








计数排序
计数排序不是一个比较排序算法,该算法于1954年由 Harold H. Seward提出,通过计数将时间复杂度降到了O(N)。
计数排序就是在数组中找到一个最大值,构建最大值+ 1长度的bucket数组,例如 1 2 3 4 9 ,最大值为9数组长度为10,为0留一个位置。然后遍历数组,根据数值放到bucket数组对应的index中,index个数+ 1,然后把bucket信息倒出来。
private static void countSort(int[] arr) {
int max = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
int[] bucket = new int[max + 1];
//记录每个元素出现的频率
for (int i = 0; i < arr.length; i++) {
//为arr[i]位置上的数结果+ 1
bucket[arr[i]]++;
}
int temp = 0;
//按照bucket的结果,按照频率把数据拿出来即可
for (int i = 0; i < bucket.length; i++) {
for (int j = 0; j < bucket[i]; j++) {
arr[temp++] = i;
}
}
}
2.基数排序
基数排序
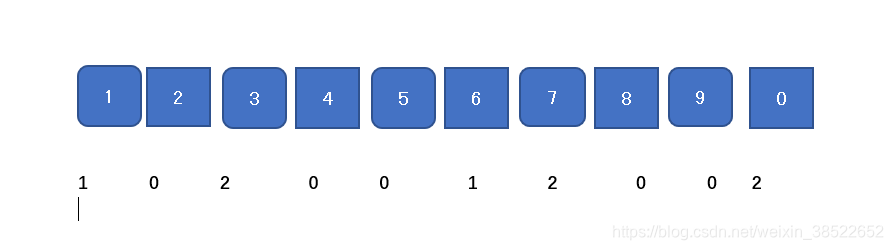
arr[17,23,0,96,17,23,13,1,100]
先分堆,统计每个数频次,基于数据状况的排序,不基于数据比较
要求数据状况在很小的范围,否则复杂度很高,样本必须为十进制的数
a.首先找到最大值,确定最大值为100,其中100是三位十进制
b.不足补0,13变013,依次类推
b.准备十个桶,挨个遍历,根据个位数去选择去哪个桶
c.将桶中数据依次倒出
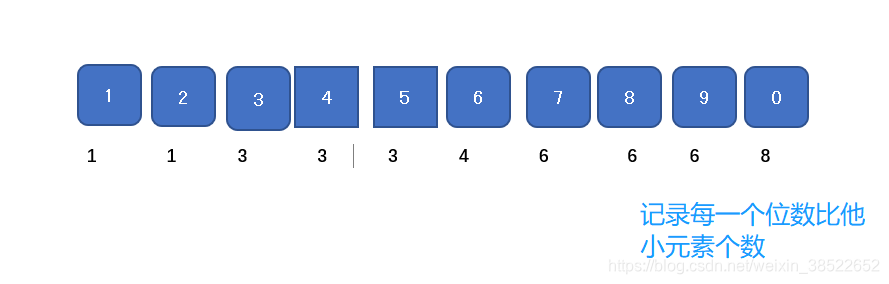
d.根据十位数字进桶、将桶中数据倒出
e.根据百位数组进行桶,将桶中数据导出
f.数字有序

