.1.2 三种主要模式和转换
vim 是一个模式编辑器,击键行为是依赖于 vim 的“模式”
三种常见模式
- 命令或普通(Normal)模式:默认模式,可以实现移动光标,剪切/粘贴文本
- 插入(Insert)或编辑模式:用于修改文本
- 扩展命令(extended command) 或命令行模式:保存,退出等
模式转换
- 命令模式 —> 插入模式
i insert,在光标所在处输入
I 在当前光标所在行的行首输入
a append,在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下放打开一个新行
O 在当前光标所在行的上访打开一个新行
- 插入模式 —ESC----->命令模式
- 命令模式 — : -----> 扩展命令模式
- 扩展命令模式 —ESC,enter----->命令模式
范例:插入颜色字符
1 切换至插入模式
2 按 "ctrl+v+[" 三个键盘,显示 ^[
3 后续输入颜色信息,如:^[[1;31mhello vim^[[0m
4 切换至扩展命令模式,保存退出
5 cat 文件可以看到下面显示


1.2 扩展命令模式
按“:”进入Ex模式,创建一个命令提示符:处于底部的屏幕左侧
1.2.1 扩展命令模式基本命令
w 保存文件
wq 保存退出
x 保存退出
X 加密
q 退出
q! 不存盘退出,所有修改全部丢失
r [file_name] 读取文件内容到当前光标处
w [file_name] 将当前文件内容写入另一个文件
! [command] 执行命令
r! [command] 读入命令的输出
1.2.2 地址定界
格式:
:start_pos,end_pos CMD
# #具体第#行,例如2表示第二行
#,# #从左侧#表示起始行,到右侧#表示结尾行
#,+# #从左侧#表示其实行,加上右侧#表示的行数,范例:2,+3 表示2到5行
. #当前行
$ #最后一行
.,$-1 #当前行到倒数第二行
% #全文,相当于1,$
/pattern/ #从当前行向下查找,知道匹配pattern的第一行,即:正则表达式
/pat1/,/pat2/ #从第一次被pat1模式匹配到的行数开始,一直到第一次被pat2匹配到的行结束
#,/pat/ #从指定行开始,一直到第一个匹配pattern的行结束
/pat/,$ #向下找到第一个匹配pattern的行到整个文件的结尾的所有行
地址定界后跟一个编辑命令
d #删除
y #复制
p #粘贴
w [file] #将范围内的行另存至指定文件中
r [file] #在指定位置插入指定文件中的所有内容
t#行号 #将前面指定的行复制到#行后
m#行号 #将前面指定的行移动到#行后
1.2.3 查找并替换
- 格式:
s/要查找的内容/替换为的内容/修饰符
- 说明:
要查找的内容:可使用基本正则表达式模式
替换为的内容:不能使用模式,但可以使用\1,\2,...等后向引用符号;还可以使用"&"引用前面查找时,找到的整个内容
- 修饰符:
i #忽略大小写
g #全局替换,默认情况下,每一行只替换第一次出现
gc #全局替换,每次替换前询问
- 查找替换中的分隔符 / 可以替换为其他字符,如:#,@
- 范例:
%s@/etc@/var@g
%s#/boot#/#i
1.2.4 定制vim的工作特性
扩展命令模式的配置只是对当前vim进程有效,可将配置存放在文件中持久保存
配置文件:
/etc/vimrc #全局
~/.vimrc #个人
1.2.4.1 行号
显示:
set number,简写: set nu
取消显示:
set nonumber,简写:set nonu
1.2.4.2 忽略字符的大小写
启用:
set ignorecase, 简写 set ic
不忽略:
set noic
1.2.4.3 自动缩进
