






**
A Simple Convolutional Generative Network for Next Item Recommendation
**
2019 WSDM
这篇文章主要是与Caser进行对比,设计了NextItNet模型,它借鉴pixelCNN的思想,采用层叠的1维空洞卷积扩大感受野来提取item序列特征,加入了残差学习的机制以防止梯度消失的问题,并且为了减少模型中的参数,使用了1*1卷积核进行降维和升维操作。
Problem
- 基于RNN的序列推荐模型,通常依赖于整个过去的隐藏状态,不能充分利用序列进行并行计算,因此模型的速度在训练和评估中受到了限制。
- Caser的局限性:
(1)对长序列数据建模时,使用max pooling不能确定重要特征出现的次数(可能有多个重要特征,但max pooling只提取了一个)并且无法确定该重要特征的位置;
(2)Caser属于浅层网络,难以捕获复杂的关系以及对长期依赖建模;
(3)在生成下一个item时,caser只考虑了最后一个item的条件概率分布。
Caser的大致结构:
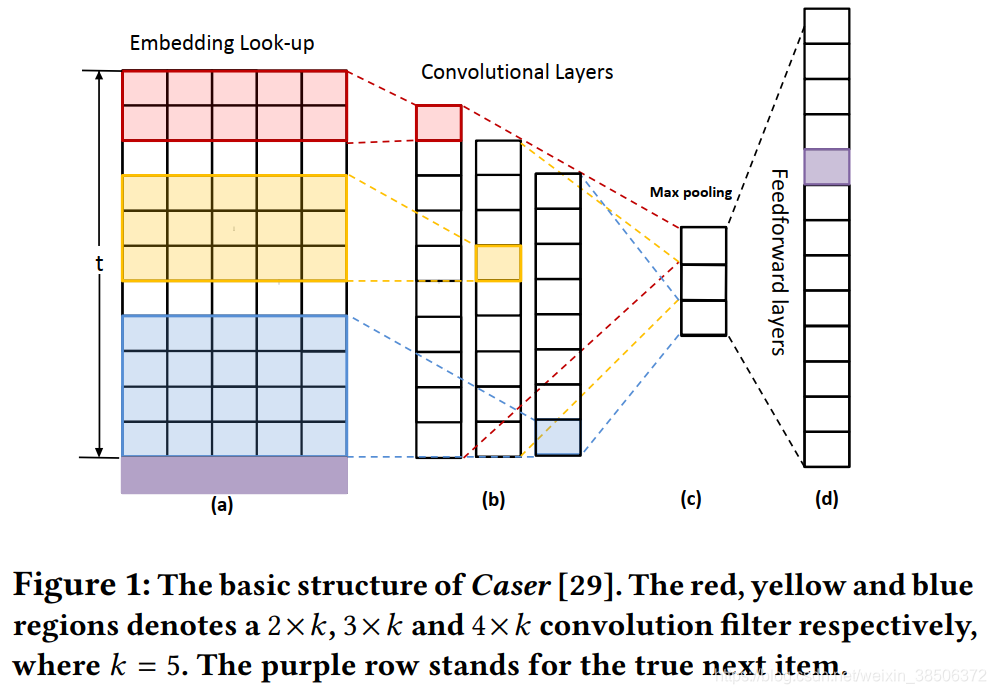
本文模型与Caser的不同之处:
(1)概率估计显式建模了序列中所有item的状态转移分布,而不仅是最后一个item;
(2)NextItNet是一个深层的网络结构;
(3)卷积层采用的1维空洞卷积而不是标准的2维卷积;
(4)没有使用pooling层。
对Caser局限性(3)的解释说明:
