






 本文介绍了如何安装和使用Selenium操控浏览器,包括下载Chrome和相应版本的ChromeDriver,以及利用Docker安装和运行Splash服务。此外,还提到了Puppeteer的Python库Pyppeteer,强调了在Python3.6+环境中安装和使用这些工具进行网页自动化测试的方法。
本文介绍了如何安装和使用Selenium操控浏览器,包括下载Chrome和相应版本的ChromeDriver,以及利用Docker安装和运行Splash服务。此外,还提到了Puppeteer的Python库Pyppeteer,强调了在Python3.6+环境中安装和使用这些工具进行网页自动化测试的方法。
安装selenium
Seleinum 是一款使用代码操纵浏览器的框架,我们可以通过它驱动浏览器执行一些点击、滑动、输入指定字符等操作。
第一步下载chrome
下载安装chrome 忽略
在chrome设置查看chrome版本
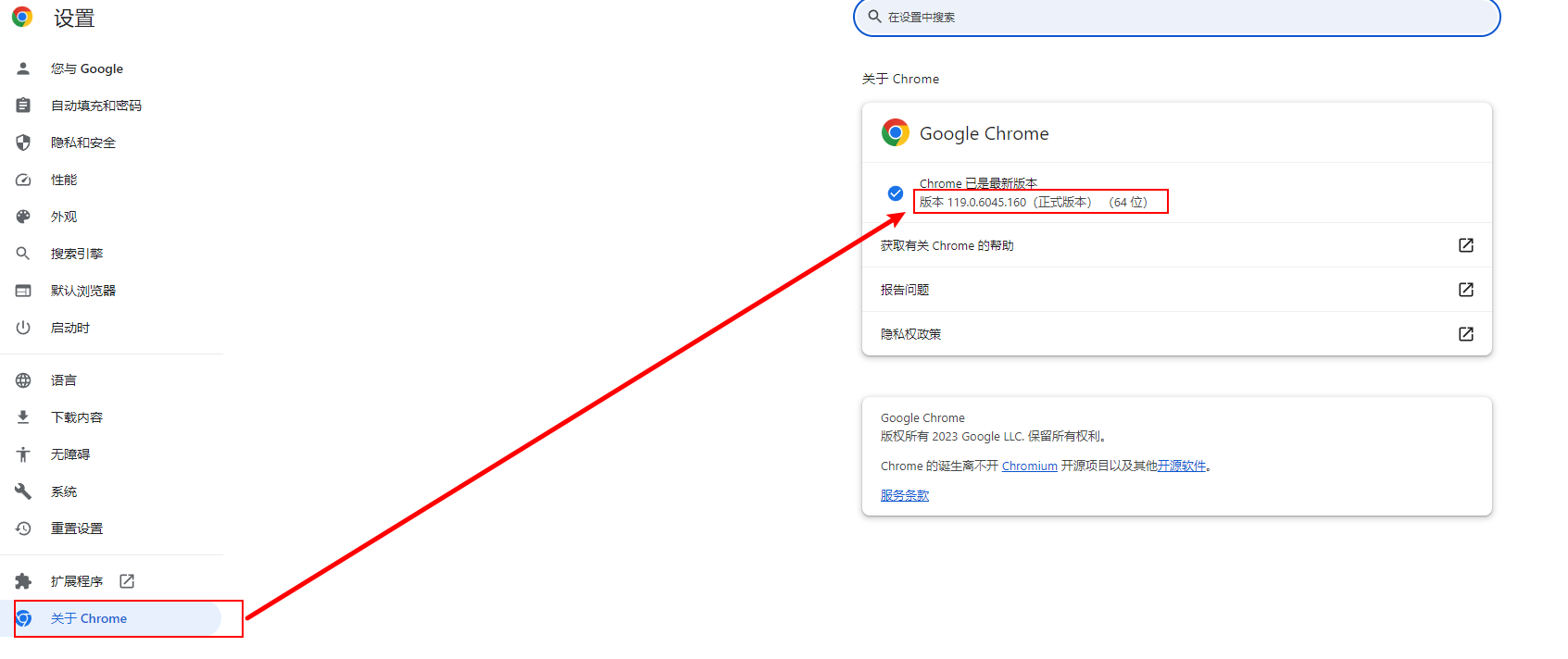
