







 本文深入探讨了数据结构和算法的基础知识,强调了数据结构在计算机科学中的核心地位,详细解析了算法复杂度分析,包括时间复杂度和空间复杂度,并介绍了Java标准库中的关键数据操作工具。
本文深入探讨了数据结构和算法的基础知识,强调了数据结构在计算机科学中的核心地位,详细解析了算法复杂度分析,包括时间复杂度和空间复杂度,并介绍了Java标准库中的关键数据操作工具。
第一章 引言及算法分析
数据结构和算法解决的问题:
1、数据的有效存储数据
2、排序问题
3、查找问题
一、为什么要学习数据结构
1、数据结构是所有计算机专业的同学必学的课程
2、数据结构研究的是如何在计算机中组织和存储,使得我们可以更好的获取数据和修改数据
3、数据结构的家族,三种结构:

4、数据结构的应用:
我们常用的数据库、操作系统快速多任务切换、文件压缩、通讯录_trie前缀树、所有的算法等
5、数据结构是算法的基石
数据结构+算法=程序
6、接下来我们要了解的数据结构

二、算法复杂度分析
1、到底什么是大O
n表示数据规模
O(f(n))表示运行算法所需要执行的指令数,和f(n)成正比。
比如:寻找数组中的最大值/最小值O(n) ,所需执行的指令数b*n .b是一个常数,也就是说指令数的增长和b没有多大的关系,和N的关系巨大。
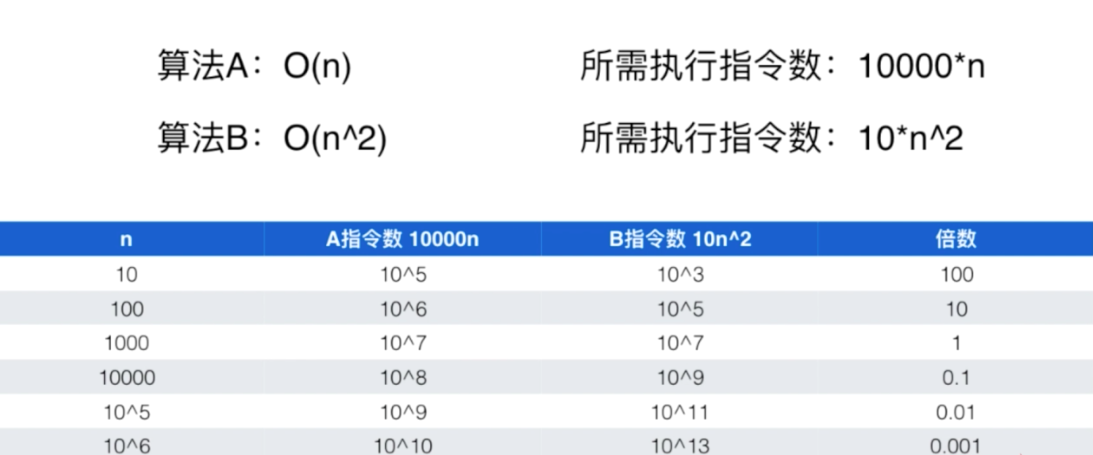
这个对比就是数量级上的差距。也可以看出,当数据规模小到一定程度的时候,O(n2)这样的算法是有意义的。
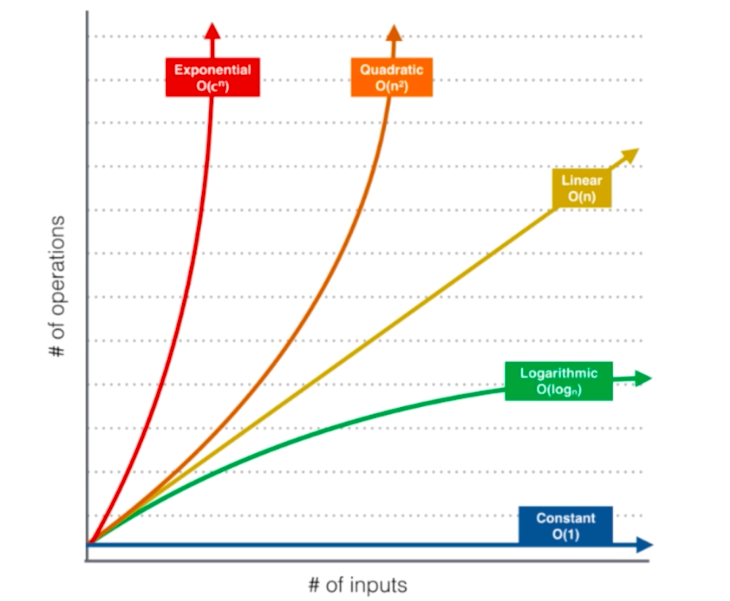
在业界,我们使用O来表示算法执行的最低上界。
如果我们设计了一个算法,整个算法将以那个量级最高的起到主引作用的一项为准 。
如果一个算法处理了两部分:
O(logN+N) = O(logN) 这个算法复杂度中,N这一项的作用是不显著的。


2、空间复杂度
也就是说我们开了多少个辅助空间
3、常见的算法分析
1) O(1)级别的算法(没有数据规模的变化)

