






 博客分析了一个业务流程性能优化的问题,发现在XML拼接过程中,由于使用strncpy函数时参数设置不正确,导致了不必要的性能损耗。原本的代码在源字符串较短而目标地址空间较大的情况下,会清零额外的内存,这不仅增加了无意义的运算,还可能引发内存越界。通过对strncpy参数的调整,将拷贝长度限制为源字符串长度,流程总时长显著降低。文章通过实验验证了这个问题,并强调了遵循strncpy函数正确使用的必要性。
博客分析了一个业务流程性能优化的问题,发现在XML拼接过程中,由于使用strncpy函数时参数设置不正确,导致了不必要的性能损耗。原本的代码在源字符串较短而目标地址空间较大的情况下,会清零额外的内存,这不仅增加了无意义的运算,还可能引发内存越界。通过对strncpy参数的调整,将拷贝长度限制为源字符串长度,流程总时长显著降低。文章通过实验验证了这个问题,并强调了遵循strncpy函数正确使用的必要性。
总述
如果传给 strncpy 函数的拷贝长度限制 lenLimit(第三个参数)大于源字符串(第二个参数)的长度 lenSrc,则在将源字符串拷贝到目标地址空间之后,还会将目标地址空间中紧接着拷贝过去的源字符串的 lenLimit - lenSrc 长度的空间清零。可能造成越界(如果 lenLimit 超过目标地址空间的大小)和无意义的性能损耗。
背景
工作中需要对某一业务流程的性能进行优化,以满足产品规格要求。业务功能是将从数据库里查出的记录拼接成指定格式的 XML,再和 JPEG 图片数据打包,通过 TCP 传输到上层平台。主要步骤有:向数据库临时表插入一条记录、拼接 XML、获取图片数据、打包、通过 socket 接口发送。
要求从插入数据库临时表到调用完 send 接口,总时长不能超过 250 ms,最好在 125 ms 以内,但实际测试结果是总时长需要 290 ~ 300 ms。
分析
理论上,涉及磁盘 IO 的插入数据库临时表和获取图片数据应该耗时最多,但是,通过计算各个步骤的耗时,发现只涉及内存操作的 XML 拼接部分占用了 80% ~ 90% 的时间。进一步细化,发现 XML 拼接部分有两个函数耗时特别长,都要 100 多毫秒。
这两个耗时特别大的函数里有很多字符串拷贝的操作,源字符串比较短,也就几十个字符,但是目标地址空间很大,有接近 10 MB 的大小(在代码实现上,为了减少内存拷贝次数,拼接 XML 时直接在最终的要发送的缓存空间上进行操作,因为要包含图片数据,给缓存申请了 10 MB 的内存)。
公司对 strncpy 做了宏定义封装,把目标地址空间的最后一个字符位赋成 '\0'。最开始猜测,是不是赋 '\0' 操作要找到内存的最后一个字符位,耗时比较多。但是把使用封装的宏定义改成直接使用 strncpy 后,耗时并没有缩短。
于是尝试把第三个参数由 目标地址空间的大小 换成 目标地址空间的大小和源字符串长度两者的较小值。修改后流程总时长缩小到 25 ~ 40 ms,原来耗时 100 多毫秒的两个 XML 拼接接口,耗时直接变为 0。
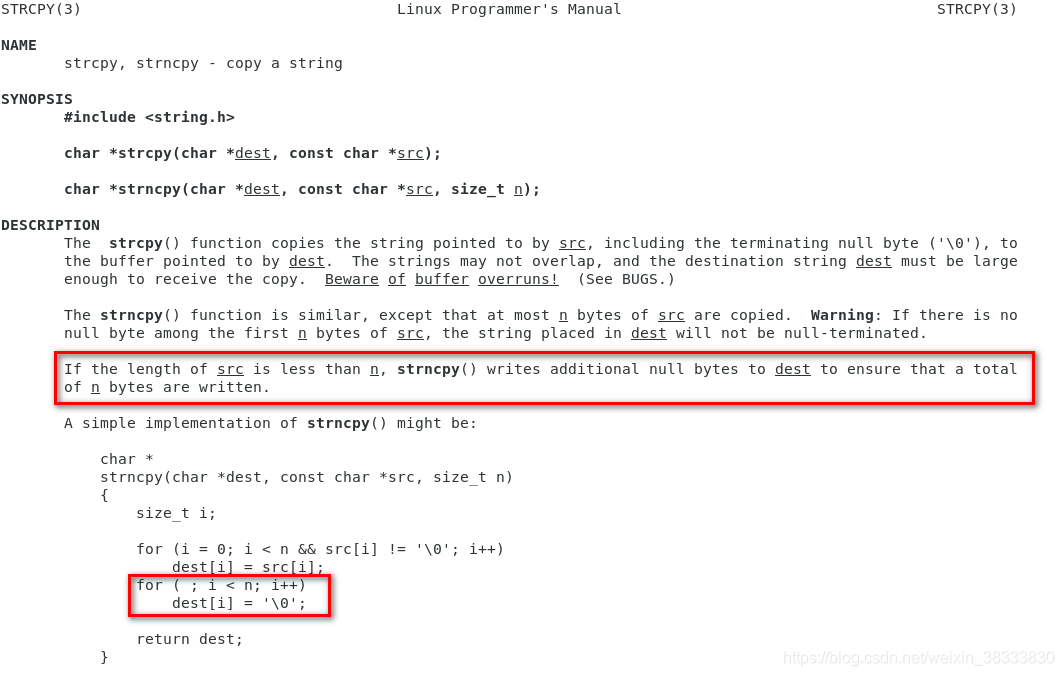
按公司的代码规范要求,strncpy 的第三个参数(lenLimit)要写目标地址空间的大小(lenDst),但是实际上,如果传给 strncpy 函数的第三个参数大于源字符串的长度,目标地址空间中,超出的部分会被清零:
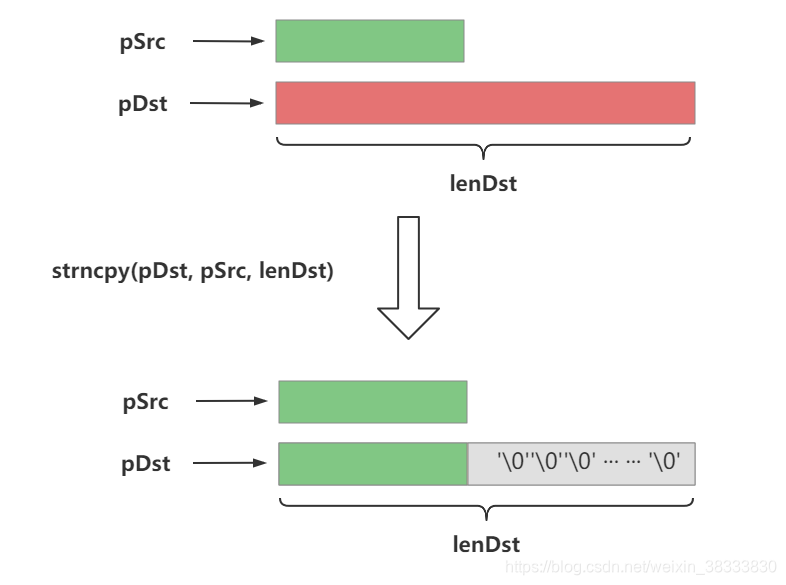
帮助手册说明
通过 man 3 strncpy 命令查看帮助手册对于 strncpy 函数的说明,证实了上面的说法:
影响
- 清零操作某种程度上是无意义的性能损耗,如果目标地址空间特别大,拷贝次数又比较多,可能出现明显的性能下降。
- 如果第三个参数超过了目标地址空间的大小,会把紧挨着目标地址空间,但是不属于目标地址空间的一部分内存也清零,即内存越界,或者说踩内存。
实验
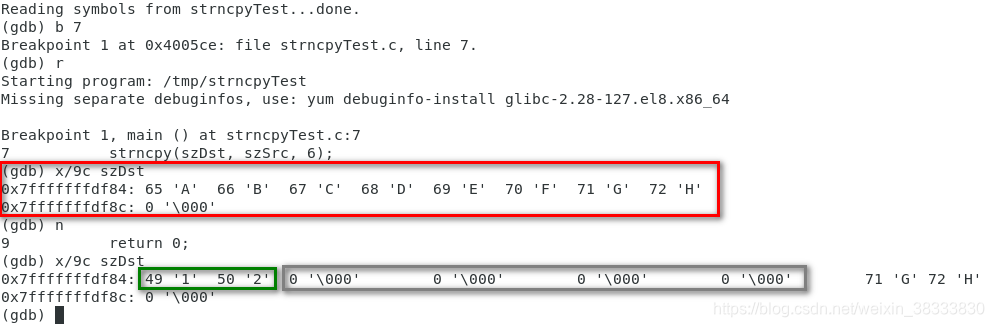
超出部分清零模拟
定义目标数组大小为 9,源数组大小为 3,设置 strncpy 的第三个参数为 6(故意超过源字符串的长度):

