




 本文详细解读了Sharding-JDBC的历史背景、基本概念,涉及数据节点、逻辑表、分片策略等,并深入解析了执行流程,包括SQL解析、路由策略和结果归并。适合了解分布式数据库分片实践的开发者。
本文详细解读了Sharding-JDBC的历史背景、基本概念,涉及数据节点、逻辑表、分片策略等,并深入解析了执行流程,包括SQL解析、路由策略和结果归并。适合了解分布式数据库分片实践的开发者。
目录
一、介绍
1.1 历史由来
- Sharding-JDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被包含在 Sharding-Sphere 中,之后该项目进入进入Apache孵化器,4.0版本之后的版本为Apache版本。
- ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding- Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和 数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
官方地址https://shardingsphere.apache.org/document/current/cn/overview/
1.2 Sharding-JDBC
-
在这里我们只关注Sharding-JDBC,定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
a. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
b. 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
c. 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。 -
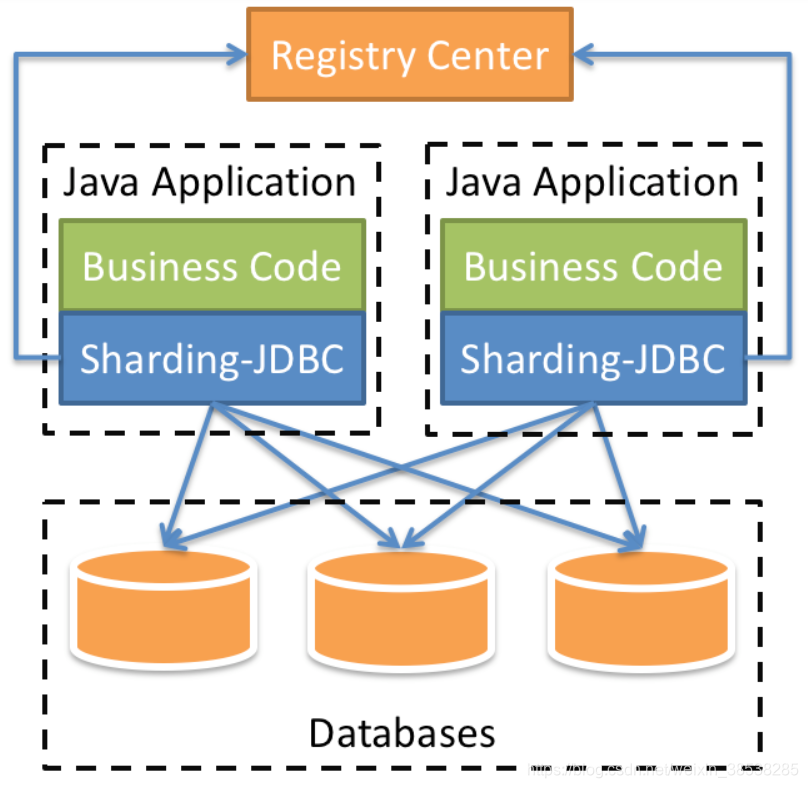
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库 分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
-
使用Sharding-Jdbc前需要人工对数据库进行分库分表,在应用程序中加入 Sharding-Jdbc的Jar包,应用程序通过Sharding-Jdbc操作分库分表后的数据库和数据表,由于Sharding-Jdbc是对 Jdbc驱动的增强,使用Sharding-Jdbc就像使用Jdbc驱动一样,在应用程序中是无需指定具体要操作的分库和分表 的。
二、基本概念
2.1 数据节点
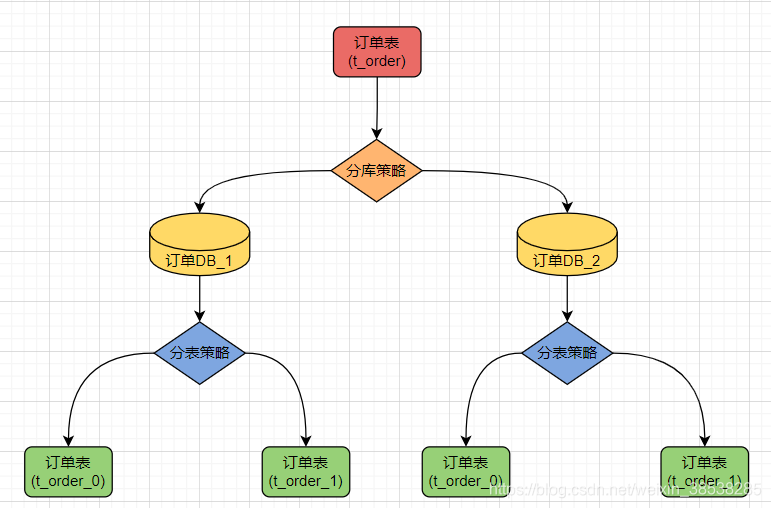
数据节点是数据分片的最小单元。由数据源名称和数据表组成,如:order_db_1.t_order_0、order_db_1.t_order_1、order_db_2.t_order_0、order_db_2.t_order_1。
2.2 逻辑表
逻辑表是水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
