







 本文详细介绍了如何通过配置两级Flume集群实现负载均衡,包括一级配置(exec-avro.conf)与二级配置(avro-logger.conf)的具体设置,以及启动Flume代理的步骤。通过使用Avro源和Sink,确保了数据在多节点间的高效传输。
本文详细介绍了如何通过配置两级Flume集群实现负载均衡,包括一级配置(exec-avro.conf)与二级配置(avro-logger.conf)的具体设置,以及启动Flume代理的步骤。通过使用Avro源和Sink,确保了数据在多节点间的高效传输。
准备条件:提前安装好HDFS集群和flume集群
负载均衡(load-balance)的目的
负载均衡解决是解决一台机器(一个进程)无法解决所有请求而产生的一种算法(即使用多个fluem同时来接受一个较大的flume)
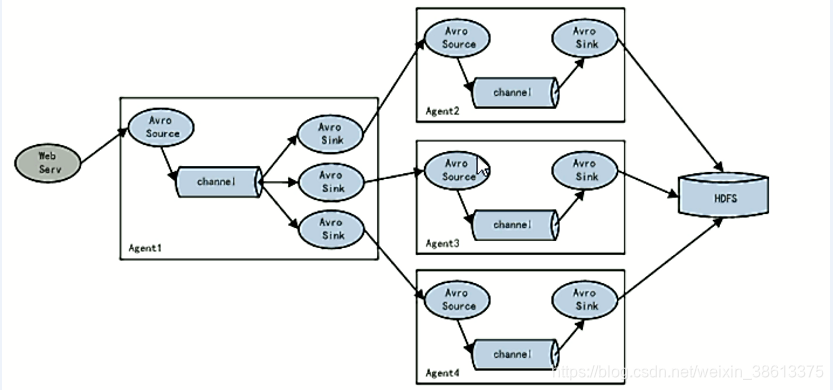
配置文件(两级flume)
.创建"exec-avro.conf"(第一级配置)
[root@hadoop1 conf]# vi exec-avro.conf
#指定Agent的组件名称
a1.sources = r1
a1.channels = c1
#指定两个下沉地址
a1.sinks = k1 k2
#设置资源,此处也可以是文件夹或者端口
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /a.log
#设置通道channels
a1.channels.c1.type = memory
a1.channels.c1.capatity = 1000
a1.channels.c1.transactionCapacity = 100
#设置sink1
#设置下沉目的地sink1,avro可以跨网络传输
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.215.165
a1.sinks.k1.port=52020
#设置sink2
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=192.168.215.166
a1.sinks.k2.port=52020
#关系
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c1
#设置proceecing
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=k1 k2
#指明负载均衡
a1.sinkgroups.g1.processor.type=load_balance
a1.sinkgroups.g1.processor.backoff=true
#轮询策略(round_robin),随机策略(random)
a1.sinkgroups.g1.processor.selector=round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=1000
创建"avro-logger.conf"(第二级配置,在每个二级机器上都创建)
[root@hadoop2 conf]# vi avro-logger.conf
[root@hadoop3 conf]# vi avro-logger.conf
#命名
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#资源
a1.sources.r1.type = avro
#各个二级虚拟机只需要修改这一行代码
a1.sources.r1.bind = 192.168.215.165
a1.sources.r1.port = 52020
#sink,这个下沉地址可以改变,如果是HDFS的可以参考"6.2"中的下沉
a1.sinks.k1.type = logger
#通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 连接
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注:"avro"是一种通用的(跨平台语言)的序列化协议(将对象序列化为二进制)。
启动(先启动第二级,防止数据丢失)
[root@hadoop2 apache-flume-1.8.0-bin]# flume-ng agent --conf conf --conf-file conf/avro-logger.conf --name a1 -Dflume.root.logger=INFO,console
[root@hadoop3 apache-flume-1.8.0-bin]# flume-ng agent --conf conf --conf-file conf/avro-logger.conf --name a1 -Dflume.root.logger=INFO,console
[root@hadoop1 apache-flume-1.8.0-bin]# flume-ng agent --conf conf --conf-file conf/exec-avro.conf --name a1 -Dflume.root.logger=INFO,console

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









