







 本文介绍了Yolo3目标检测算法的核心思想,重点解析了darknet53特征提取网络的结构,包括残差网络、DarknetConv2D结构,以及在网络中如何应用L2正则化、BatchNormalization和LeakyReLU。此外,详细阐述了Yolo3网络的输出预测结果的计算方式,解释了255维度的由来。最后,提到了针对不同数据集,如COCO和VOC,预测结果维度的差异,并推荐了一个深入讲解编码解码过程的博客链接。
本文介绍了Yolo3目标检测算法的核心思想,重点解析了darknet53特征提取网络的结构,包括残差网络、DarknetConv2D结构,以及在网络中如何应用L2正则化、BatchNormalization和LeakyReLU。此外,详细阐述了Yolo3网络的输出预测结果的计算方式,解释了255维度的由来。最后,提到了针对不同数据集,如COCO和VOC,预测结果维度的差异,并推荐了一个深入讲解编码解码过程的博客链接。
yolo系列目标检测算法的核心思想就是:把一张图片分为n*n网格,每个网格负责以该网格中心的区域的检测。
Yolo3使用的特征提取网络使用的是darknet53,它相较于其他yolo系列的检测算法主要改进有:
1、主干网络修改为darknet53,其重要特点是使用了残差网络Residual,darknet53中的残差卷积就是进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。
2、darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行L2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。
这里以输入图片尺寸416x416x3、coco数据集分类数80为例来详细看一看Yolo3的整体网络结构图:
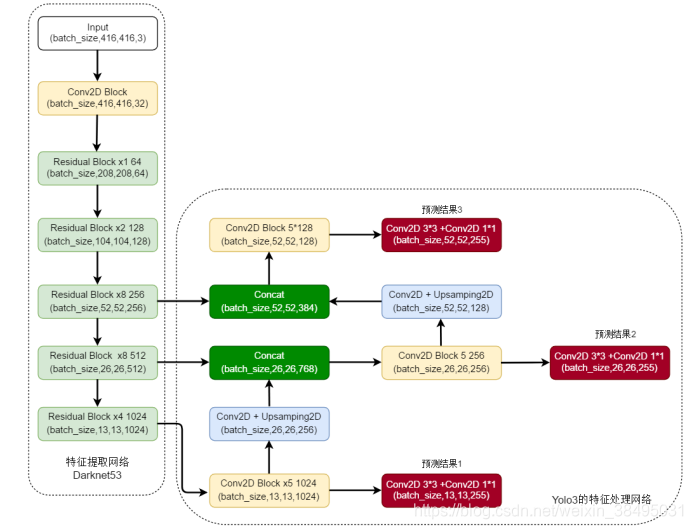
1.一个图片经过darknet53特征提取网络会依次得到6个特征层,
其大小分别是:
(416,416,32) (208,208,64) (104,104,128)
(52,52,256)(26,26,512)(13,13,1024),
2.后三个特征层再进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。(至于为什么要5次卷积我也不清楚)
3.经过一系列的卷积得到三个预测结果,其大小分别为:(52,52,255),(26,26,255),(13,13,255)
为什么是255呢? 这里是个需要好好理解的地方。
255 = 3*( 80 + 1 + 4 )
3表示的是:每一个网格所拥有的先验框的个数为3个(yolo3中默认设置的)
80代表的是:cooc数据集里面一共有80给类
1代表的是:每一个先验框所包含某个物体的置信度
4代表的是:预测框相对于每个网格中心点x轴偏移情况x_offset,预测框相对于每个网格中心点y轴偏移情况 y_offset, 先验框的height, 先验框的width。(每个网格点的中心加上x_offset和y_offset就可以得到预测框的中心,通过调整先验框的w和h就可以得到预测框的w和h,这样就可以确定预测框的位置啦)
PS:如果是voc数据集的话,最后的预测结果应该就是:(52,52,25)
(26,26,26)(13,13,25)。因为是20+1+4
以上就是yolo3特征提取+处理网络的输入和输出全部内容。
代码实现:
from functools import wraps
from keras.regularizers import l2
from keras.layers import Conv2D, BatchNormalization, Activation, ZeroPadding2D, Add, Input, UpSampling2D, Concatenate
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Model
from functools import reduce
#重新定义darknet中的Conv2D卷积操作
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {
'kernel_regularizer':l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2, 2) else 'same'
darknet_conv_kwargs.update 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