启用:set auotindent,简写:set ai
禁用:set noai
1.2.4.4 复制保留格式
启用:set paste
禁用:set nopaste
1.2.4.5 显示Tab^I 和换行符 和 $显示
启用:set list
禁用:set nolist
1.2.4.6 高亮搜索
启用:set hlsearch
禁用:set nohlsearch,简写:nohl
1.2.4.7 语法高亮
启用:syntax on
禁用:syntax off
1.2.4.8 文件格式
启用windows格式:set fileformat=dos
启用unix格式:set fileformat=unix
简写:set ff=[dos|unix]
1.2.4.9 Tab 用空格代替
启用:set expandtab 默认为8个空格代替Tab
禁用:set noexpandtab
简写:set et
1.2.4.10 Tab用指定空格个数代替
启用:set tabstop=# 指定#个空格代替Tab
简写:set ts=4
1.2.4.11 设置缩进宽度
#向右缩进 命令模式>>
#向左缩进 命令模式<<
#设置缩进为4个字符
set shiftwidth=4
1.2.4.12 设置文本宽度
set textwidth=65 (vim only) #从左向右计数
set wrapamrgin=15 #从右向左计数
1.2.4.13 设置光标所在行的标识线
启用:set cursorline,简写:set cul
禁用:set nocursorline
1.2.4.14 加密
启用:set key=password
禁用:set key=
1.3 命令模式
命令模式,又称为 Normal 模式,功能强大,只是此模式输入指令并在屏幕上显示,所以需要记忆大量的快捷按键才能更好的使用。
1.4.1 退出VIM
zz 保存退出
zq 不保存退出
1.4.2 光标跳转
单词间跳转:
w: 下一个单词的词首
e: 当前或下一个单词的词尾
b: 当前或前一个单词的词首
#COMMAND: 由#指定一次跳转的单词数
当前页跳转:
H: 页首
M: 页中间行
L: 页底
zt:将光标所在行移到屏幕顶端
zz:将光标所在行移到屏幕中间
zb:将光标所在行移动屏幕底端
行首行尾跳转:
^ 跳转至行首的第一个非空白字符
0 跳转至行首
$ 跳转至行尾
行间移动:
#G 跳转至第 # 行
G 跳转至最后一行
1G,gg 跳转至第一行
句间移动:
) 下一句
( 上一句
段落间移动:
} 下一段
{ 上一段
1.4.3 字符编辑
x 剪切光标处的字符
#x 剪切光标处
xp 交换光标所在处的字符和后边字符互换位置
~ 转换大小写
J 删除当前行后的换行符(作用是吧下一行直接移动到当前行的结尾。)
1.4.4 替换命令(replace)
r 只替换光标所在处的一个字符
R 切换成 REPLACE 模式(在屏幕下方出现 -- REPLACE -- 提示),按ESC回到命令模式
1.4.5 删除命令(delete)
d 删除命令,可结合光标跳转字符,实现范围内删除
d$ 删除到行尾
d^ 删除到非空行首
d0 删除到行首
dw
de
db
#COMMAND
dd 剪切光标所在的行
#dd 多行剪切
D 从当前光标位置一直删除到行尾,等同于 d$
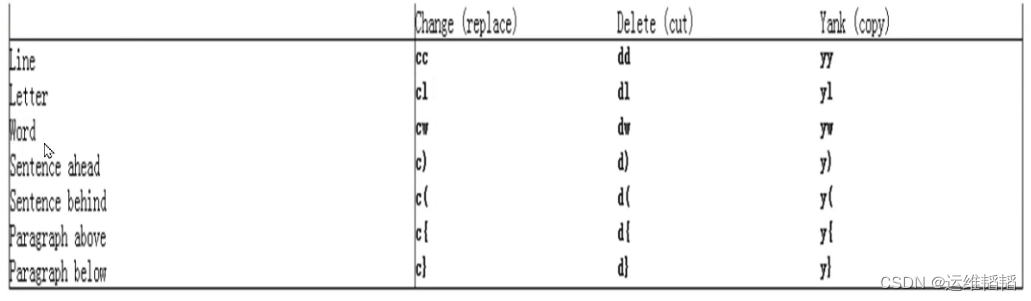
1.4.6 复制命令(yank)
y 复制,行为相似 d 命令
y$
y0
y^
ye
yw
yb
#COMMAND
yy 复制行
#yy 复制多行
Y 复制整行
1.4.7 黏贴命令(paste)
P 缓冲区存的如果为整行,则黏贴当前光标所在行的下方:否则,则年底按至当前光标所在处的后面
p 缓冲区存的如果为整行,则黏贴当前光标所在行的上方:否则,则年底按至当前光标所在处的前面