Caser和GRURec在预测下一个item xi时,仅考虑了x0:i−1即前i-1个item,即是单一条件概率:p(xi |x0:i−1, θ)
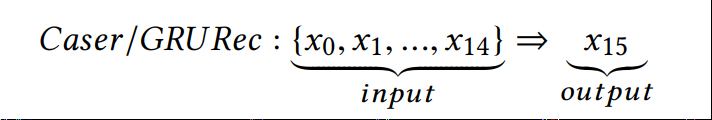
因此,通常情况下需生成多个子序列数据进行模型训练
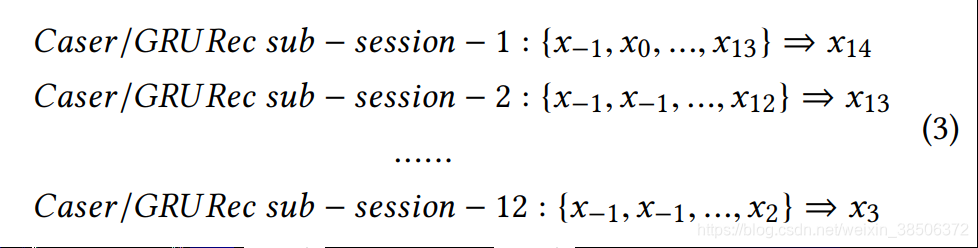
作者认为这种方式是分别对子序列进行各自优化,不能保证最优结果,而且会导致很多计算上的浪费。
于是作者采用了如下预测方式:输入序列为x0:14,目标为x15,输出为x1:15
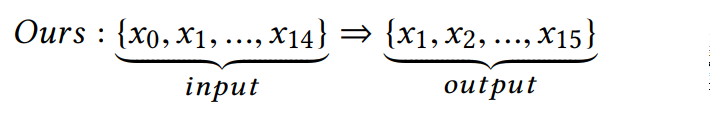
p(x)表示item序列x = {x0, …, xt }的联合概率分布,作者使用了条件分布的乘积对p(x)建模:
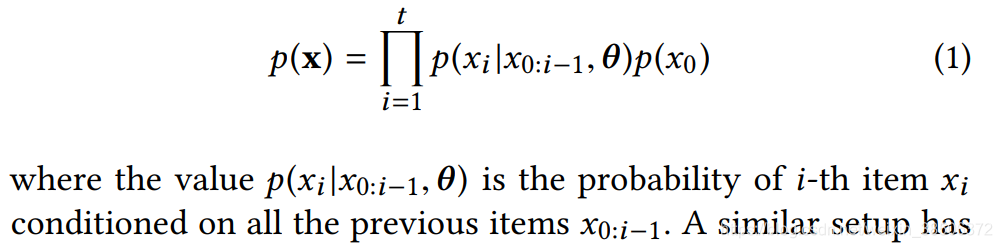
Network Architecture
Embedding Look-up Layer:
给定item序列 {x0, …, xt },对前t个item {x0, …, xt−1} 做embedding,每个item embedding的维度为2k
得到item embedding矩阵大小为t×2k
Dilated layer(空洞卷积层):
使用空洞卷积增大感受野的同时不会改变“图像”大小,,间隔使用零填充,不会引入更多的参数,因此更适用与长序列。
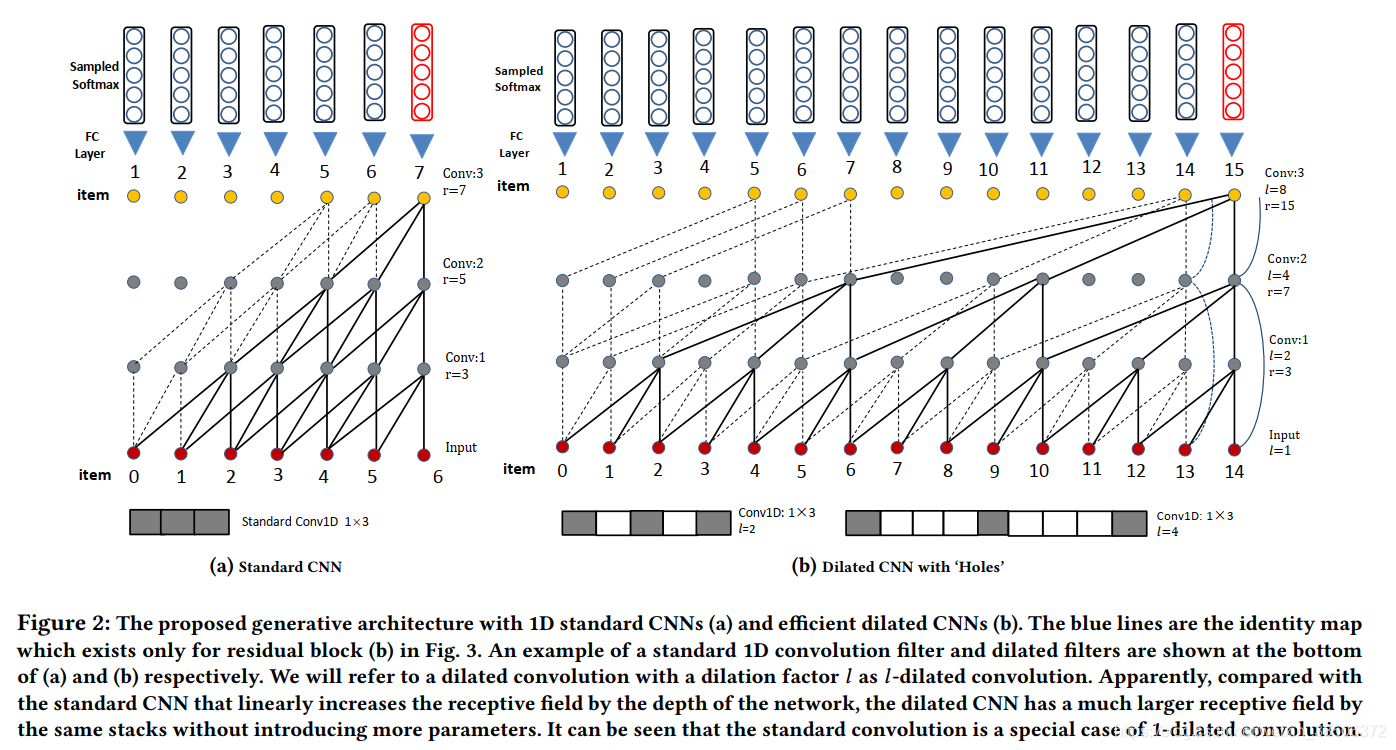