2.3 真实表
在分片的数据库中真实存在的物理表。即上个示例中的 t_order_0 到 t_order_9。
2.4 绑定表
指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。故绑定表之间的分区键要完全相同。
2.5 广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
2.6 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
2.7 分片算法
通过分片算法将数据分片,支持通过 =、>=、<=、>、<、BETWEEN 和 IN 分片。 分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供 3 种分片算法。 由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 标准分片算法
对应 StandardShardingAlgorithm,用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。需要配合 StandardShardingStrategy 使用。 - 复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。 - Hint分片算法
对应 HintShardingAlgorithm,用于处理使用 Hint 行分片的场景。需要配合 HintShardingStrategy 使用。
2.8 分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供 4 种分片策略。
- 标准分片策略
对应 StandardShardingStrategy。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。 StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。 RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, <= 分片,如果不配置 RangeShardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。 - 复合分片策略
对应 ComplexShardingStrategy。复合分片策略。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。 ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。 - Hint分片策略
对应 HintShardingStrategy。通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。 - 不分片策略
对应 NoneShardingStrategy。不分片的策略。
2.9 SQL Hint
对于分片字段非 SQL 决定,而由其他外置条件决定的场景,可使用 SQL Hint 灵活的注入分片字段。 例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint 支持通过 Java API 和 SQL 注释(待实现)两种方式使用。 详情请参见强制分片路由。
