







 本文介绍了数据库设计中的三范式(1NF、2NF、3NF)概念,强调了范式在减少数据冗余和优化查询效率中的作用。1NF要求字段具有原子性,2NF消除部分依赖,3NF则解决传递依赖问题。同时,文章还详细解释了一对一、一对多/多对一以及多对多的表关系,并提供了实例说明如何设计这些关系以提高数据库效率。
本文介绍了数据库设计中的三范式(1NF、2NF、3NF)概念,强调了范式在减少数据冗余和优化查询效率中的作用。1NF要求字段具有原子性,2NF消除部分依赖,3NF则解决传递依赖问题。同时,文章还详细解释了一对一、一对多/多对一以及多对多的表关系,并提供了实例说明如何设计这些关系以提高数据库效率。
范式
范式normal format,为了解决数据存储与优化的问题,保存数据后,凡是能通过关系查找到的数据,不再重复存储,减少数据冗余。但是减少数据冗余就意味着效率的降低,实际数据库的设计中需要根据需求,而不是一味地按照范式设计。
范式是一种分层结构的规范,分为六层,每次都比上一层严格,满足下一层范式的前提是满足上一层范式。
六层范式:1NF,2NF,3NF,…,6NF。6NF为最高层,最严格。数据库的设计中只需要用到3NF,4NF以后已经不满足效率的需求,仅仅是为了解决空间问题。
3NF
1NF
一张表中的每一个字段都具有原子性,即每个字段的数据取出后不需要再拆分。
如:学习时间是一个字段,其中一条记录为(19:00-22:30)。当我需要查出开始学习的时间时,需要将该字段的数据拆分后取出。这样的字段就不具有原子性。
解决方案:将可进行数据拆分的字段拆分成多个不可再拆分的字段。
如:将学习时间这一个字段拆分成2个字段:开始学习时间(19:00),结束学习时间(22:30)。此时,这2个字段都不可再分,具有原子性。
2NF
一张表中如果存在复合主键,而表中有字段仅依赖于复合主键中某一部分,称为部分依赖。2NF解决的问题就是消除部分依赖。
如:学生姓名与班级构成了复合主键,性别只依赖于学生姓名,而不依赖于班级,这种就是部分依赖。
解决方法:取消复合主键,使用逻辑主键。
如:取消复合主键学生姓名和班级,使用逻辑主键id。此时,就消除了部分依赖。
3NF
一张表中有字段不直接依赖于主键,而是通过依赖于其他字段来间接依赖于主键,称为传递依赖。3NF解决的问题就是解决传递依赖。
如:在上述2NF的基础上,取消了复合主键学生姓名+班级,使用逻辑主键id,此时性别与id并没有直接的关系,而是性别依赖于学生姓名,学生姓名依赖于id,进而性别间接依赖于id,这种就是传递依赖。
解决方法:将存在传递依赖的字段从表中取出,单独成表。
如:将性别从表中取出,单独与学生名字建立一个表,以学生身份id作为主键,此时学生身份id就是这个学生,性别就直接依赖于身份id(与前面的id不同,前面的id代表的是姓名+班级,而且身份id也避免了重名导致混淆的情况),这样就消除了传递依赖。而原表中的姓名可用身份id替换,这样可以节省空间(id一般是数字,而存储数字比存储中文字符节省空间),但同样这就导致了效率降低(联合2个表查询明显慢于只查询1个表)。对于需要经常查询的表,效率比空间重要一些,因此原表中仍使用中文字符存储,称为逆规范化。
表关系
一对一
一张表中有且只有一条记录对应另一张表的唯一一条记录
如:

该表中包含了常用数据(性别、年龄)和不常用数据(籍贯,住址)。
为了提高数据库的效率,可以把这张表拆分成2张表,常用信息表和不常用信息表
常用表

不常用表

此时,这2张表都有共同的id(主键)各自确定1条信息,而这2条信息组成1条完整的信息。这种关系就是一对一关系。
一对多/多对一
一张表1中的一条记录对应另一张表2的多条记录,而表2中的一条记录只能对应表1中的唯一条记录。
如:一个班级(“一”)有多个学生(“多”),而一个学生只有一个班级。
一般设计时,通过“多”关系表来维护一个字段,而这个字段是“一”关系表的主键。
如:建立一张学生表,表中有一个字段存储每个学生的所属班级。另外建立一张班级表,保存所有的班级(一个班级为一条记录,主键),但是不保存各班的学生信息。这样通过学生表(“多”关系表)来维护学生表与班级表之间的关系。
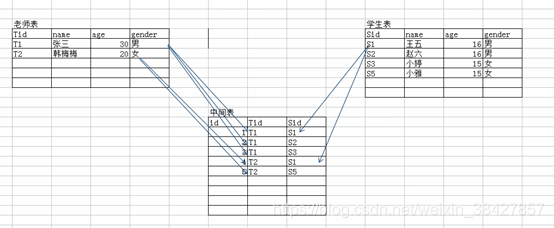
多对多
一张表1中的一条记录对应另一张表2中的多条记录,而表2中的一条记录也对应表1中的多条记录。
如:一个学生有多个老师,而一个老师也有多个学生。
处理方案:增加一个中间表,来记录2张表之间的所有关系,这样表1与中间表就形成了一对多关系,表2也与中间表形成了一对多关系。这样就可以通过中间表方便地查询出2个表数据的关系。
如:

















 5509
5509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









