







目录
8. limit 1000000加载很慢的话,你是怎么解决的呢?
14、SQL优化的一般步骤是什么,怎么看执行计划(explain),如何理解其中各个字段的含义。
15、select for update有什么含义,会锁表还是锁行还是其他。
22. 数据库中间件了解过吗,sharding jdbc,mycat?
29. 一条sql执行过长的时间,你如何优化,从哪些方面入手?
34. Hash索引和B+树区别是什么?你在设计索引是怎么抉择的?
40. Mysql的binlog有几种录入格式?分别有什么区别?
48. B树和B+树的区别,数据库为什么使用B+树而不是B树?
50. B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据?
56. 按照锁的粒度分,数据库锁有哪些呢?锁机制与InnoDB锁算法
63. count(1)、count(*) 与 count(列名) 的区别?
72. mysql中int(20)和char(20)以及varchar(20)的区别
78. 关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
82. 如果要存储用户的密码散列,应该使用什么字段进行存储?
89. MySQL中DATETIME和TIMESTAMP的区别
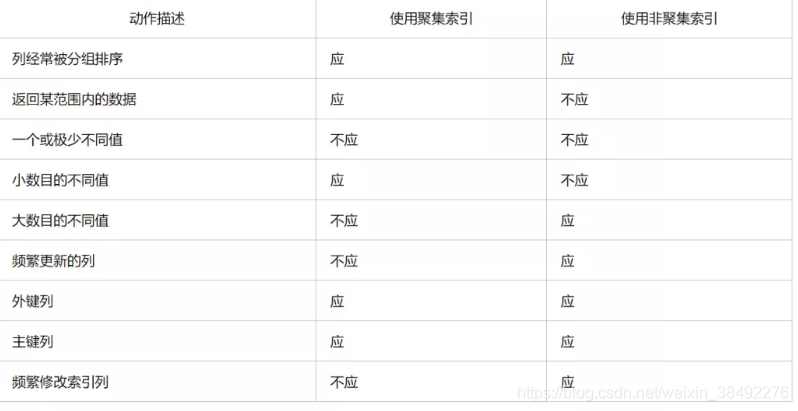
1. MySQL索引使用有哪些注意事项呢?
可以从三个维度回答这个问题:索引哪些情况会失效,索引不适合哪些场景,索引规则
索引哪些情况会失效
-
查询条件包含or,可能导致索引失效
-
如何字段类型是字符串,where时一定用引号括起来,否则索引失效
-
like通配符可能导致索引失效。
-
联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
-
在索引列上使用mysql的内置函数,索引失效。
-
对索引列运算(如,+、-、*、/),索引失效。
-
索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
-
索引字段上使用is null, is not null,可能导致索引失效。
-
左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
-
mysql估计使用全表扫描要比使用索引快,则不使用索引。
索引不适合哪些场景
- 数据量少的不合适加索引
- 更新比较频繁的也不合适加索引
- 区分度低字段不合适索引(如性别)
索引的一些潜规则
- 覆盖索引
- 回表
- 索引数据结构(B+树)
- 最左前缀原则
- 索引下推
2、MySQL遇到过死锁问题吗,你是如何解决的?
排查的步骤一般为:
- 查看死锁日志 show engine innodb status;
- 找出死锁的sql
- 分析sql加锁情况
- 模拟死锁案发
- 分析死锁日志
- 分析死锁结果
看两篇文章:
Mysql死锁如何排查:insert on duplicate死锁一次排查分析过程
3、日常工作中是如何优化sql的?
可以从这几个维度回答这几个问题:
- 加索引
- 避免返回不必要的数据
- 适当分批量进行
- 优化sql结构
- 分库分表
- 读写分离
可以看我这篇文章哈:后端程序员必备:书写高质量SQL的30条建议
4、说说分库与分表的设计
分库分表方案,分库分表中间件,分库分表可能遇到的问题
分库分表方案:
-
水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
-
水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
-
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
-
垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
常用的分库分表中间件:
-
sharding-jdbc(当当)Mycat
-
TDDL(淘宝)
-
Oceanus(58同城数据库中间件)
-
vitess(谷歌开发的数据库中间件)
-
Atlas(Qihoo 360)
分库分表可能遇到的问题
- 事务问题:需要用分布式事务
- 跨节点Join的问题:解决这一问题可以分两次查询实现
- 跨节点的count,order by,group by 以及聚合函数问题;分别在各个节点上得到结果后在应用程序端进行合并。
- 数据迁移,容量规划,扩容等问题
- ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制了,最简单可以考虑UUID
- 跨分页的排序分页问题(后台加大pagesize处理?)