1.4.8改变命令(change)
命令 c 删除后切换成插入模式
c$
c^
c0
cb
ce
cw
#COMMAND
cc #删除当前并输入新内容S
#cc
C #删除当前光标到行尾,并且换成插入模式,相当于c$
命令操作模式文本总结
1.4.9 查找
/PATTERN:从当前光标所在处向文本尾部查找
?PATTERN:从当前光标所在处向文件首部查找
n:与命令同方向
N:与命令反方向
1.4.10 撤销修改
u 撤销最近的更改,相当于 windows 的 ctrl+z
#u 撤销之前多次更改
U 撤销光标落在这行后所有该行的更改
ctrl - r 恢复“撤销”(撤销撤销)
. 重复前一个操作
#. 重复前一个操作#次
1.4.11 高级用法
< start position >< command >< end position >
常见 command:y复制、d删除、gU变大写、gu变小写
范例1:
0y$ 命令
0: 先到行头
y: 从这里开始拷贝
$: 拷贝到本行最后一个字符
范例2:黏贴"wang"100次
100iwang [ESC]
di" 删除双引号之间的内容,光标必须在" "之间
yi( 复制小括号之间的内容,光标必须在( )之间
vi[ 选中中括号之间的内容,光标唏嘘在[ ]之间
dtx 删除从光标位置到 x 前的所有字符
ytx 复制从光标位置到 x 前的所有字符
1.5 可视化模式
在末行有 “-- VISUAL --” 标识,表示在可视化模式
允许选择的文本块
- v 面向字符,-- VISUAL –
- V 面向整行, – VISUAL LINE –
- ctrl-v 面向块, – VISUAL BLOCK –
可视化键可用于与移动键结合使用
w ) } 等
突出显示的蚊子可被删除,复制,变更,过滤,搜索,替换等
范例:在文件制定行的行首插入
1、先将光标移动到制定的第一行的行首;
2、输入 ctrl+v 进入可视化模式;
3、乡下移动光标,选中希望操作的每一行的第一个字符;
4、输入大写字符 I (大i)切换至插入模式;
5、输入 #
6、按 ESC 键。
1.6 多文件模式
vim FILE1 FILE2 FILE3 ....
:next 下一个
:prev 上一个
:first 第一个
:last 最后一个
:wall 保存所有
:qall 不保存退出所有
:wqall 保存退出所有
1.7 多窗口模式
1.7.1 多文件分割
vim -o|-O FILE1 FILE2 ...
-o: 水平或者上下分割
-O: 垂直或者左右分割
在窗口间切换:ctrl+w,arrow
1.7.2 单文件窗口分割
ctrl+w,s 水平分割,上下分屏
ctrl+w,v 垂直分割,左右分屏
ctrl+w,q 取消相邻窗口
ctrl+w,o 取消全部窗口
:wqall 保存退出
1.8 帮助
:help
:help topic
use :q to exit help
#vimtutor
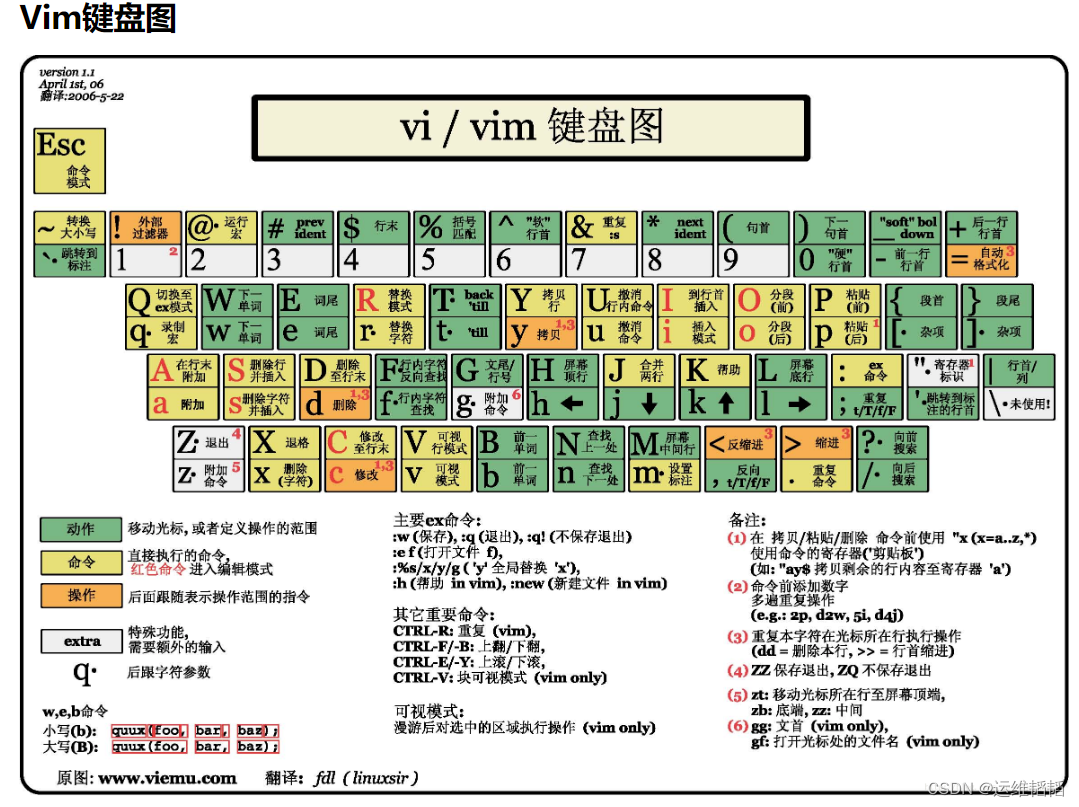
1.9 vim 总结图
2、文本常见处理工具
2.1 文件内容查看命令
2.1.1 查看文本文件内容
2.1.1.1 cat
cat 可以查看文本内容
- 格式:
cat [ OPTION ]...[FILE]...
- 常见选项
-E: 显示行结束符$
-A: 显示所有控制符
-n: 对显示出的每一行进行编号
-b: 非空行编号
-s: 压缩连续的空行成一行
- 范例:


- 当在windows里复制文件但总是执行失败或者错误的情况,可能就是格式不符合。
- 还有的时候执行脚本总是失败,也可以用 cat -A 进行查看,例如说:

2.2 分页查看文件内容
2.2.1 more
可实现分页查看文件,可以配合管道实现输出信息的分页