第二步下载对应版本的chrome driver并配置环境变量
下载chrome driver 网址
http://chromedriver.storage.googleapis.com/index.html
没有?还有一个网址
https://googlechromelabs.github.io/chrome-for-testing/#stable
配置环境变量
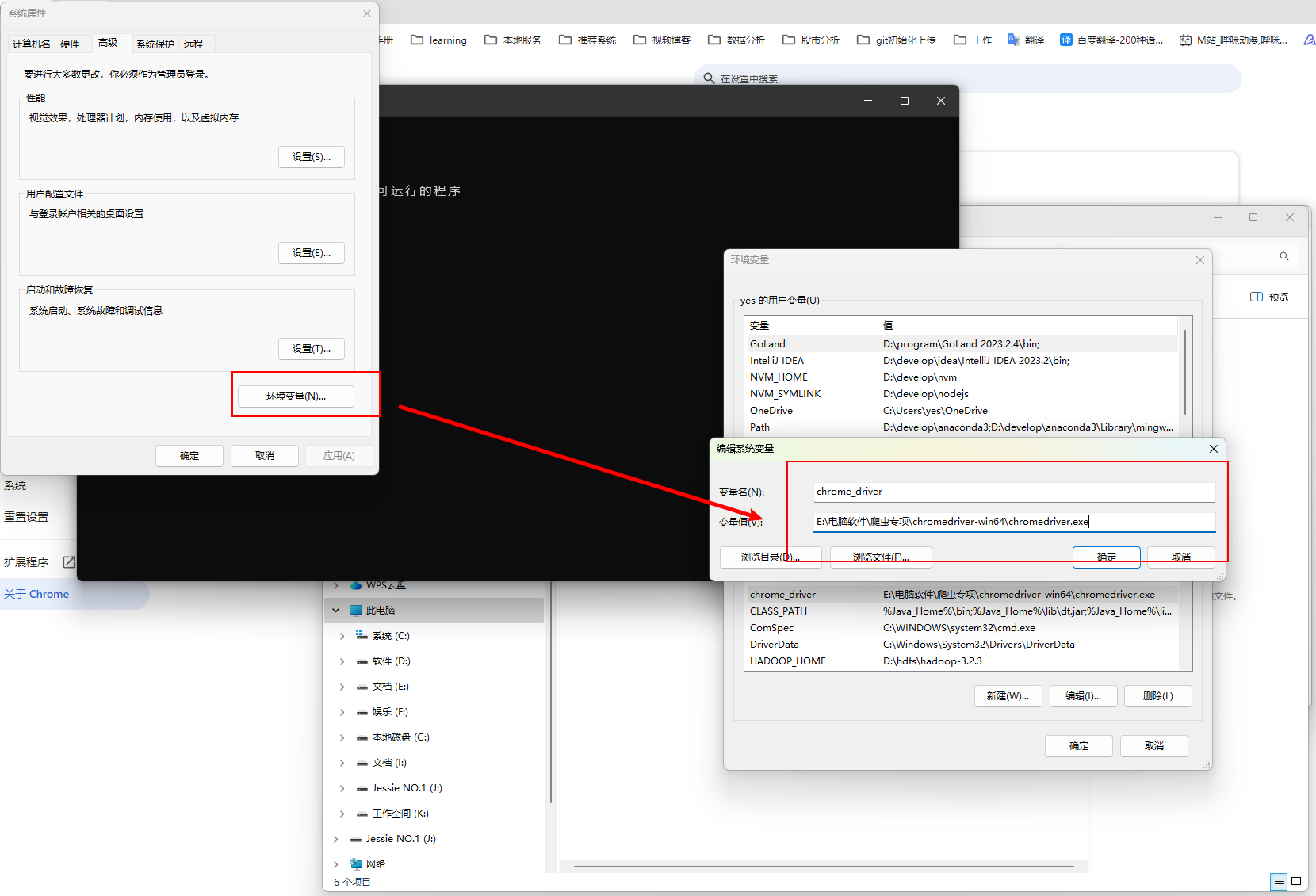
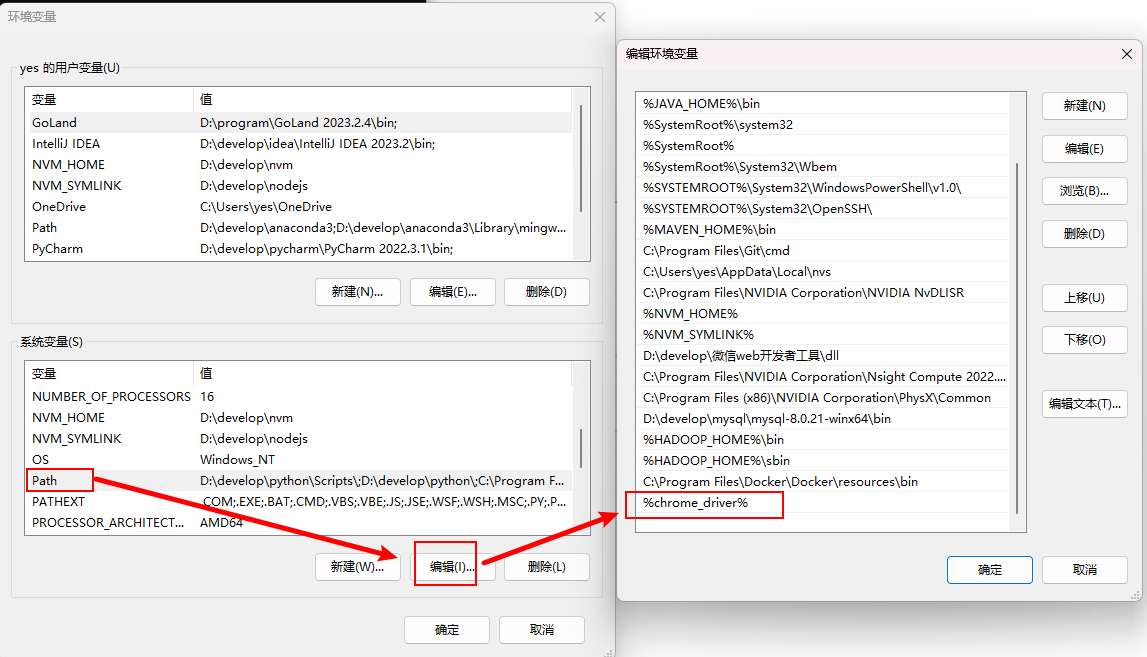
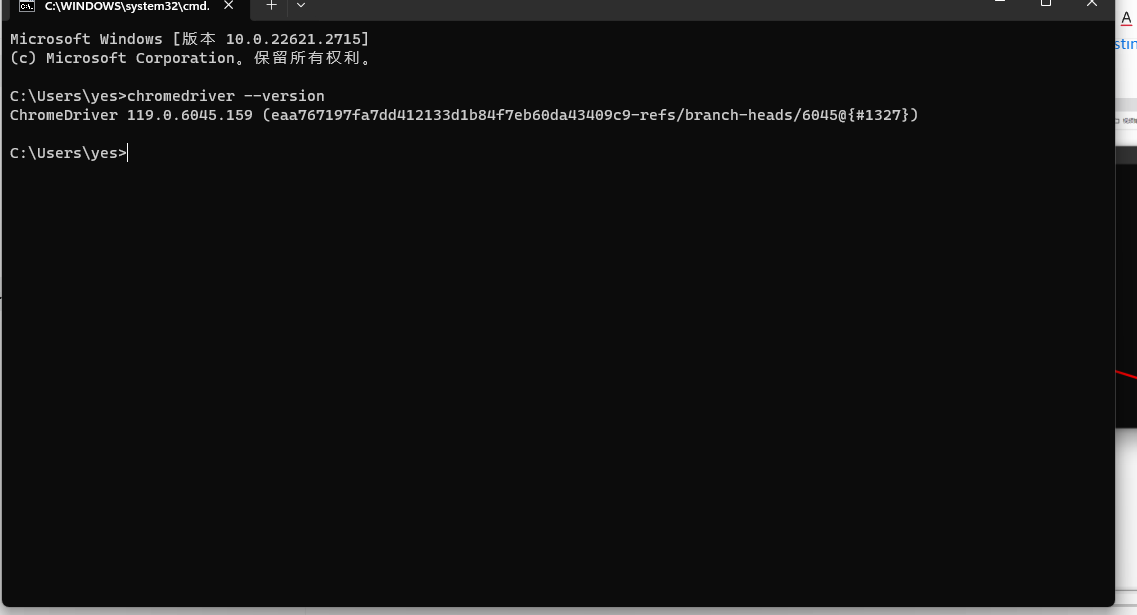
第三步引入对应的python包即可
代码测试
$ python
>>> from selenium import webdriver
>>> browser = webdriver.Chrome()
使用docker 安装Splash
