






hive安装部署及使用
hive安装部署
前提:hive是java写的,因此需要配置java环境变量;另外保证你的hadoop集群正常起来
[atguigu@hadoop1 root]$ echo $HADOOP_HOME
/opt/module/hadoop-2.7.2
[atguigu@hadoop1 root]$ echo $JAVA_HOME
/usr/java/jdk1.8.0_131
1.把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下
2.解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
[atguigu@hadoop1 software]$ tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
3.修改apache-hive-1.2.1-bin.tar.gz的名称为hive-1.2.1
[atguigu@hadoop1 module]$ mv apache-hive-1.2.1-bin/ hive-1.2.1
4.配置HIVE_HOME
修改 /etc/profile文件
export JAVA_HOME=/usr/java/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export HIVE_HOME=/opt/module/hive-1.2.1
export HADOOP_PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export PATH=$PATH:${JAVA_PATH}:${HADOOP_PATH}:${HIVE_HOME}/bin
重写加载文件
source /etc/profile
hive简单使用
直接用hive命令进入
(1)启动hive
[atguigu@hadoop1 hive-1.2.1]$ bin/hive
常用命令:
show databases; # 查看某个数据库
use 数据库; # 进入某个数据库
show tables; # 展示所有表
desc 表名; # 显示表结构
show partitions 表名; # 显示表名的分区
show create table_name; # 显示创建表的结构
建表语句
内部表
use xxdb;
create table xxx;
ex: create table student(id int, name string);
创建一个表,结构与其他一样
create table xxx like xxx;
创建student表, 并声明文件分隔符’\t’
create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
外部表
use xxdb;
create external table xxx;
分区表
use xxdb; create external table xxx (l int) partitoned by (d string)
内外部表转化
alter table table_name set TBLPROPROTIES ('EXTERNAL'='TRUE'); # 内部表转外部表
alter table table_name set TBLPROPROTIES ('EXTERNAL'='FALSE');# 外部表转内部表
表结构修改
重命名表
use xxxdb; alter table table_name rename to new_table_name;
增加字段
alter table table_name add columns (newcol1 int comment ‘新增’);
修改字段
alter table table_name change col_name new_col_name new_type;
删除字段(COLUMNS中只放保留的字段)
alter table table_name replace columns (col1 int,col2 string,col3 string);
删除表
use xxxdb;
drop table table_name;
删除分区
注意:若是外部表,则还需要删除文件(hadoop fs -rm -r -f hdfspath)
alter table table_name drop if exists partitions (d=‘2016-07-01');
字段类型
tinyint, smallint, int, bigint, float, decimal, boolean, string
复合数据类型
struct, array, map
查询
select * from test;
ex:insert into student values(1000,"ss");
hive数据的存储
1.Hive要分析的数据是存储在HDFS上
hive中的库的位置,在hdfs上就是一个目录!
hive中的表的位置,在hdfs上也是一个目录,在所在的库目录下创建了一个子目录!
hive中的数据,是存在在表目录中的文件!
-
在hive中,存储的数据必须是结构化的数据,而且
这个数据的格式要和表的属性紧密相关!
表在创建时,有分隔符属性,这个分隔符属性,代表在执行MR程序时,使用哪个分隔符去分割每行中的字段!hive中默认字段的分隔符编辑: ctrl+A, 进入编辑模式,ctrl+V 再ctrl+A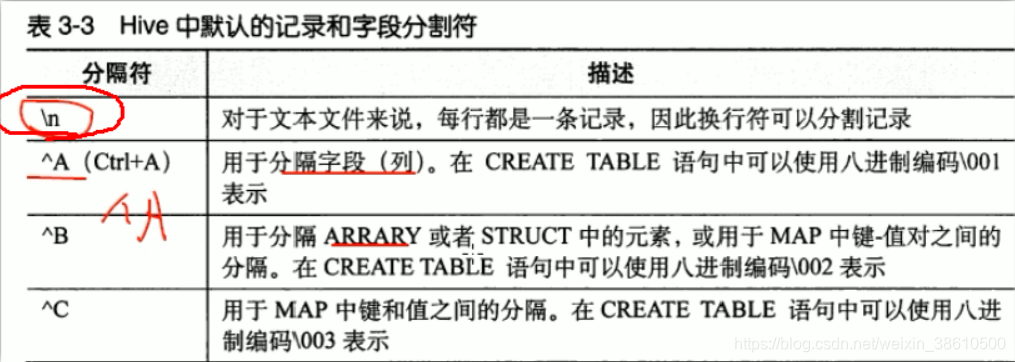
查看分割符:cat -T test1
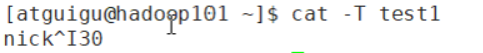
-
hive中的元数据(schema)存储在关系型数据库
默认存储在derby中!derby是使用Java语言编写的一个微型,常用于内嵌在Java中的数据库! derby同一个数据库的实例文件不支持多个客户端同时访问! -
将hive的元数据的存储设置存储在Mysql中!
Mysql支持多用户同时访问一个库的信息!
配置hive的元数据存储到MySQL中
-
编辑/opt/module/hive-1.2.1/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop1:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
注意:metastore数据库最好受到创建,字符集选择latin1,否则报错
2.将mysql连接的驱动放入/opt/module/hive-1.2.1/lib下
mysql-connector-java-5.1.27-bin.jar