格式:
more [OPTIONS] FILE
选项
-d:显示翻页及退出提示
向下翻页: 空格键 向下翻页
向上翻页: ctrl + b 向上翻页
2.2.2 less
less 也是分页查看或者 STDIN 输出,less命令是 man 命令使用的分页器
查看时有用的命令包括:
/文本:搜索文本
n/N:跳到下一个 或 上一个匹配
向下翻页: 空格键 向下翻页
向上翻页: ctrl + b 向上翻页
2.3 显示文本前面活后面的行内容
2.3.1 head
格式
head [OPTION]… [FILE]…
选项
-c # 指定获取前#字节
-n # 指定获取前#行,#如果为负数,表示从文件头取倒数第#前
-# 同上
范例:
例1:读取 /etc/passwd 前三行
# head -n 3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
例2:读取 /etc/passwd 前三行
# head -3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
例3:读取 abcdefg 前4个字节
#echo abcdefg | head -c4
abcd
例4:读取前三行和从文件开头至倒数第三行
# cat test.log
01
02
03
04
05
06
07
08
09
10
# head -3 test.log
01
02
03
# head -n -3 test.log
01
02
03
04
05
06
07
2.3.2 tail
tail 和 head 相反,查看文件或标准输入的倒数行
格式:
tail [OPTION]… [FILE]…
常用选项
-c #: 指定获取后#字节
-n #: 指定获取后#行,如果#是正数,表示从第#行开始到文件结束
-#: 同上
-f: 跟踪显示文件新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除在新建同名文件,将无法继续跟踪。
-F: 跟踪文件名,相当于–follow-name --retry,当文件删除在新建同名文件,将可以继续跟踪文件
范例
例1:查看文件后3行
#tail -n 3 test.log
08
09
10
#tail -3 test.log
08
09
10
例2:从正数第三行到结尾
# tail -n +3 test.log
03
04
05
06
07
08
09
10
例3:tail -f 跟踪日志
# tail -f test.log
1
2
3
4
5
# for((i=6;i<=10;i++));do echo $i >> test.log ;done #(新开窗口对test.log添加内容)
# tail -f test.log
1
2
3
4
5
6
7
8
9
10
例4:只查看最新发生的日志
# tail -fn0 test.log
# tail -0f test.log
2.4 按列抽取文本 cut
cut 命令可以提取文本文件或 STDIN 数据的指定列
格式
cut [OPTION]… [FILE]…
常规选项
-d DELIMITER:指明分隔符,默认tab
-f FILDES:#:第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段,例如:1-6
混合使用:1-3,7-c:按字符切割
- -output-delimiter=STRING:指定输出分隔符
范例:
# cut -d: -f1,3-4,7 /etc/passwd
# ifconfig|head -n2|tail -n1|cut -d" " -f10
192.168.100.1