Splash是一个异步的JavaScript渲染服务。它是带有HTTP API的轻量级Web浏览器,能够并行处理多个页面请求,可以在页面上下文中执行自定义的JavaScript以及模拟浏览器中的点击、下滑等操作。Splash的安装方式有两种,一种是下载已经封装好的Docker镜像,另一种是从GitHub下载源码后安装,这里我推荐第一种安装方式。在安装好Docker后,只需要从DockerHub中拉取Splash镜像并运行即可,相关命令如下:
安装docker请找其他帖子,此处略
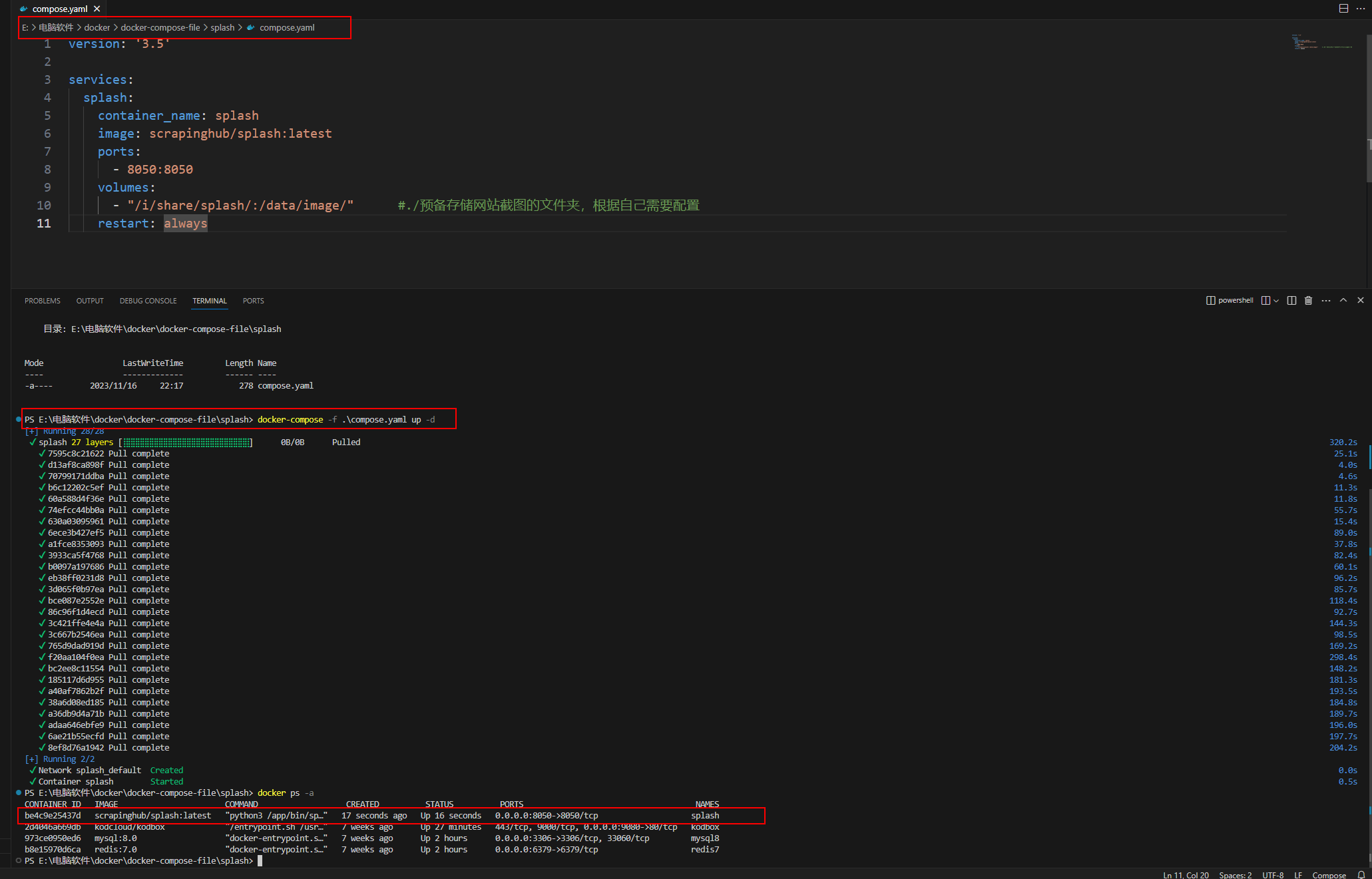
复制以下docker-compose代码到指定文件夹
version: '3.5'
services:
splash:
container_name: splash
image: scrapinghub/splash:latest
ports:
- 8050:8050
volumes:
- "/i/share/splash/:/data/image/" #./预备存储网站截图的文件夹,根据自己需要配置
restart: always
1.切换代码所在文件夹
cd .\电脑软件\docker\docker-compose-file\splash\
2.启动docekr容器
docker-compose -f .\compose.yaml up -d
3.查看运行结果
docker ps -a
安装Puppeteer
使用Puppeteer可以完成大多数手动执行的操作。有开发者开源了支持Python的Puppeteer库,叫作Pyppeteer,其文档网址为https://miyakogi.github.io/pyppeteer/。要注意的是,它仅支持在Python 3.6+ 的环境下运行。同样,我们可以使用Python包管理工具pip来安装Pyppeteer,命令如下:
$ pip install pyppeteer

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









