







 本文详细介绍了基于深度学习的目标检测技术,包括R-CNN、Fast R-CNN和Faster R-CNN。R-CNN通过选择性搜索获取候选框并使用CNN特征,SVM分类及回归器进行物体检测。Fast R-CNN引入SPP Net减少重复计算,但仍依赖选择性搜索。Faster R-CNN提出RPN网络,有效替代选择性搜索,显著提升检测速度。
本文详细介绍了基于深度学习的目标检测技术,包括R-CNN、Fast R-CNN和Faster R-CNN。R-CNN通过选择性搜索获取候选框并使用CNN特征,SVM分类及回归器进行物体检测。Fast R-CNN引入SPP Net减少重复计算,但仍依赖选择性搜索。Faster R-CNN提出RPN网络,有效替代选择性搜索,显著提升检测速度。
目标检测:在给定的图片中精确找到物体所在位置,并标注出物体的类别。
目标检测=图像识别(CNN)+定位(回归问题/取图像窗口)
遇到多物体识别+定位多个物体?
用选择性搜索找出可能含有物体的框(候选框)判定得分。这些框之间是可以互相重叠互相包含的,从而避免暴力枚举的所有框了。
1.R-CNN
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
步骤二:对该模型做fine-tuning
- 修改分类数
- 去掉最后一个全连接层
步骤三:特征提取
- 提取图像的所有候选框(选择性搜索)
- 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
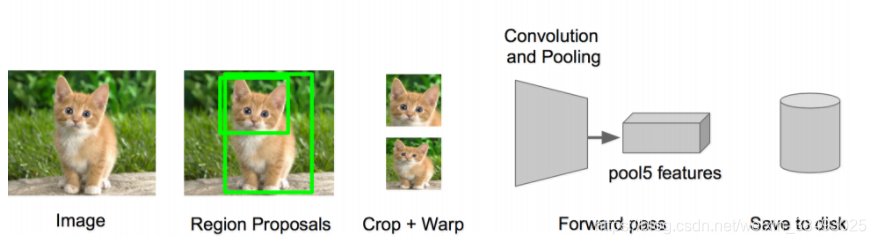
步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
- 每个类别对应一个SVM,判断是不是属于这个类别,是就是正类,反之负类
步骤五:训练一个回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。

速度瓶颈
计算机对所有候选框进行特征提取时会有重复计算。
2.Fast R-CNN
在RCNN的基础上采纳了SPP Net方法(空间金字塔池化)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