# ifconfig|head -n2|tail -n1|tr -s " "|cut -d" " -f3
192.168.100.1
# (tr -s " " 的意思是把多个空格合并成1个字符)
# echo {1..10}|cut -d ' ' -f1-10 --output-delimiter="+"
1+2+3+4+5+6+7+8+9+10
# echo {1..10}|cut -d ' ' -f1-10 --output-delimiter="+"|bc
55
范例2:取分区利用率
# df | tr -s ' ' | cut -d' ' -f1,5 | column -t
Filesystem Use%
devtmpfs 0%
tmpfs 0%
tmpfs 1%
tmpfs 0%
/dev/mapper/rl-root 6%
/dev/sda1 36%
nfs-server:/mnt1 6%
tmpfs 0%
#tr -s:替换
#tr -d:删除
#column -t:对齐
2.4.1 特殊符号代表意义

2.5 合并多个文件 paste
格式:
paste [OPTION]… [FILE]…
常用选项:
-d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
范例:
# cat test.log
a
b
c
d
e
f
g
h
# cat seq.log
1
2
3
4
5
# paste alpha.log seq.log
a 1
b 2
c 3
d 4
e 5
f
g
h
# paste -d":" alpha.log seq.log
a:1
b:2
c:3
d:4
e:5
f:
g:
h:
# paste -s seq.log
1 2 3 4 5
# paste -s alpha.log
a b c d e f g h
# paste -s alpha.log seq.log
a b c d e f g h
1 2 3 4 5
# seq 10|paste -s -d+|bc
55
范例2:批量修改密码
# cat >>user.txt<<EOF
> Jimmy
> Wentao
> EOF
# cat >>pass.txt<<EOF
> 123456
> wentao
> EOF
# paste -d: user.txt pass.txt
Jimmy:jimmy123456
Wentao:wentao
# paste -d: user.txt pass.txt | chpasswd
2.6 分析文本工具
文本数据统计:wc
整理文本:sort
比较稳健:diff 和 path
2.6.1 手机文本统计数据 wc
wc 命令可用于统计稳健的行总数、单词总数和字符总数,可以对文件或STDIN中的数据统计
常用选项:
-l 只计算行数
-w 只计算单词总数
-c 只计算字节总数
-m 只计算字符总数
-L 显示文件中最长行的长度
范例
# wc test.sh
32 126 849 test.sh
#行数 单词数 字节数
# cat title.txt
ceo cui
coo hehan
cto zzz
# wc title.txt
3 6 26 title.txt
# wc -l title.txt
3 title.txt
2.6.2 文本排序 sort
格式:
sort [options] file(s)
常用选项
-r 以相反的顺序来排序
-R 随机排序
-n 依照数值的大小排序
-h 人类可读排序,如:2k 1G
-f 忽略字符串中的字符大小写
-u 合并重复项,即 去重
-t 设置排序时所用的分割符
-k 指定需要排序的列
-o 将排序结果存入指定文件中
实例1:按照“:”分割后的第三例倒叙排序
# cat sort.txt
bxmb:20:4.2
xfet:50:2.3
clsuh:10:3.5