5、Innodb与MyISAM的区别
- Innodb支持事务,MyISAM不支持事务
- Innodb支持外键,MyISAM不支持外键
- Innodb支持mvcc(多版本并发控制),MyISAM不支持
- select count(*) from table时,MyISAM更快,因为它有一个变量保存了整个表的总行数,可以直接读取,InnoDB就需要全表扫描。
- Innodb不支持全文索引,而MyISAM支持全文索引(5.7以后Innodb也支持全文索引)
- Innodb支持表、行级锁,而MyISAM只支持表级锁。
- Innodb必须有主键,而MyISAM可以没有主键。
- Innodb表需要更多的内存和存储,而MyISAM可被压缩,存储空间较小。
-
Innodb按主键大小有序插入,MyISAM记录插入顺序是,按记录插入顺序保存。
-
InnoDB 存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全,与 MyISAM 比 InnoDB 写的效率差一些,并且会占用更多的磁盘空间以保留数据和索引
6、数据库索引的原理,为什么要用B+,为什么不用二叉树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查询磁盘的次数,为什么不是二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是B+树呢?
为什么不是一般二叉树?
如果二叉树特殊为一个链表,相当于全表扫描。平衡二叉树相比于二叉树来说,查找效率更稳定,总体的查找速度也更快。
为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快的多。如果树这种数据结构作为索引,那我们每查找一次数据就要从磁盘读取一个节点,也就是我们说的磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,树的高度会降低,因此读取磁盘的次数就将降下来了,查询效率就快乐,
那为什么不是B树而是B+树呢?
1)B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
2)B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
可以看这篇文章哈:再有人问你为什么MySQL用B+树做索引,就把这篇文章发给她
7、聚集索引与非聚集索引的区别
-
一个表中只能拥有一个聚集索引,而非聚集索引一个表可以存在多个。
-
聚集索引,索引中键值的逻辑顺序决定了表中相应行的物理顺序;非聚集索引,索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
-
索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
-
聚集索引:物理存储按照索引排序;非聚集索引:物理存储不按照索引排序;
何时使用聚集索引或非聚集索引?
8. limit 1000000加载很慢的话,你是怎么解决的呢?
方案一:如果id是连续的,可以这样,返回上次查询的最大记录(偏移量),再往下limit
select id,name from employee where id > 1000000 limit 10.方案二:在业务允许的情况下限制页数:
建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。
方案三:order by + 索引(id为索引)
select id,name from employee order by id limit 1000000,10方案四:利用延迟关联或者子查询优化超多分页场景。(先快速定位需要获取的id段,然后再关联)
SELECT a.* FROM employee a, (select id from employee where 条件 LIMIT 1000000,10 ) b where a.id=b.id9、如何选择合适的分布式主键方案呢?
- 数据库自增长序列或字段。
- UUID
- Redis生成ID
- Twitter的snowflake算法
- 利用zookeeper生成唯一ID
- MongoDB的ObjectId
10、事务的隔离级别有哪些?mysql默认隔离级别是什么?
- 读未提交(Read Uncommitted)
- 读已提交(Read Committed)
- 可重复读(Repeatable Read)
- 串行化(Serializable)
MySQL默认的事务隔离级别为可重复读(Repeatable Read)。
可以看我这篇文章哈:一文彻底读懂MySQL事务的四大隔离级别
11、什么是幻读,脏读,不可重复读呢?
-
事务A、B交替执行,事务A被事务B干扰到了,因为事务A读取到事务B未提交的数据,这就是脏读
-
在一个事务范围内,两个相同的查询,读取同一条记录,却返回了不同的数据,这就是不可重复读。
-
事务A查询一个范围的结果集,另一个并发事务B往这个范围中插入/删除了数据,并静悄悄地提交,然后事务A再次查询相同的范围,两次读取得到的结果集不一样了,这就是幻读。
可以看我这篇文章哈:一文彻底读懂MySQL事务的四大隔离级别
12. 在高并发情况下,如何做到安全的修改同一行数据?