其中,使用的卷积核大小为1×3,感受野(receptive field):r,第j层卷积层:Fj,通道(channel):C,空洞大小:l(每隔l-1个孔卷一下)
b图中,空洞大小l取值为 1,2,4,8,由这四层堆叠而成。当卷积核宽度为f=3时,空洞卷积的感受野呈指数增长为 r=2(j+1)-1,而普通卷积的感受野呈线性增长为r=2j+1。
空洞卷积的窗口大小为:
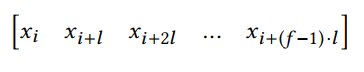
空洞卷积运算的结果:
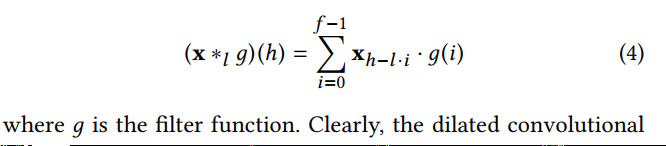
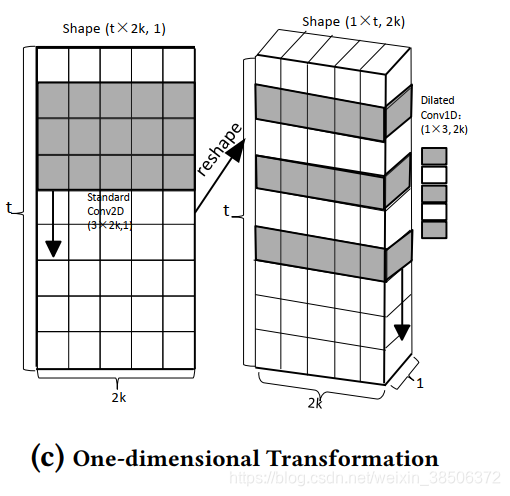
One-dimensional Transformation:
由于卷积层采用了1维空洞卷积,而embedding层得到的是size为t×2k的嵌入矩阵E。因此,需先将E reshape。
Masked Convolutional Residual Network
使用残差块,缓解梯度消失问题。
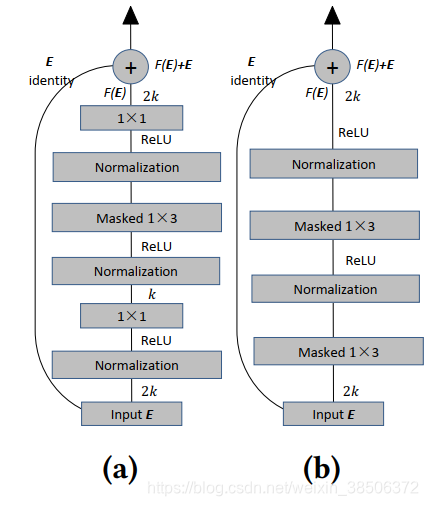
(a)是每经过一次卷积就进行一次残差连接,其中采用1×1卷积将通道数从2k缩到k,再用1x1卷积将其恢复为2k,用以减少网络中的参数;
(b)是每经过两次卷积就进行一次残差连接(如图2(b)中的蓝线)。两图采用的normalization均为layer normalization。
(a)中参数个数:1 × 1 × 2k × k + 1 × 3 × k × k + 1 × 1 × k × 2k = 7k2