sewp:30:1.6
xfam:50:2.3
xfet:50:2.3
# sort -t: -nrk 3 sort.txt
bxmb:20:4.2
clsuh:10:3.5
xfet:50:2.3
xfet:50:2.3
xfam:50:2.3
sewp:30:1.6
-t 指定分隔符。
-n 依照数值的大小排序。
-r 以相反的顺序来排序(默认是升序)。
-k 指定需要排序的列。
实例2:按照数据自然顺序
# cat sort-1.txt
20
19
5
49
200
# sort -n sort-1.txt
5
19
20
49
200
实例3:按数字顺序倒序排列
# sort -nr sort-1.txt
200
49
20
19
5
-n 依照数值的大小排序。
-r 以相反的顺序来排序(默认是升序)。
实例4:对file1,file2 两个文件,按数字倒序排序,并移除其重复项,输出到 file3
# cat file1 file2
20
19
5
49
200
25
25
18
5
48
200
# sort -nr -u file1 file2 -o file3
# cat file3
200
49
48
25
20
19
18
5
-n 依照数值的大小排序。
-r 以相反的顺序来排序(默认是升序)。
-u 去重
-o 将排序结果存入指定文件中
实例5:对file文件,按月份来排序
# cat file
Aug 8 30
Jan 1 31
Mar 3 31
Feb 2 28
May 5 30
Jul 7 31
Jun 6 30
# sort -M file
Jan 1 31
Feb 2 28
Mar 3 31
May 5 30
Jun 6 30
Jul 7 31
Aug 8 30
-M 将前面3个字母依照月份的缩写进行排序
实例6 对 file4 文件按照第一列来排序
# sort -t"," -k1,1 file4
AIX,25
HPUX,100
Linux,20
Linux,25
Solaris,10
Unix,30
-k[n[,m]: 指定一个或几个字段作为排序关键字,字段位置从n开始,到m为止(包括n,不包括m)。如不指定m,则关键字为从n到行尾。字段和字符的位置从0开始,第一列为1
实例7 对多阈值文件 file4,按第二列自然数字排序并移除重复行
# sort -t"," -k2n,2 -u file4
Solaris,10
Linux,20
AIX,25
Unix,30
HPUX,100
实例8,对多阈值文件file5,先按第一列排序,在按第三列自然数字倒序排列
# cat file5
google 110 5000
baidu 100 5000
guge 50 3000
sohu 100 4500
#-t' ',默认是按空格,Tab键来排序,所以此处可以不要,只是为了好理解些
#-k 1.2,1.2 from 1 to 1,也就是按第一列来排序
#1.2表示第一列,第二个字符.
#-k 3,3nr 第三列按自然数字倒序.注意其表现形式
#sort -t' ' -k 1.2,1.2 -k 3,3nr file5
baidu 100 5000
google 110 5000
sohu 100 4500
guge 50 3000
实例9,总和管道命令,统计每个用户的登录总次数
# last 取出所有用户访问列表,第一列为用户名
# last
root pts/0 192.168.100.254 Thu Jul 20 10:27 still logged in
root pts/0 192.168.100.254 Tue Jul 18 15:59 - 17:51 (1+01:51)
root pts/0 192.168.100.254 Mon Jul 10 10:56 - 19:14 (08:18)
...