GDB 运行结果如下,红框框起来的是第 7 行 strncpy 执行前 szDst 的值,执行完第 7 行后,源字符串被拷贝到目标数组中(绿色框框起来的部分),但是 szDst 里紧跟着的四个字符也被清零(灰色框框起来的部分):
越界模拟
在 szSrc 和 szDst 之间增加一个临时变量 szTmp,把 strncpy 函数的第三个参数放大到 11:

函数的局部变量存储在栈中,栈从高地址向低地址生长,先定义的变量先入栈。
所以按当前的局部变量定义方式,是 szSrc 地址值最大,szTmp 次之,szDst 的地址值最小,而且三者在内存中紧挨在一起。当 strncpy 的第三个参数放大到 11,就会超出 szDst 的空间,覆盖 szTmp 的值,即出现内存越界(踩内存)的情况。GDB 运行结果:
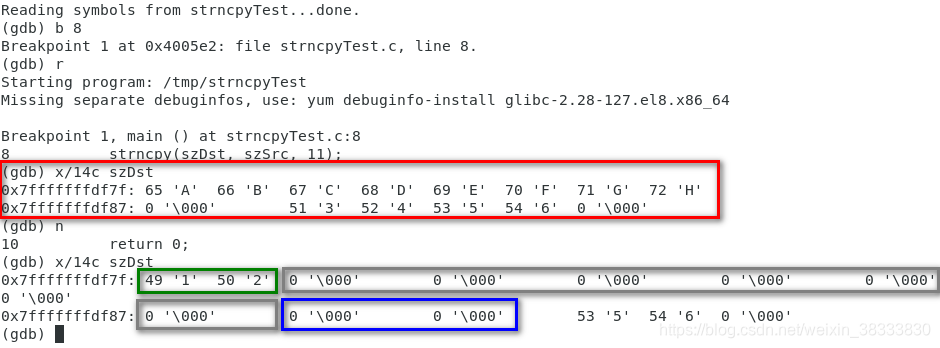
红框框起来的是第 8 行 strncpy 执行前 szDst 和 szTmp 的值,执行完第 8 行后,不仅 szDst 后半部分被清零(灰色框框起来的部分),szTmp 开头的两个字符位也被清零(蓝色框框起来的部分)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