(b)中参数个数:1 × 3 × 2k × 2k = 12k2

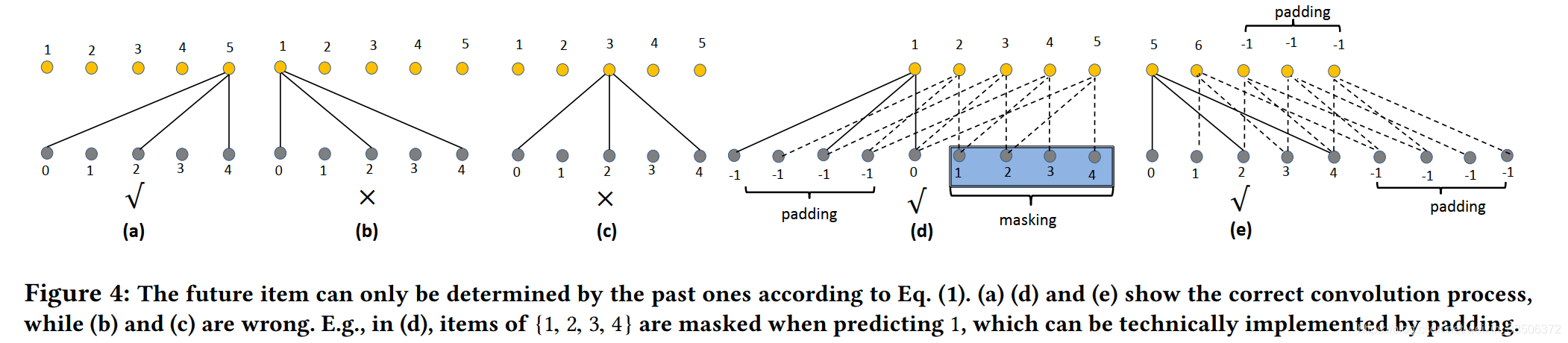
Dropout-mask
为了避免未来的信息泄露,不让网络用未来的item信息预测当前item的信息,作者使用方式(d)进行padding,padding的大小为(f − 1) ∗ l。
Final Layer
在最后一层卷积层的输出Eo∈Rt×2k,由于最后的输出应该为x1:t的概率分布矩阵,即Ep ∈ Rt×n,输出矩阵的每一行代表softmax操作后xi(0 < i ≤ t)的分类概率分布。因此作者在最后一层卷积层后又加了一层卷积卷积核大小为1×1×2k×n(n代表所有item的数量)。与(c)同理,将Eo(t×2k,1)转换为(1×t,2k)的size,然后用n个1×1×2k卷积核卷积。
模型训练
优化目标是最大化log-likelihood, 最大化logP(x)等价于最小化x1:t序列中每个item的二进制交叉熵损失之和。
在实际场景中,softmax开销太大,用smapled softmax和负采样解决,此时要将最后一层1×1卷积层替换为权重Eg∈R2k×n的FC层。
Experiments
数据集

评估标准
MRR@N (Mean Reciprocal Rank) , HR@N (Hit Ratio) and NDCG@N (Normalized Discounted Cumulative Gain). N is set to 5 and 20 for comparison.