三、执行步骤
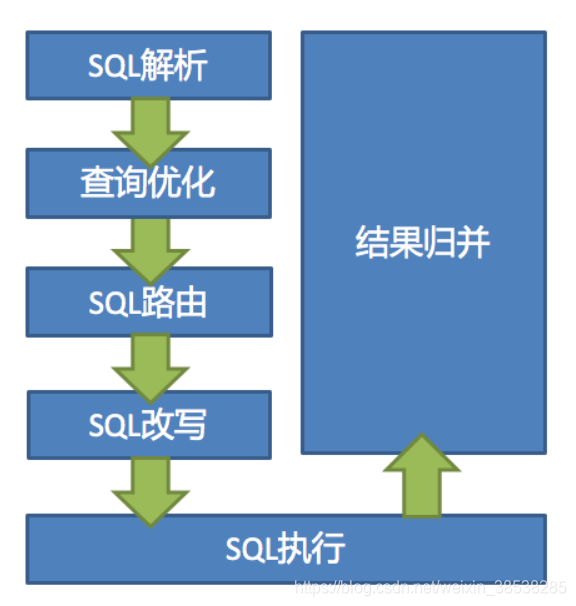
Sharding-jdbc的核心由 SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并的流程组成。
3.1 SQL解析
SQL解析分为词法解析和语法解析。 词法解析器用于将 SQL 拆解为不可再分的原子符号,称为 Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将词法解析器的输出转换为抽象语法树。
例如,以下 SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图。
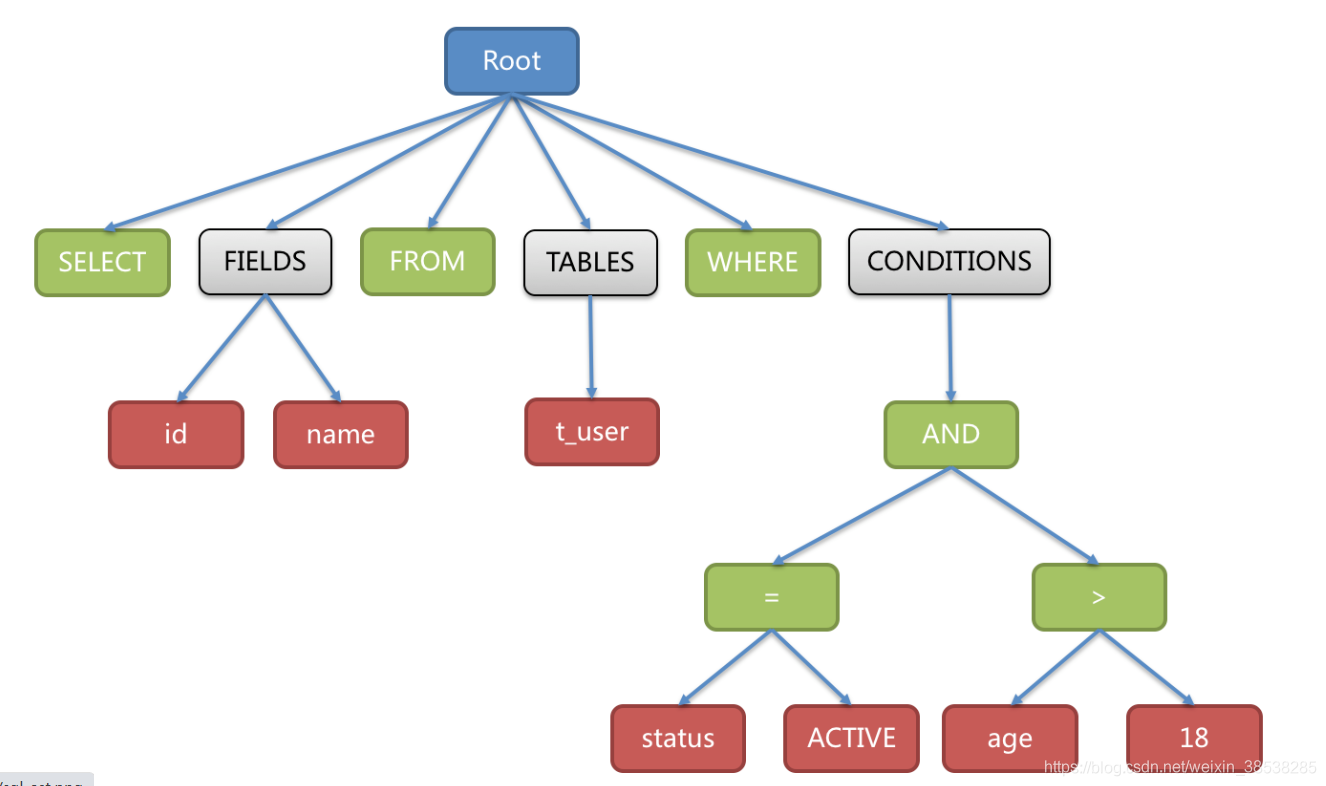
最后,通过 visitor 对抽象语法树遍历构造域模型,通过域模型(SQLStatement)去提炼分片所需的上下文,并标记有可能需要改写的位置。 供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。 SQL 的一次解析过程是不可逆的,一个个 Token 按 SQL 原本的顺序依次进行解析,性能很高。 考虑到各种数据库 SQL 方言的异同,在解析模块提供了各类数据库的 SQL 方言字典。
3.2 执行器优化
合并和优化分片条件,如 OR 等。
3.3 SQL 路由
- SQL路由就是把针对逻辑表的数据操作映射到对数据结点操作的过程。
- 根据-解析上下文匹配数据库和表的分片策略,并生成路由路径。
根据有无分键分为分片路由和广播路由。
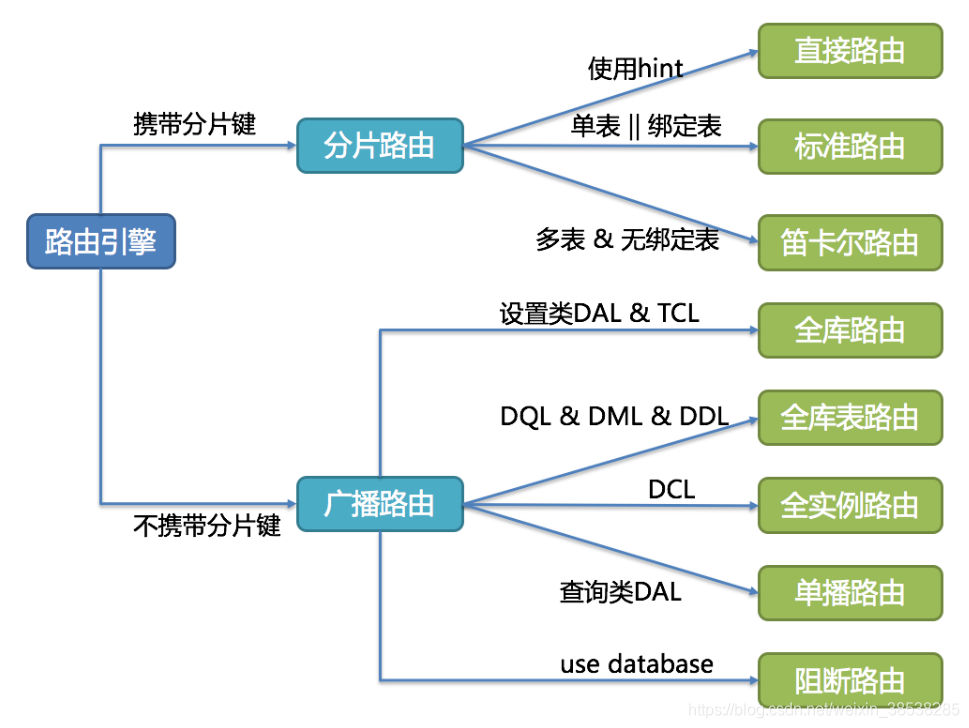
3.3.1 分片路由
用于根据分片键进行路由的场景,又细分为直接路由、标准路由和笛卡尔积路由这 3 种类型。
1. 直接路由
直接路由需要通过 Hint(使用 HintAPI 直接指定路由至库表)方式分片,并且是只分库不分表的前提下,则可以避免 SQL 解析和之后的结果归并。 因此它的兼容性最好,可以执行包括子查询、自定义函数等复杂情况的任意 SQL。直接路由还可以用于分片键不在 SQL 中的场景。
2. 标准路由
标准路由是 ShardingJDBC 最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的 SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是 BETWEEN 或 IN 时,则路由结果不一定落入唯一的库(表),因此一条逻辑 SQL 最终可能被拆分为多条用于执行的真实 SQL。 举例说明,如果按照 order_id 的奇数和偶数进行数据分片,一个单表查询的 SQL 如下:
SELECT * FROM t_order WHERE order_id IN (1, 2);
那么路由的结果应为:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