2)O(n)级别的算法

最典型的就是有个循环,而且这个循环的执行效率是和N相关的。 随着N的增长,整个时间的消耗是线性的。

3) O(n^2)复杂度

如果里面有个双重循环,那么一般情况下是一个O(n^2)的复杂度。它所执行的指令数和n^2是一个常数的关系。

4)O(logN)复杂度

这是一个二分查找法。用递归也可以实现。这是实现的原理就是每一次查找如果没有得到结果的话都可以扔掉一半的元素继续进行查找。

不光是以2为底,以其实的数为底也一样。都是O(logN):
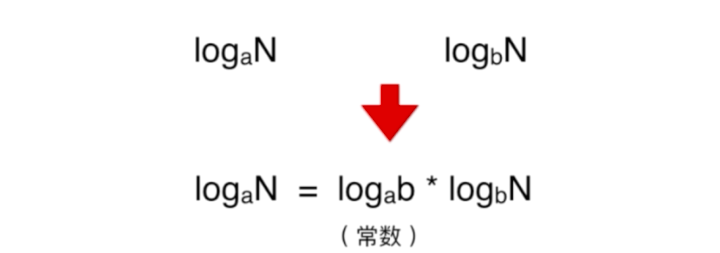
上面可以看出两个式子只是差了一个常数。而通常我们说常数是可以忽略的。
三、java标准库的结构
1、Arrays是对普通数组的操作工具集
Arrays类常用方法:
boolean equals(array1,array2):比较两个数组是否相等
void sort(array):对数组array元素进行升序排序
String toString(array):该方法将会一个数组array转换成一个字符串
void fill(array,val):把数组array所有元素都赋值为val
copyof(array,length):把数组array复制成一个长度为length的新数组
int binarySearch(array,val):查询元素值val在数组array中下标
https://blog.youkuaiyun.com/sun_smile1/article/details/76558272
2、collections工具类
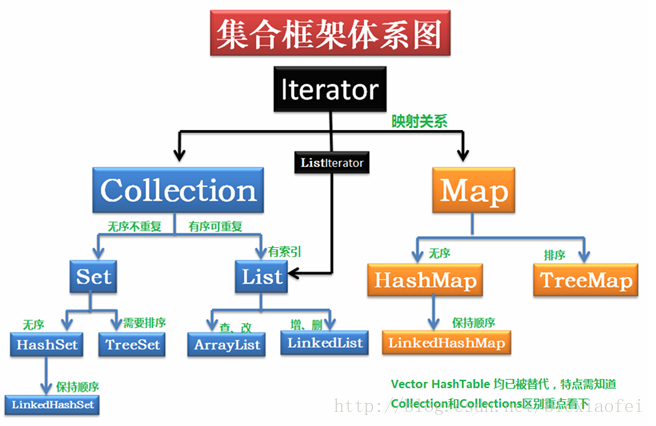
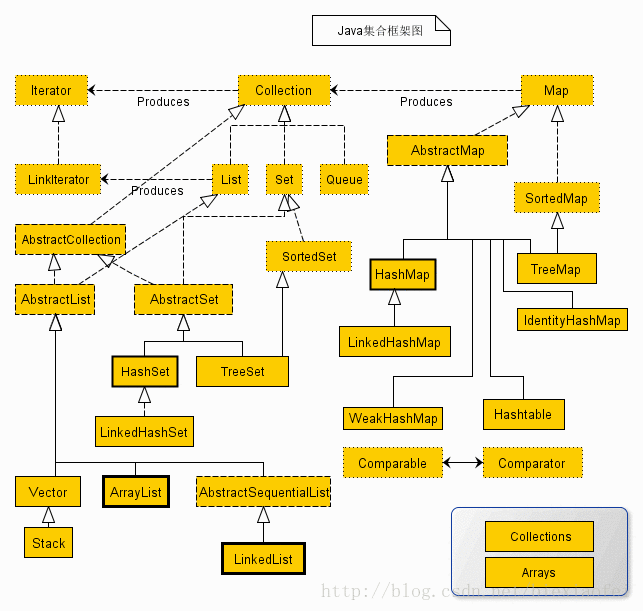
对List和set实现类的操作工具类:
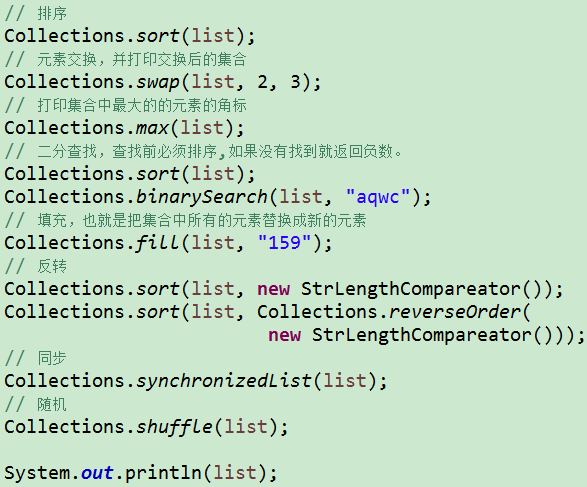
https://blog.youkuaiyun.com/ling912439122/article/details/52334086

















 2154
2154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