要安全的修改同一行数据,就要保证一个线程在修改时其它线程无法更新这行记录。一般有悲观锁和乐观锁两种方案~
使用悲观锁
悲观锁思想就是,当前线程要进来修改数据时,别的线程都得拒之门外~ 比如,可以使用select…for update ~
select * from User where name=‘jay’ for update以上这条sql语句会锁定了User表中所有符合检索条件(name=‘jay’)的记录。本次事务提交之前,别的线程我无法
修改这些数据。
使用乐观锁
乐观锁思想就是,有线程过来,先放过去修改,如果看到别的线程没修改过,就可以修改成功,如果别的线程修改过,就修改失败或者重试。实现方式,乐观锁一般会使用版本号机制或者CAS算法实现。
可以看一下我这篇文章,主要是思路哈~CAS乐观锁解决并发问题的一次实践
13、数据库的乐观锁和悲观锁。
悲观锁
悲观锁她专一且缺乏安全感,她的心只属于当前事务,每时每刻都担心这她心爱的数据可能被别的事务修改,所以一个事务拥有(获得)悲观锁,其他任何事务都不能对数据进行修改啦,只能等待锁被释放才可以执行。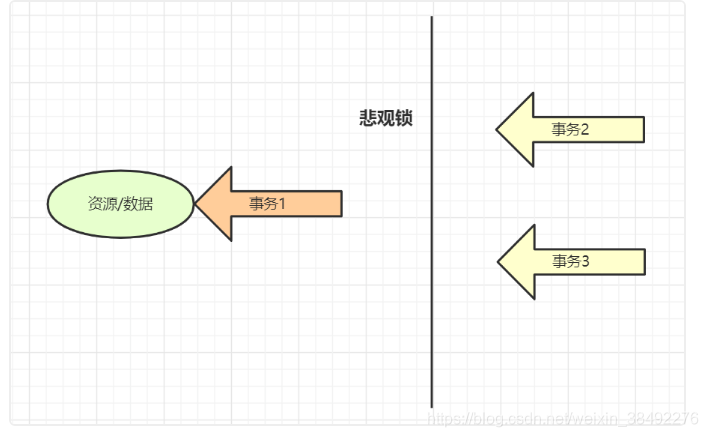
乐观锁
乐观锁的“乐观情绪”体现在,它认为数据的变动不会太频繁。因此,它允许多个事务同时对数据进行变动。实现方式:乐观锁一般会使用版本号机制或者CAS算法实现。
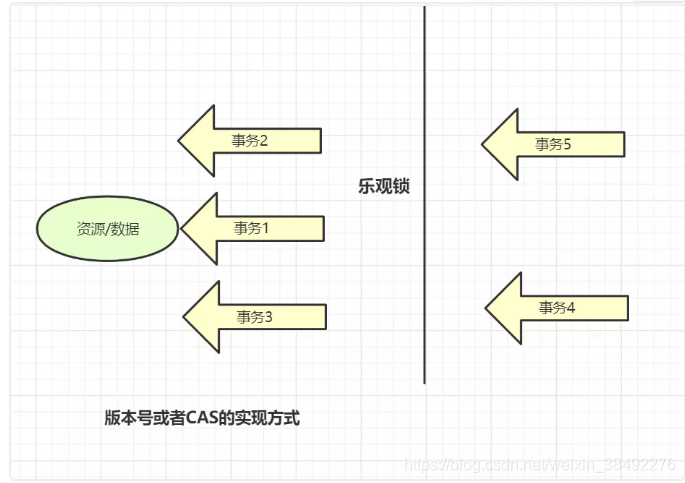
之前转载了的这篇文章,觉得作者写得挺详细的~
14、SQL优化的一般步骤是什么,怎么看执行计划(explain),如何理解其中各个字段的含义。
- show status 命令了解各种sql的执行效率
- 通过慢查询日志定位那些执行效率较低的sql语句
- explain分析低效sql的执行计划(这点非常重要,日常开发中用它分析sql,会大大降低sql导致的线上事故)
15、select for update有什么含义,会锁表还是锁行还是其他。
select for update 含义
select查询语句是不会加锁的,但是select for update除了有查询的作用外,还会加锁呢,而且它是悲观锁哦。至于加了是行锁还是表锁,这就要看是不是用了索引/主键啦。
没用索引/主键的话就是表锁,否则就是是行锁。
select for update 加锁验证
表结构:
//id 为主键,name为唯一索引
CREATE TABLE 'account`
(`id` int(11)NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY ('id`),
KEY `idx_name`(`name`)
USING BTREE
)ENGINE=InnoDB AUTO_INCREMENT = 1570068 DEFAULT CHARSET= utf8id为主键,select for update 1270070这条记录时,再开一个事务对该记录更新,发现更新阻塞啦,其实是加锁了。如下图:
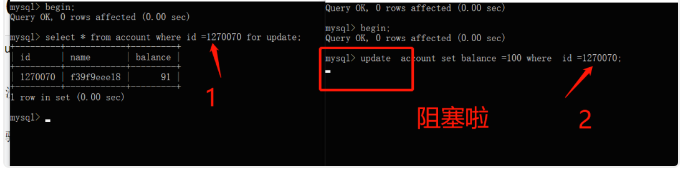
我们再开一个事务对另外一条记录1270071更新,发现更新成功,因此,如果查询条件用了索引/主键,会加行锁~
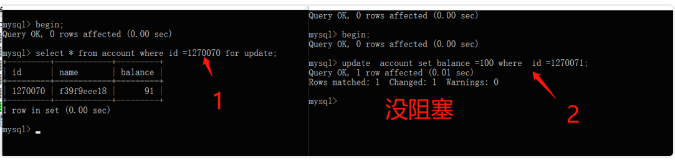
我们继续一路向北吧,换普通字段balance吧,发现又阻塞了。因此,没用索引/主键的话,select for update加的就是表锁