绑定表的关联查询与单表查询复杂度和性能相当。举例说明,如果一个包含绑定表的关联查询的 SQL 如下:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
那么路由的结果应为:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
3. 笛卡尔路由
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。 如果上个示例中的 SQL 并未配置绑定表关系,那么路由的结果应为:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
笛卡尔路由查询性能较低,需谨慎使用。
于不携带分片键的 SQL,则采取广播路由的方式。根据 SQL 类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这 5 种类型。
3.3.2 广播路由
对于不携带分片键的 SQL,则采取广播路由的方式。根据 SQL 类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这 5 种类型。
1. 全库表路由
全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的 DQL 和 DML,以及 DDL 等。例如:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
则会遍历所有数据库中的所有表,逐一匹配逻辑表和真实表名,能够匹配得上则执行。路由后成为
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
2. 全库路由
全库路由用于处理对数据库的操作,包括用于库设置的 SET 类型的数据库管理命令,以及 TCL 这样的事务控制语句。 在这种情况下,会根据逻辑库的名字遍历所有符合名字匹配的真实库,并在真实库中执行该命令,例如:
SET autocommit=0;
在 t_order 中执行,t_order 有 2 个真实库。则实际会在 t_order_0 和 t_order_1 上都执行这个命令。
3. 全实例路由
全实例路由用于 DCL 操作,授权语句针对的是数据库的实例。无论一个实例中包含多少个 Schema,每个数据库的实例只执行一次。例如:
CREATE USER customer@127.0.0.1 identified BY '123';
这个命令将在所有的真实数据库实例中执行,以确保 customer 用户可以访问每一个实例。
4. 单播路由
单播路由用于获取某一真实表信息的场景,它仅需要从任意库中的任意真实表中获取数据即可。例如:
DESCRIBE t_order;
t_order 的两个真实表 t_order_0,t_order_1 的描述结构相同,所以这个命令在任意真实表上选择执行一次。
5. 阻断路由
阻断路由用于屏蔽 SQL 对数据库的操作,例如:
USE order_db;
这个命令不会在真实数据库中执行,因为 ShardingSphere 采用的是逻辑 Schema 的方式,无需将切换数据库 Schema 的命令发送至数据库中。
3.4 SQL 改写