# uniq -c 进行计数
# cut -d' ' -f1 按空格分割,取第一列,即取出用户
# awk '{print $1}' 同上
# last | awk '{print $1}'|sort |uniq -c
1
17 reboot
84 root
1 wtmp
实例10,总和管道命令,将两个文件合并,按数值大小倒序放入新文件
# cat file1 file2
20
19
5
49
200
25
25
18
5
48
200
# cat file1 file2 | sort -nr | uniq
200
49
48
25
20
19
18
5
6.2.3 去重 uniq
uniq是对文本进行 行去重 的工具
- 以行尾单位,进行 行与行 之间的字符串比较 并进行去重
- 只能对有序的文本进行有效去重,所以常与 sort 命令结合使用
-c 统计 每行 重复出现的次数
-d 只显示重复过的行
-u 只显示不曾重复过的行
-i 忽略字母大小写
-f 忽略前N个字段(字段剪用空白字符分隔)
与sort结合使用
# cat file1
hello this is linux
be better
be better
i am john
hello this is linux
i am john
i am john
be better
i am john
have a nice day
have a nice day
hello this is linux
hello this is linux
have a nice day
zzzzzzzzzzzzzzz
dddddddddd
gggggggggggggggggggggg
#【1】单独使用 uniq 命令
#uniq file1
hello this is linux
be better
i am john
hello this is linux
i am john
be better
i am john
have a nice day
hello this is linux
have a nice day
zzzzzzzzzzzzzzz
dddddddddd
gggggggggggggggggggggg
# 可以看出单独使用uniq命令时,只对相邻重复行进行去重,无法进行有效去重
#【2】与 sort 结合使用
#sort file1 | uniq
be better
dddddddddd
gggggggggggggggggggggg
have a nice day
hello this is linux
i am john
zzzzzzzzzzzzzzz
#先排序使重复的行相邻,然后使用uniq可是有效去重
统计出现的次数,使用 -c 参数
# sort file1 | uniq -c
3 be better
1 dddddddddd
1 gggggggggggggggggggggg
3 have a nice day
4 hello this is linux
4 i am john
1 zzzzzzzzzzzzzzz
只显示重复的行,并且去重,使用-d参数
# sort file1 | uniq -dc
3 be better
3 have a nice day
4 hello this is linux
4 i am john
只显示不曾重复的行,使用-d参数
# sort file1 | uniq -u
dddddddddd
gggggggggggggggggggggg
zzzzzzzzzzzzzzz
6.2.4 文本比较
6.2.4.1 diff
# cat file1.txt
I need to buy apples.
I need to run the laundry.
I need to wash the dog.
I need to get the car detailed.
# cat file2.txt
I need to buy apples.
I need to do the laundry.
I need to wash the car.
I need to get the dog detailed.
查看两个文件的不同
# diff file1.txt file2.txt
2,4c2,4
< I need to run the laundry.
< I need to wash the dog.
< I need to get the car detailed.
---
> I need to do the laundry.
> I need to wash the car.
> I need to get the dog detailed.
输出结果说明
diff 描述两个文件不同的方式,是告诉我们怎么 改变第一个文件之后与第二个文件匹配。
比较结果中的第一行:2,4c2,4
前面的数字 2,4 表示第一个文件中的行,字母 c 表示需要在第一个文件上做的操作(a=add,c=change,d=delete),后面的数字 2,4 表示第二个文件中的行。那么
2,4c2,4
含义是:第一个文件中 第2行 和 第4行 需要作出修改才能与第二个文件的 第2行 和 第4行 相匹配。
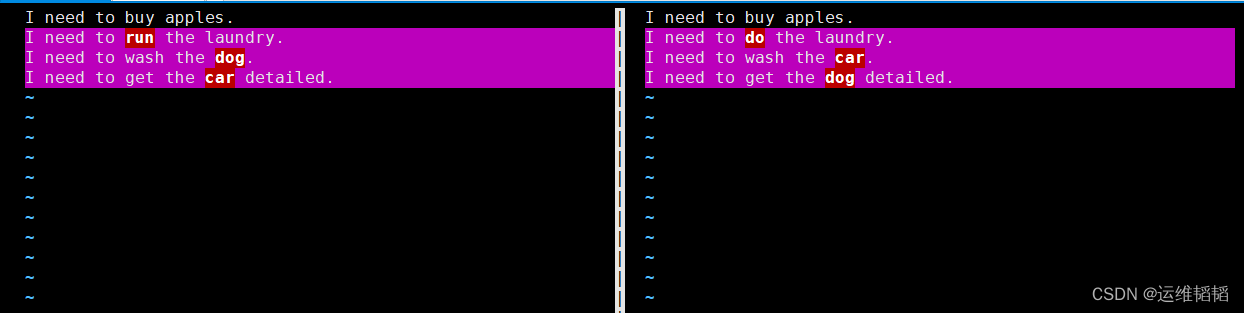
6.2.4.2 vimdiff
# cat file1.txt
I need to buy apples.
I need to run the laundry.
I need to wash the dog.
I need to get the car detailed.
# cat file2.txt
I need to buy apples.
I need to do the laundry.
I need to wash the car.
I need to get the dog detailed.
使用 vimdiff 查看两个文件的不同


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









