









OpenCL内存性能优化 (1)
7 OpenCL内存性能优化
内存优化是最重要和有效的OpenCL性能技术。 大量应用程序是受内存限制的,而不是受计算限制的。 因此,掌握内存优化对于OpenCL优化至关重要。 在本章中,将回顾OpenCL内存模型,然后介绍最佳实践。
7.1 Adreno GPU中的OpenCL内存
OpenCL定义了四种类型的内存,即全局,本地,常量和私有内存,因此了解它们之间的区别至关重要。 图7-1说明了这四种类型的存储器的概念布局。
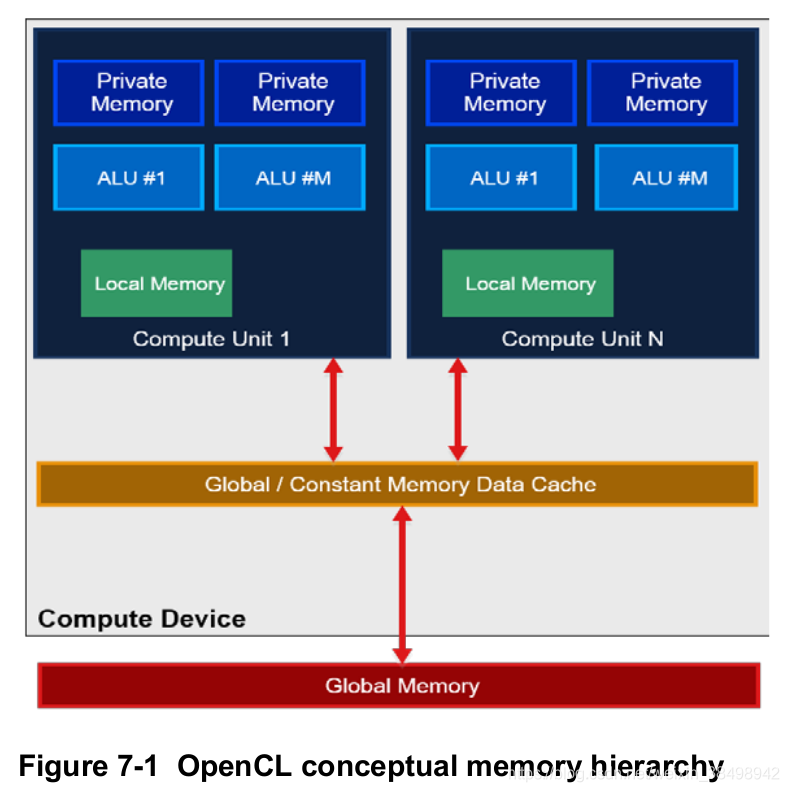
OpenCL标准仅在概念上定义了这些内存类型,并且如何实现这些是特定于供应商的。 物理位置可能与其概念位置不同。 例如,可以在远离GPU的片外系统RAM中分配私有存储对象。
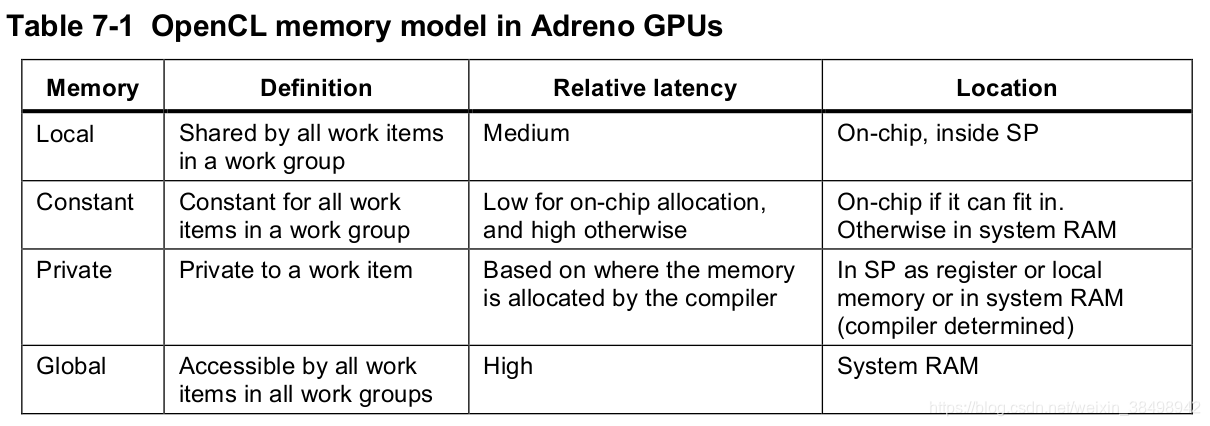
表7-1列出了四种内存类型的定义,以及它们在Adreno GPU中的延迟和物理位置。 在Adreno GPU中,片上RAM支持本地和恒定内存,并且延迟时间比片外系统RAM短得多。
通常,建议对需要频繁访问的数据使用本地和恒定内存,以利用短等待时间属性。 以下各节介绍了更多详细信息。
7.1.1 本地内存
Adreno GPU支持快速的片上本地内存,而本地内存的大小因系列/层而异。 在使用本地内存之前,优良作法是使用以下API查询设备每个工作组有多少本地内存可用:
clGetDeviceInfo(deviceID, CL_DEVICE_LOCAL_MEM_SIZE, .. )
这是使用本地内存的准则。
- 使用本地内存来存储重复使用的数据,或存储内核中两个阶段之间的中间结果。
- 理想的情况是工作项多次访问同一内容,并且访问两次以上
-例如,考虑针对某些视频处理使用对象匹配的基于窗口的运动估计。 假设每个工作项在16x16像素的搜索窗口内处理一个8x8像素的小区域,导致相邻工作项之间有大量数据重叠。 在这种情况下,本地存储器可能非常适合存储像素,以减少冗余获取。
- 用于跨工作项进行数据同步的屏障可能很昂贵
- 如果工作项之间存在数据交换,例如,工作项A将数据写入本地内存,而工作项B从中读取数据,则由于OpenCL中存在宽松的内存一致性模型,因此需要进行屏障操作。
- 屏障通常会导致同步延迟,从而使ALU停滞不前,从而导致ALU利用率降低。
- 在某些情况下,将数据缓存到本地内存会导致同步延迟,从而浪费使用本地内存的好处。 在这种情况下,直接使用全局内存(以避免障碍)可能是一个更好的选择。
- 使用向量化本地内存加载/存储
- 建议使用32位对齐的最多128位的矢量化负载(例如vload4_float)。
- 向量化的数据加载/存储在第7.2.2节中有更详细的讨论。
- 允许每个工作项参与本地内存数据加载,而不是使用一个工作项来完成整个加载
- 避免只有一个工作项来加载/存储工作组的整个本地内存。
- 避免使用名为async_work_group_copy的函数。 编译器通常很难生成最佳代码来加载本地内存,而开发人员则很难编写手动将数据加载到本地内存中的代码。