将基于逻辑表开发的SQL改写成可以在真实数据库中可以正确执行的语句。比如查询 t_order 订单表,我们实际开发中 SQL是按逻辑表 t_order 写的。
SELECT * FROM t_order
但分库分表以后真实数据库中 t_order 表就不存在了,而是被拆分成多个子表 t_order_n 分散在不同的数据库内,还按原SQL执行显然是行不通的,这时需要将分表配置中的逻辑表名称改写为路由之后所获取的真实表名称。
SELECT * FROM t_order_n
3.5 SQL 执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率,他能在以下两种模式自适应切换:
3.5.1 内存限制模式
使用此模式的前提是,Sharding-JDBC对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对 某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。
3.5.2 连接限制模式
使用此模式的前提是,Sharding-JDBC严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。
内存限制模式适用于OLAP操作,可以通过放宽对数据库连接的限制提升系统吞吐量; 连接限制模式适用于OLTP操 作,OLTP通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线系统数据库资源能够被 更多的应用所使用,是明智的选择。
3.6 结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。 Sharding-JDBC支持的结果归并从功能上可分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的 关系。
归并引擎的整体结构划分如下图:
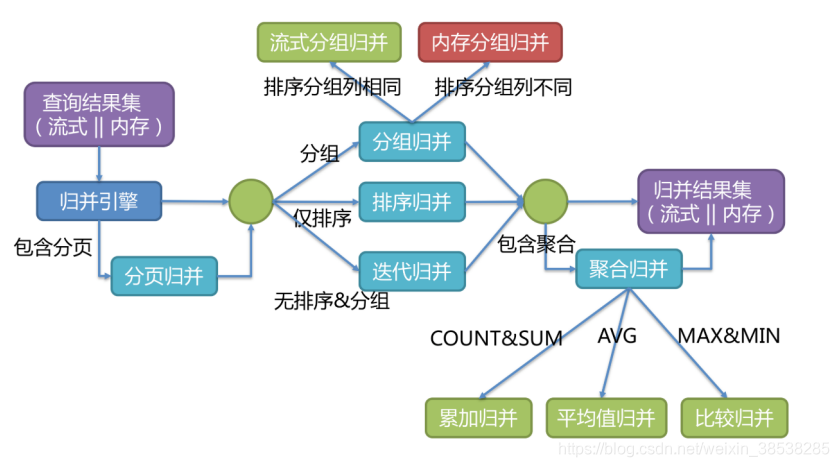
结果归并从结构划分可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
- 内存归并很容易理解,他是将所有分片结果集的数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等 计算之后,再将其封装成为逐条访问的数据结果集返回。
- 流式归并是指每一次从数据库结果集中获取到的数据,都能够通过游标逐条获取的方式返回正确的单条数据,它与 数据库原生的返回结果集的方式最为契合。
- 装饰者归并是对所有的结果集归并进行统一的功能增强,比如归并时需要聚合SUM前,在进行聚合计算前,都会通 过内存归并或流式归并查询出结果集。因此,聚合归并是在之前介绍的归并类型之上追加的归并能力,即装饰者模式。
四、总结
- Sharding-JDBC是一个轻量级的java框架,我们在项目中使用时需要引入对应的依赖。
- Sharding-JDBC不能分库分表,只是让我们更方便的操作分库分表。在使用Sharding-JDBC前需要我们自己根据业务进行分库分表。

















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









