






 本文深入解析了隐马尔可夫模型(HMM),包括其核心概念转移概率与发射概率,以及如何应用于股市预测、语音识别等领域。文章还详细介绍了HMM的参数设置、计算过程及EM算法的应用。
本文深入解析了隐马尔可夫模型(HMM),包括其核心概念转移概率与发射概率,以及如何应用于股市预测、语音识别等领域。文章还详细介绍了HMM的参数设置、计算过程及EM算法的应用。
Markev assumption
转移概率:P(qt|qt-1,qt-2,qt-3…q1)=P(qt|qt-1)
表示隐状态的连续序列,而一个隐状态的发生的概率近似认为只与其上一状态有关,将上一状态的概率近似替代所有隐状态的序列发生的概率。
除需知道隐藏状态之间的关系外,还需要知道隐状态到观测状态的概率
发射概率:P(yt|qt)
表示隐状态到观测变量的映射概率。
而两个概率决定隐马尔可夫链
应用领域:
简单股市:预测牛市还是熊市
演讲识别:声音是一段信号,可将其分为多段观测值;此外还有隐状态,对于英语而言是元辅音的发音。
知道所有的隐状态,观测值之间相互独立
discrete transition probability:
P(qt|q1,...qt-1,y1,...yt-1)=P(qt|qt-1)
HMM隐藏值必须是离散的,123或abc等;而观测值可离散也可连续
continous/discrete measurement probability:
P(yt|q1,...,qt-1,qt,y1,...,yt-1)=P(yt|qt)
-
表示方法:
1.transition prob转移矩阵
对于transition prob矩阵A的维度:
若有K个状态,则矩阵维度K*K
【P(qt=1|qt-1=1) 】
P(qt=k|qt-1=k)
每行元素和为1
2.emmission prob
离散时:矩阵B的维度为K*L(L为y所对应的状态)
连续时,,,,,,
P(y1,y2,y3)=SUM P(y3|q3)P(q3|q2)P(y2|q2)P(q2|q1)P(y1|q1)P(q1)
所以,HMM中三个参数λ={A,B,π}
π为初始状态值
应用:
用HMM进行voice recognition,如识别人们说的10个单词
具体做法:λcat=arg max logP(y1,y2|λ) ....
到来一个新的数据y*,进行计算估计P(Y|λ)
P(y1,...yT|λ)=
公式的计算量是很大的,进行计算时:
定义αi(t)=P(y1,y2,,,yt,qt=i)=
αi1=P(y1,q1=i)=P(y1|q1)P(q1)=πbi(y1)
αj2=P(y1,y2,q2=j)=P(y2|q2=j)P(q2|q1)P(y1|q1)P(q1)=∑1-kP(y1,y2,q1=i,q2=j)=P(y2|q2=j)P(q2|q1)αi1=bj(y2)*ai,j*ai(j)
αj(T)=bj(yT)∑1-kαi,j*αi(T-1)
EM算法公式
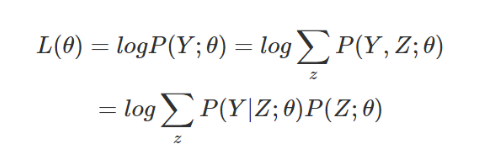

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