[atguigu@hadoop1 lib]$ hive
Logging initialized using configuration in jar:file:/opt/module/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive- log4j.properties
hive> create table person(name varchar(20),age int);
OK
Time taken: 1.246 seconds
hive>


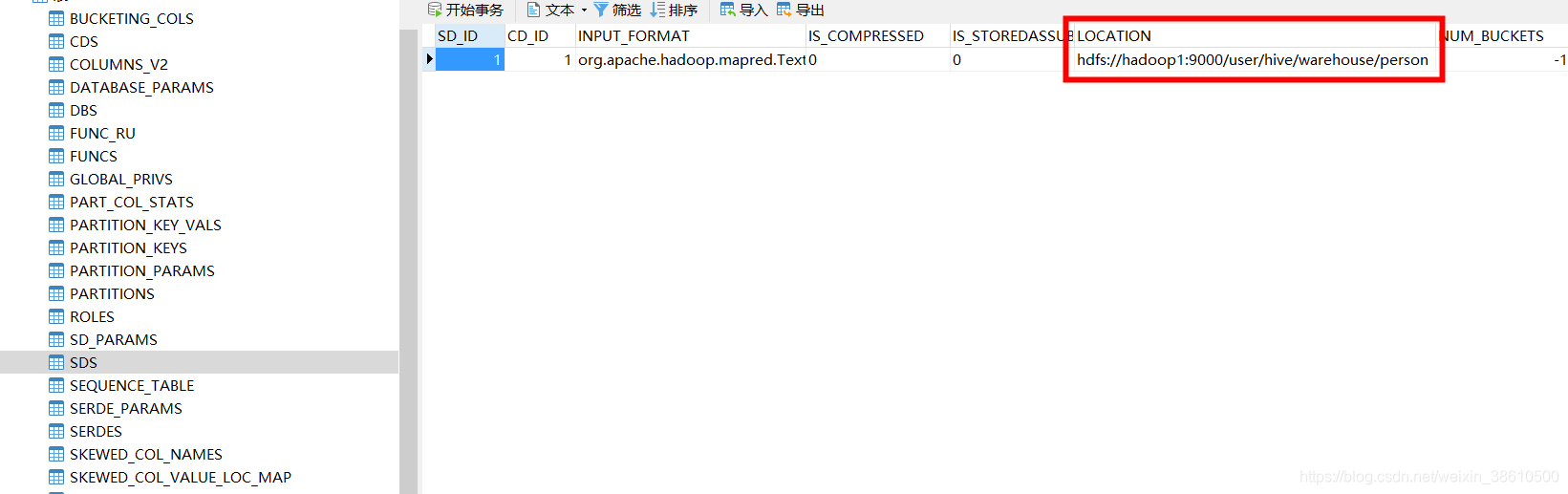
表的信息都存储在tbls表中,通过db_id和dbs表中的库进行外键约束!
库的信息都存储在dbs表中!
字段信息存在在column_v2表中,通过CD_ID和表的主键进行外键约束!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









