






 本文介绍了MybatisPlus中的QueryWrapper在Java实体类和Mapper接口中的应用,涵盖了创建实体类、编写mapper接口、查询条件构建(包括等值、模糊和范围查询),以及如何使用UpdateWrapper进行更新和DeleteWrapper进行删除操作。重点讨论了不同主键策略的选择及其优缺点。
本文介绍了MybatisPlus中的QueryWrapper在Java实体类和Mapper接口中的应用,涵盖了创建实体类、编写mapper接口、查询条件构建(包括等值、模糊和范围查询),以及如何使用UpdateWrapper进行更新和DeleteWrapper进行删除操作。重点讨论了不同主键策略的选择及其优缺点。
一、queryWrapper介绍
queryWrapper是mybatis plus中实现查询的对象封装操作类,可以封装sql对象,包括where条件,order by排序,select哪些字段等等,他的层级关系如下:
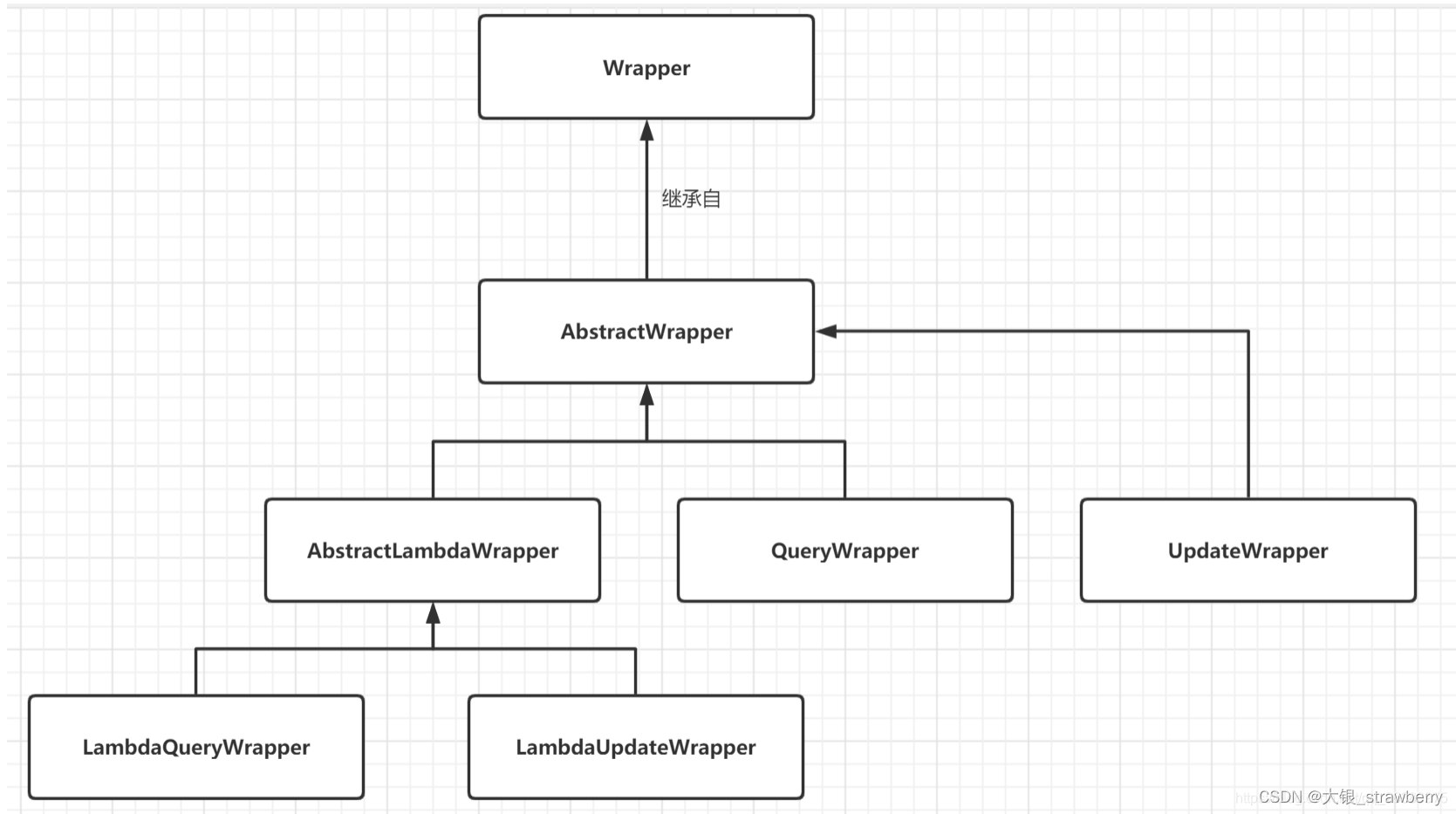
Wrapper:条件构造抽象类,最顶端父类;
AbstractWrapper:用于查询条件封装,生成sql的where条件;
AbstractLambdaWrapper:Lambda语法使用Wrapper统一处理解析lambda获取column。
LambdaQueryWrapper:用于lambda语法使用的查询Wrapper;
LambdaUpdateWrapper:Lambda更新封装Wrapper;
QueryWrapper:Entity对象封装操作类,不是用lambda;
UpdateWrapper:Update条件封装,用于Entity对象更新操作。
参考链接~~
1.1 创建实体类
@Data
@TableName("task_operate_info")
public class TaskOperateInfo extends BaseEntity
{
private static final long serialVersionUID = 1L;
/** 主键 */
@TableId(value="id", type = IdType.AUTO)
@TableField("operate_Id")
private Integer operateId;
/** 任务ID */
@TableField("task_Id")
private Long taskId;
/** 设备ID列表 */
@Excel(name = "设备ID列表")
private String deviceIdList;
/** 操作类型 */
@Excel(name = "操作类型")
private String operateType;
/** 开始时间 */
@Excel(name = "开始时间")
private String startTime;
/** 结束时间 */
@Excel(name = "结束时间")
private String endTime;
/** 创建者 */
@Excel(name = "创建者")
private String creator;
/** 部门ID */
@Excel(name = "部门ID")
private Long deptId;
/** 用户ID */
@Excel(name = "用户ID")
private Long userId;
1.2 编写一个mapper接口,只需继承BaseMapper,基本的单表查询都给你封装好了
@Mapper