实验结果
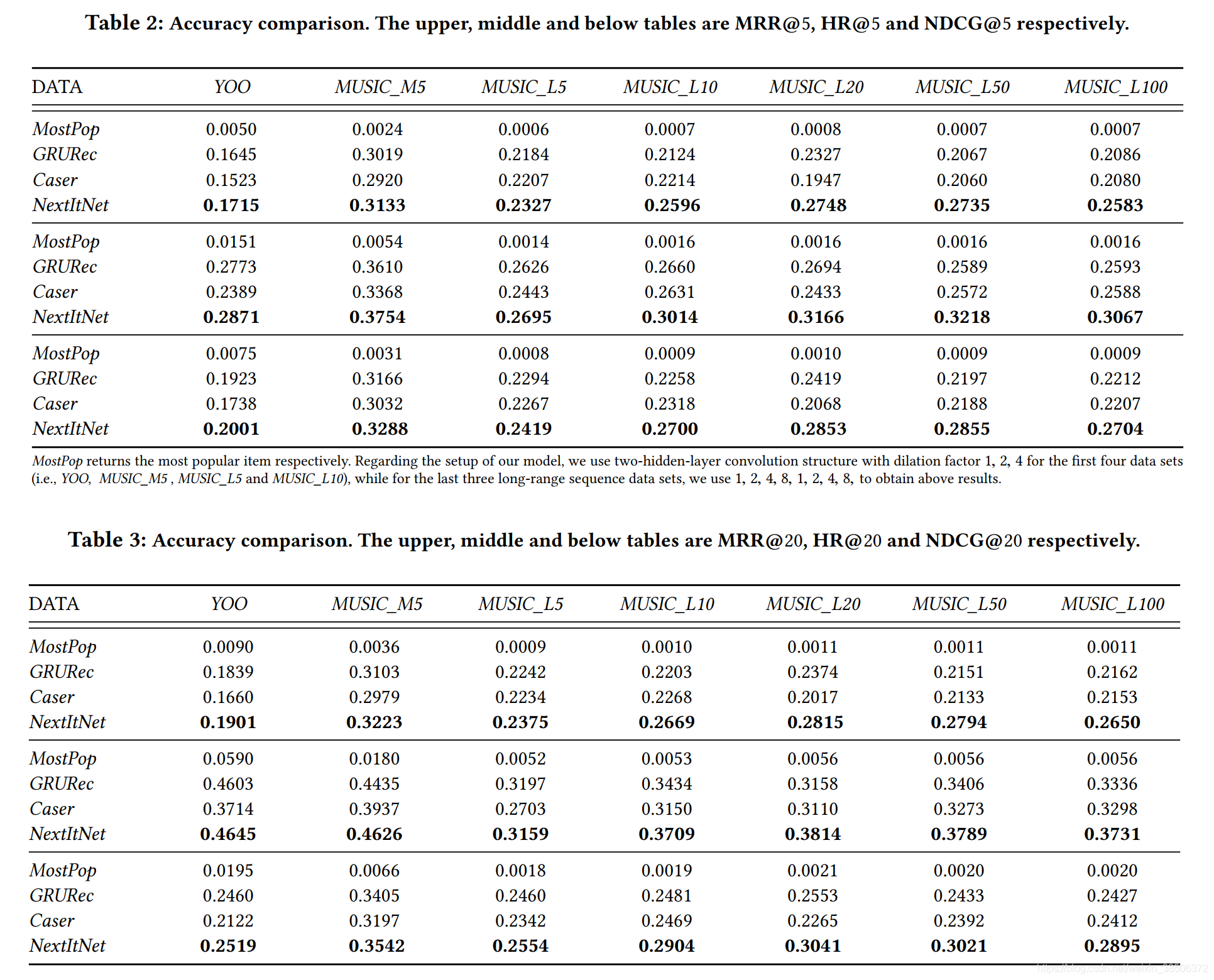
表4中without表示不包含sub-session sequence
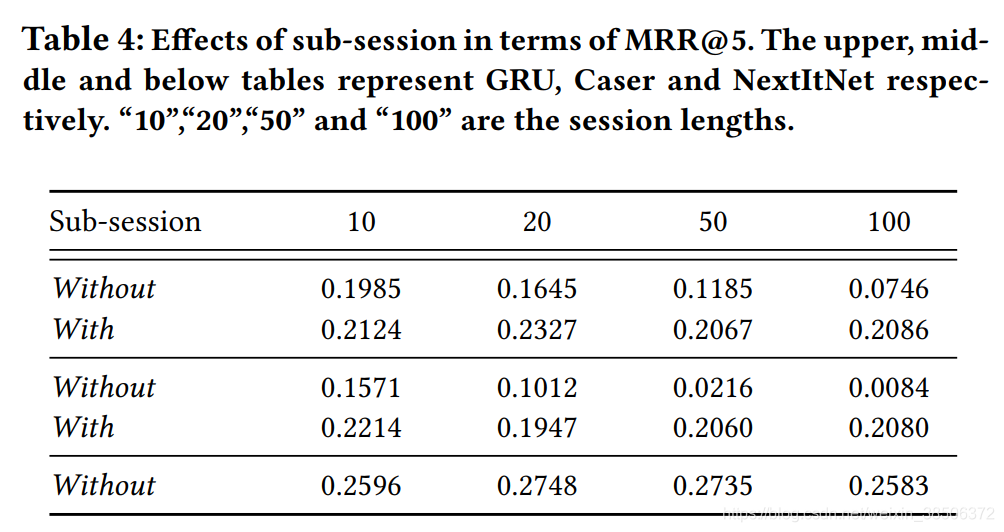
表5证明NextItNet中残差模块提高了模型的性能