- 首先找到最大值100,获取最大值的位数,100的位数为3
先按照各位数遍历
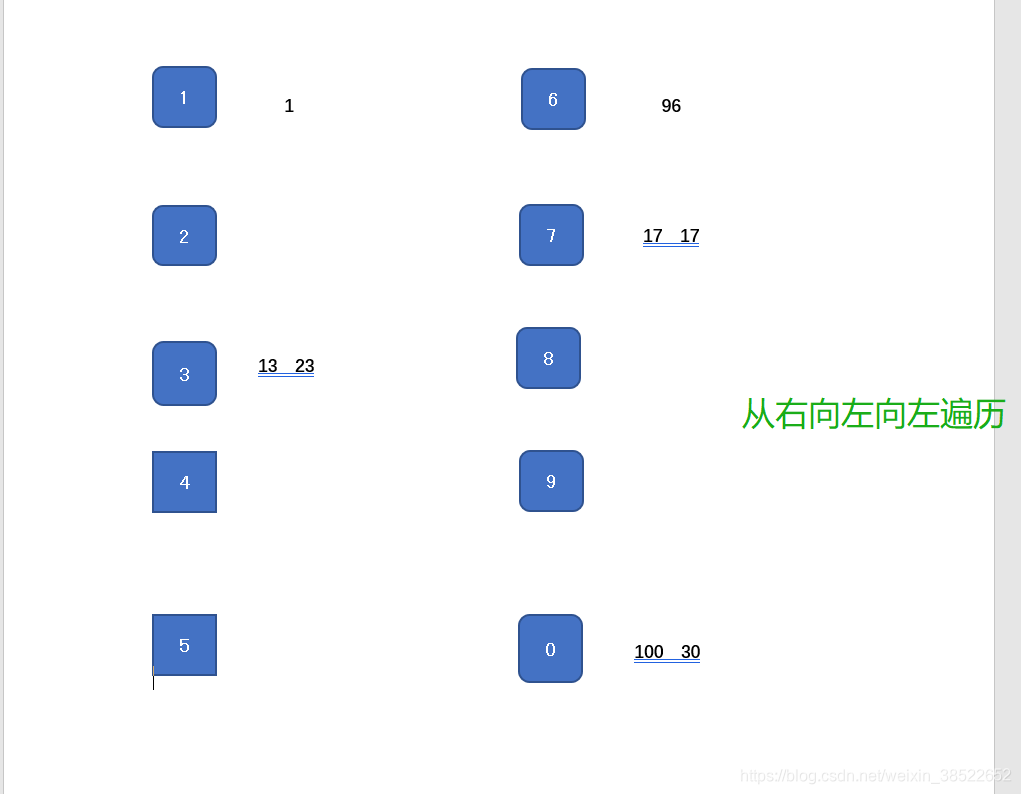
4. 从后向前遍历,找到我对应的对应位上数向前挪一个位置,就是我要进去了的位置。
5. for循环存放信息,将存放信息放进数组中。
public static void radixSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
radixSort(arr, 0, arr.length - 1, maxbits(arr));
}
public static int maxbits(int[] arr) {
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
//先找到最大值
max = Math.max(max, arr[i]);
}
int res = 0;
//获取最大值的位数
while (max != 0) {
res++;
max /= 10;
}
return res;
}
// arr[begin..end]排序
public static void radixSort(int[] arr, int L, int R, int digit) {
final int radix = 10;
int i = 0, j = 0;
// 有多少个数准备多少个辅助空间
int[] bucket = new int[R - L + 1];
for (int d = 1; d <= digit; d++) { // 有多少位就进出几次
// 10个空间
int[] count = new int[radix]; // count[0..9]
//
for (i = L; i <= R; i++) {
//获取第d位上的数,记录下来
j = getDigit(arr[i], d);
count[j]++;
}
//统计小于等于个位数上数值个数有几个
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
//然后将比这个范围小的数减去一,
//这样的话就可以记录每一个个位数值上信息,就按照个位数从小到大的排好了
for (i = R; i >= L; i--) {
//获取这个数的位信息,
j = getDigit(arr[i], d);
//由于基数排序需要十个队列,为了节省空间,
//例如当前digit为1, i = 22, 那么j = 2,
// count[2] 是找到个位数比2的值要小,那么count[2]个数减去1,就是我要去的位置了
bucket[count[j] - 1] = arr[i];
count[j]--;
}
for (i = L, j = 0; i <= R; i++, j++) {
arr[i] = bucket[j];
}
}
}
public static int getDigit(int x, int d) {
return ((x / ((int) Math.pow(10, d - 1))) % 10);
}
- 桶排序思想下的排序都是不基于比较的排序,
- 时间复杂度O(N),额外空间复杂度位O(M)
- 应用范围优先,需要样本的数据状况满足桶的划分。
排序算法的稳定性及其汇总
同样值得个体之间,如果不因为排序而改变相对次序,就是这个排序是有稳定性得,否则就没有。
不具备稳定性的排序:选择排序、快速排序、堆排序
备稳定性的排序:归并排序、插入排序、冒泡排序、桶排序
目前没有找到时间复杂度O(N *logN),额外空间复杂度O(1),又稳定的排序
排序算法的稳定性及其汇总
-
各个排序区别
选择排序,先选出最小值与最小值交换.插入排序,当前值与前面的值比大小,如果比前面值小,交换,一直到前面没有比我小的或者是到头了
冒泡排序, 向后找,相同时不交换位置,不同时且大于后面的值交换
归并排序,先拆分,如果左面小于等于右面,拷贝左面
堆排序, 自己维持一个二叉树,将整体变成大根堆
快速排序, 随机选一个数做partition,然后小于等于区向后挪,大于区向前找,之后再与大于等于区第一个数交换位置
希尔排序, 改造的插入排序
| 排序名称 | 时间复杂度 | 额外空间复杂度 | 是否稳定 |
|---|---|---|---|
| 选择排序 | O(N ^2) | O(1) | × |
| – | – | – | – |
| 插入排序 | O(N ^2) | O(1) | √ |
| – | – | – | – |
| 冒泡排序 | O(N ^2) | O(1) | √ |
| – | – | – | – |
| 归并排序 | O(N *logN) | O(N) | √ |
| – | – | – | – |
| 堆排序 | O(N *logN) | O(1) | × |
| – | – | – | – |
| 桶排序 | O(N *logN) | O(M) | √ |
| – | – | – | – |
| 快速排序 | O(N ^2) | O(1) | × |
-
.排序的选择?
A.不在乎稳定性,在短时间内快速排序,只在乎指标与常数时间,选择快排,常数时间最低
B.额外空间少,使用堆排序
C.追求稳定用归并 -
归并排序可以将空间复杂度变为O(1)么,可以的,使用内部缓存法,但用完就不稳定了。
原地归并排序,空间复杂度是O(1)也稳定,但是时间复杂度变为O(N^2)
快速排序可以做稳定么?可以,但额外空间复杂度变0(N), o1 stable sort
有一道题目,奇数在左边,偶数在右边,还要求原始相对次数不变,时间复杂度是O(N),额外空间复杂度是O(1)
这个是不可能实现的,因为这是0,1标准排序,那么必须要交换位置,肯定不稳定。
-
经典快排,如果L-R不够60.直接使用插入排序,O(N^2)在常数很优,N不大时常数很好,O(N*logN)在调度上很优


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