public interface TaskOperateInfoMapper extends BaseMapper<TaskOperateInfo>{
}
1.3 启动类加载
@SpringBootApplication
@MapperScan("com.wen.mybatis_plus.mapper") //扫描mapper
//@MapperScan("com.ruoyi.**.mapper")
public class MybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlusApplication.class, args);
}
}
注意:
要在主启动类上去扫描mapper包下的所有接口:@MapperScan(“com.wen.mybatis_plus.mapper”)
1.3 queryWrapper
/**
* 查询
*/
@Test
public void findCondition2() {
TaskOperateInfo customer = new TaskOperateInfo();
customer.setCreator("777");
customer.setOperateType("888");
//条件查询
QueryWrapper<TaskOperateInfo> queryWrapper = new QueryWrapper<>();
// 1) 等值查询
queryWrapper.eq( customer.getCreator()!=null ,"password", customer.getCreator());
// 2) 模糊查询
queryWrapper.notLike(customer.getOperateType() != null , "cname",customer.getOperateType());
// 4) 大于等于
queryWrapper.ge(customer.getUpdateTime() != null , "cid" , customer.getUpdateTime());
//查询
List<TaskOperateInfo> list = taskOperateInfoMapper.selectList(queryWrapper);
//list.forEach(customer-> System.out.println(customer));
list.forEach(System.out::println);
}
/**
* 更新
*/
@Test
public void testUpdateByQueryMapper(){
//1.todo 更新数据
TaskOperateInfo customer = new TaskOperateInfo();
customer.setTaskId(1l);
//2.todo 更新条件
UpdateWrapper<TaskOperateInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.in("cid",1,2,3);
//3.todo 更新
int update = taskOperateInfoMapper.update(customer, updateWrapper);
System.out.println(update);
}
/**
* 删除
*/
@Test
public void deleteById(Long id) {
QueryWrapper<TaskOperateInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("id", id);