表6说明了不同embedding size对模型性能的影响
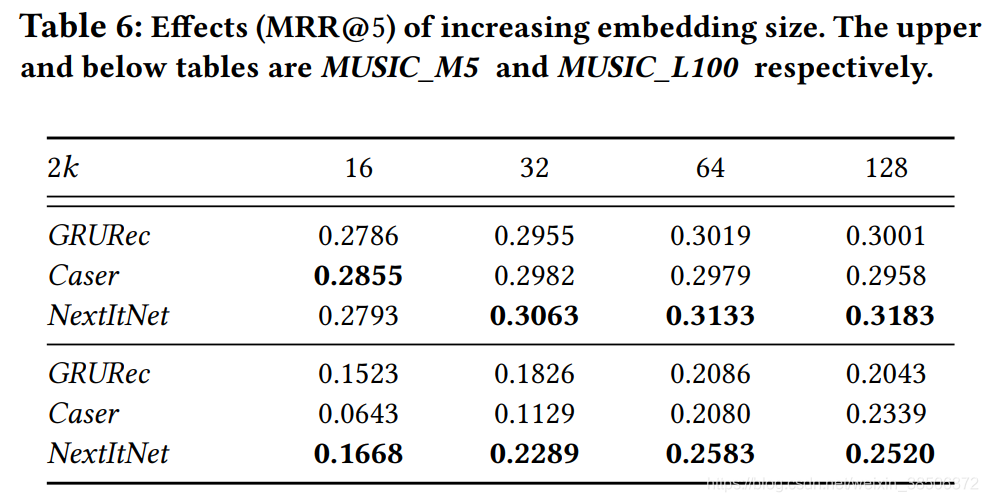
表7展示了三个模型训练速度的比较
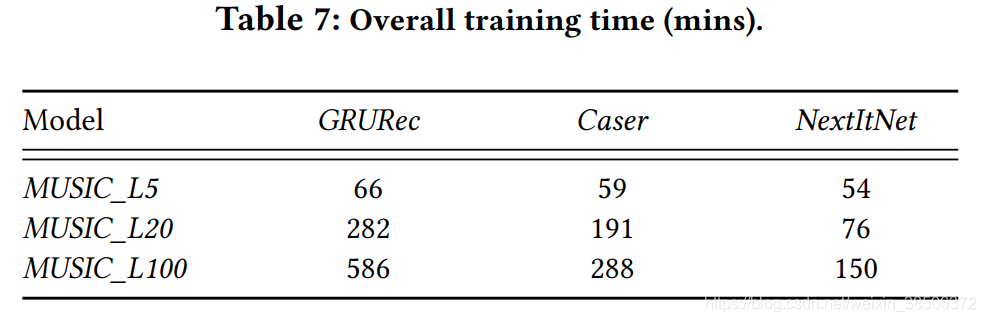