16、MysQL事务四大特性以及实现原理
- 原子性:事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性:指在事务开始之前和事务结束以后,数据不会被破坏,假如A账户给B账户转10块钱,不管是否成功与否,A与B的总金额是不变的。
- 隔离性:多个事务并发访问时,事务相互隔离开 。
- 一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
17、如果某个表有近千万条数据,CRUD比较慢,如何优化。
分库分表
某个表有近千万数据,可以考虑优化表结构,分表(水平分表,垂直分表),当然,你这样回答,需要准备好面试官问你的分库分表相关问题呀,如
- 分表方案(水平分表,垂直分表,切分规则hash等)
- 分库分表中间件(MyCat, sharding-jdbc等)
- 分库分表一些问题(事务问题?跨节点join的问题)
- 解决方案(分布式事务等)
索引优化
除了分库分表,优化表结构,当然还有索引优化等方案。
有兴趣可以看我这篇文章哈~后端程序员必备:书写高质量SQL的30条建议
18. 如何写sql能够有效的使用到复合索引。
复合索引,也叫组合索引,用户可以在多个列上建立索引,这种索引叫做复合索引。
当我们创建一个组合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
select * from table where k1 = A AND k2 = B AND k3 = D有关于复合索引,我们需要关注查询Sql条件的顺序,确保最左匹配原则有效,同时可以删除不必要的冗余索引。
19. mysql中in 和exists的区别。
这个,跟一下demo来看更刺激吧,啊哈哈
假设表A表示某企业的员工表,表B表示部门表,查询所有部门的所有员工,很容易有以下SQL:
select * from A where deptId in
(
select deptId from B
);这样写等价于:
先查询部门表B
select deptId from B
再由部门deptId,查询A的员工
select * from A where A.deptId = B.deptId可以抽象成这样的一个循环:
List<> resultSet;
for (int i=0;i<B.length;i++){
for(int j=0;j<B.length;j++){
if (A[i].id=B[j].id){
resultSet.add(A[i]);
break;
}
}
}显然,除了使用in,我们也可以使用exists实现一样的查询功能,如下 :
select * from A where exists (
select 1 from B where A.deptId =B.deptId);
数据库最费劲的就是跟程序链接释放。假设链接了两次,每次做上百万次的数据集查询,查完就走,这样就只做了两次;相反建立了上百万次链接,申请链接释放反复重复,这样系统就受不了了。即mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优。
因此,我们要选择最外层循环小的,也就是,如果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5569
5569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











