







 本文介绍了Python中的re.match()函数,该函数从字符串开头进行匹配,并返回match对象。内容包括如何使用group()和groups()获取匹配结果,以及预编译模式compile的应用。在未匹配成功时,match()返回None,使用group()和groups()需谨慎。
本文介绍了Python中的re.match()函数,该函数从字符串开头进行匹配,并返回match对象。内容包括如何使用group()和groups()获取匹配结果,以及预编译模式compile的应用。在未匹配成功时,match()返回None,使用group()和groups()需谨慎。
1 re.match() 函数
总是从字符串‘开头匹配’,并返回匹配的字符串的 match 对象 <class ‘_sre.SRE_Match’>
re.match(pattern, string[, flags=0])
•pattern 匹配模式,由 re.compile 获得
•string 需要匹配的字符串
import re
pattern = re.compile(r'hello')
a = re.match(pattern, 'hello world')
b = re.match(pattern, 'world hello')
c = re.match(pattern, 'hell')
d = re.match(pattern, 'hello ')
if a:
print(a.group())
else:
print('a 失败')
if b:
print(b.group())
else:
print('b 失败')
if c:
print(c.group())
else:
print('c 失败')
if d:
print(d.group())
else:
print('d 失败')

**我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。group(num=0) 获取匹配结果的各个分组的字符串,group() 可以一次输入多个组号,此时返回一个包含那些组所对应值的元组。
groups() 返回一个包含所有分组字符串的元组。
注意:如果未匹配成功,match()返回值为None,此时再使用group()、groups() 方法会报错。应该先获取匹配对象,然后判断匹配对象是否非空,当非空时在使用group()、groups() 方法获取匹配结果。
line="827007914----8421411penghueix"
matchobj=re.match(r"(.*)----(.*)",line)
print(matchobj.group(0))
print(matchobj.group(1))
print(matchobj.group(2))
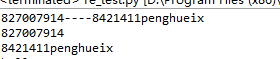
group(0)是详细描述
group(N)是匹配的分组
2预编译模式compile模式
import re
#re 预编译
pat=re.compile("(.*)----(.*)") #预编译可以加快速度
line="827007914----penghueix"
matchobj=pat.match(line)
print(matchobj.group()) #matchobj.group()等价matchobj.group(0)
print(matchobj.group(0)) #827007914----penghueix
print(matchobj.group(1)) #827007914
print(matchobj.group(2)) #penghueix


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