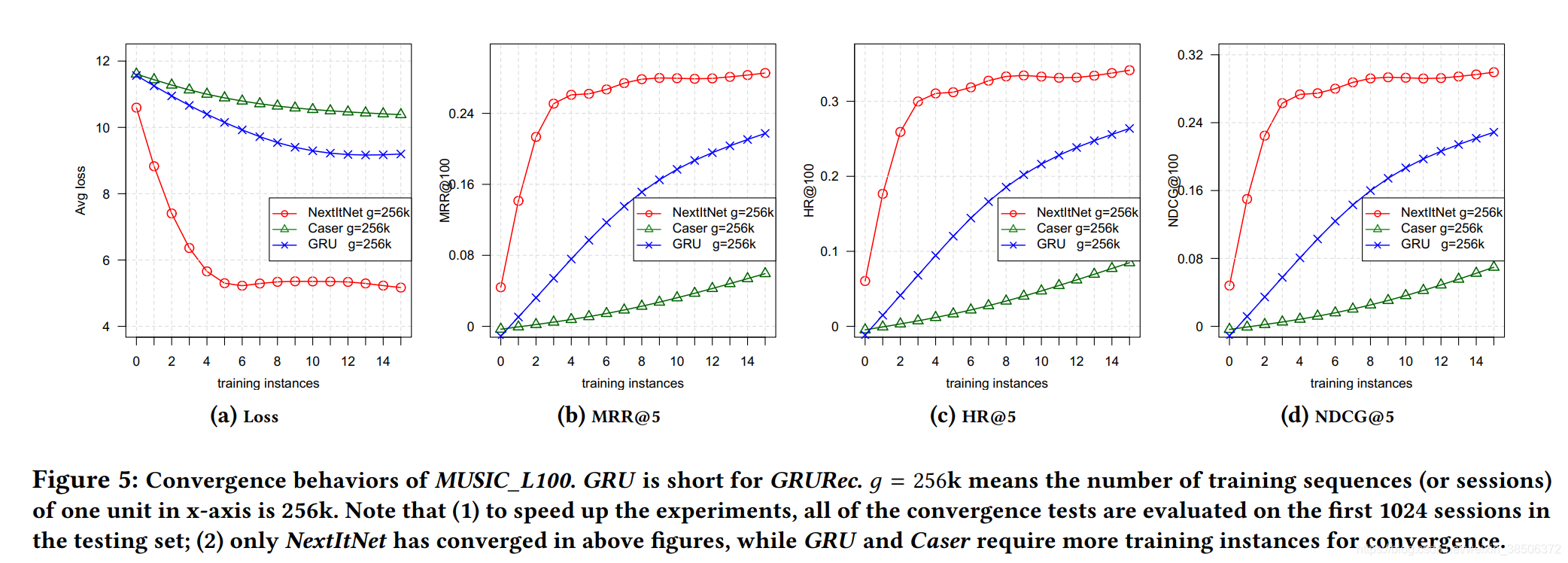
图5证明本文模型的收敛速度快于另两个模型
Future work
将考虑引入上下文信息和用户信息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