taskOperateInfoMapper.delete(queryWrapper);
}
二、注解
2.1 @TableName 表名注解
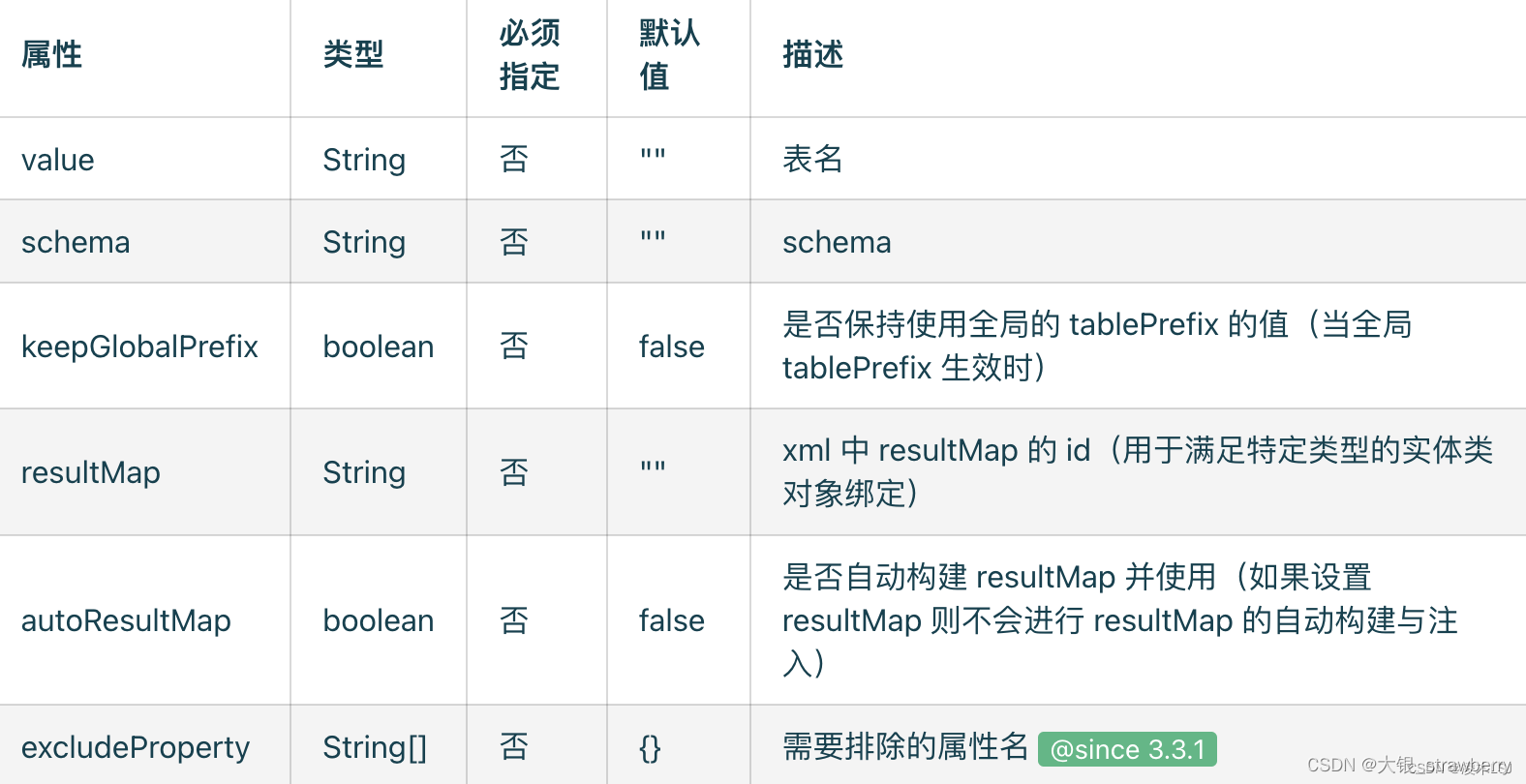
2.2 @TableId主键注解
@TableName("sh_user")
public class shUser {
@TableId
private String uid;
private String username;
private String password;
private String rid;
private String createtime;
private String updatetime;
}

2.3 IdType参数(主键自动生成策略)
点击 IdType查看源码看有哪些自动生成方法

/**
* 生成ID类型枚举类
*
* @author hubin
* @since 2015-11-10
*/
@Getter
public enum IdType {
/**
* 数据库ID自增
* <p>该类型请确保数据库设置了 ID自增 否则无效</p>
*/
AUTO(0),
/**
* 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
*/
NONE(1),
/**
* 用户输入ID
* <p>该类型可以通过自己注册自动填充插件进行填充</p>
*/
INPUT(2),
/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 分配ID (主键类型为number或string),
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法)
*
* @since 3.3.0
*/
ASSIGN_ID(3),
/**
* 分配UUID (主键类型为 string)
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-",""))
*/
ASSIGN_UUID(4);
private final int key;
IdType(int key) {
this.key = key;
}
}
● NONE: 不设置id生成策略,MP不自动生成。约等于INPUT,所以这两种方式都需要用户手动设置,但是手动设置第一个问题是容易出现相同的ID造成主键冲突,为了保证主键不冲突就需要做很多判定,实现起来比较复杂
● AUTO:数据库ID自增。这种策略适合在数据库服务器只有1台的情况下使用,不可作为分布式ID使用。<------主键最好不要直接暴露数据的数量,这样容易被外界知道关键信息------>
● ASSIGN_UUID:可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是32位的字符串,长度过长占用空间而且还不能排序,查询性能也慢。UUID对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
● ASSIGN_ID:可以在分布式的情况下使用,生成的是Long类型的数字,可以排序性能也高,但是生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键
综上所述,每一种主键策略都有自己的优缺点,根据自己项目业务的实际情况来选择使用才是最明智的选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









