



 本文汇总了GlobalVectors(GloVe)、fastText、EmbeddingfromLanguageModels(ElMo)及BidirectionalEncoderRepresentationsfromTransformers(BERT)四种公开语言模型的预训练版本下载地址。介绍了各模型的特点及单词覆盖范围,适合自然语言处理领域的研究者和开发者参考。
本文汇总了GlobalVectors(GloVe)、fastText、EmbeddingfromLanguageModels(ElMo)及BidirectionalEncoderRepresentationsfromTransformers(BERT)四种公开语言模型的预训练版本下载地址。介绍了各模型的特点及单词覆盖范围,适合自然语言处理领域的研究者和开发者参考。
根据徐老师最新讲解论文使用的四种公开语言模型 ,经过本人上网查找,现将各预训练好的模型下载地址整合如下:
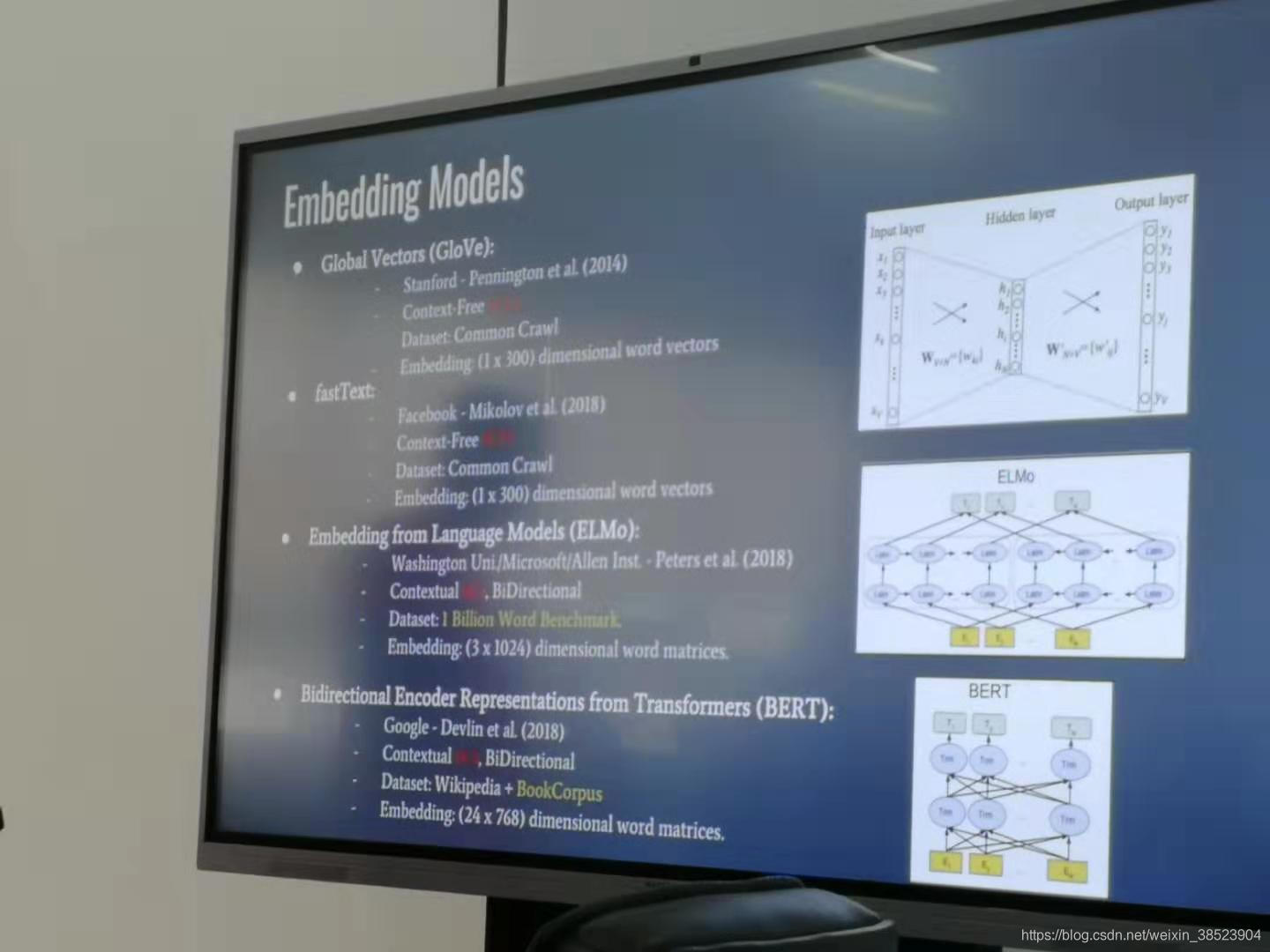
Global Vectors(GloVe):2014年, 1*300dim glove.840B.300d.txt:2196017个单词
fastText:crawl-300d-2M-subword.vec:2000000个单词
fastText:2018年, 1*300dim
Embedding from Language Models(ElMo):2018年, 3*1024
Bidirectional Encoder Representations from Transformers(BERT):2018年, 24*768
链接1:https://www.infoq.cn/article/1fu*vYWCD8PlIartPZYV
链接2:https://www.jianshu.com/p/5c715577a3f5
链接3(如何使用):https://www.cnblogs.com/jiangxinyang/p/10241243.html
https://blog.youkuaiyun.com/leyounger/article/details/79343404

















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