7.1.2 恒定内存
Adreno GPU支持片上恒定内存。 在四种类型的内存中,它具有最佳的延迟和出色的性能。 在以下情况下通常使用常量内存:
- 用常量限定符定义的标量和矢量变量通常存储在常量RAM中。
- 如果在程序范围内定义了由常量限定符定义的数组,则该数组将存储在常量RAM中(例如,编译器可以确定其大小),并且常量RAM有足够的空间。
- 内核参数的标量或矢量数据类型存储在常量RAM中。 例如,以下示例中的coeff将存储在常量RAM中:
__kernel void myFastKernel(__global float* bar, float8 coeffs)
{
//coeffs will be mapped to constant RAM
}
- 由__constant限定但不适合常量RAM的标量和矢量变量以及数组将分配到系统RAM中。
- 要将内核参数中定义的数组加载到常量RAM中,必须提供一个名为max_constant_size(N)的属性以指示常量数组的大小,其中N表示所需的字节数。 在下面的示例中,在常量RAM中为变量foo分配了1024个字节:
__kernel void myFastKernel(
__constant float foo* __attribute__( (max_constant_size(1024)))
{
. . .
}
指定max_constant_size属性很重要。 如果没有此属性,则阵列将存储在片外系统RAM中,因为编译器不知道阵列的大小,因此无法将其提升为片上RAM。
注意:
仅16位和32位阵列支持此功能。 不支持8位数组。 同样,如果常量存储器中没有足够的空间来分配阵列,则将其存储在片外系统RAM中。
对于动态索引并由工作项分开访问的数组,恒定RAM可能不是最佳选择。 例如,如果一个工作项获取索引0,而下一个工作项获取索引20,则恒定内存效率低下。 在这种情况下,使用图像对象是更好的选择。
7.1.3 专用内存
在OpenCL中,专用内存是每个工作项专用的,并且工作组中的其他工作项无法访问。 从物理上讲,私有存储器可以驻留在片上寄存器或片外系统RAM中。 确切位置取决于几个因素,以下是一些典型情况:
-
标量变量存储在寄存器中,这是最快的内存。
如果没有足够的寄存器,则将在系统RAM中分配专用变量。 -
私有数组可以存储在:
本地内存,尽管不能保证
片外系统RAM(如果超出本地存储容量)
将专用内存存储到片外系统RAM中是非常不希望的,因为系统RAM速度较慢且专用内存访问模式对缓存不友好,尤其是在每个工作项的专用内存量较大的情况下。 以下是一些建议:
- 避免在内核中定义任何私有数组。 如果可能,请尝试使用向量。
- 用全局或局部阵列替换专用阵列并设计其布局,以便可以跨多个工作项合并对阵列元素的访问。 缓存性能可能会好很多。
- 使用向量化的私有内存加载/存储,即,尝试每个事务加载/存储最多128位。

















 2423
2423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









