







本文基于《Django企业开发实战》一书和网络资料,拼拼凑凑,做了简单的网站实现,大致把前后端+数据库方面的内容结合爬虫代码做通了。不得不说,Django和MongoDB是真的不搭配,强烈建议不要使用。
开始:conda环境
本文在Ubuntu18.04LTS系统上,使用anaconda搭建虚拟环境,python版本为3.6.10,主要库版本为django(1.11.4),mongoengine(0.20.0),pymongo(3.10.1),以及爬虫用的requests(2.24.0)和beautifulsoup4(4.9.1)。爬虫部分详见上一篇文章的内容,这边稍作改造直接拿来用。
第一部分:Django与MongoDB的适配
关于Django项目的创建此处先略,建议直接参考《Django企业开发实战》这本的第3章,具体内容有空再补。
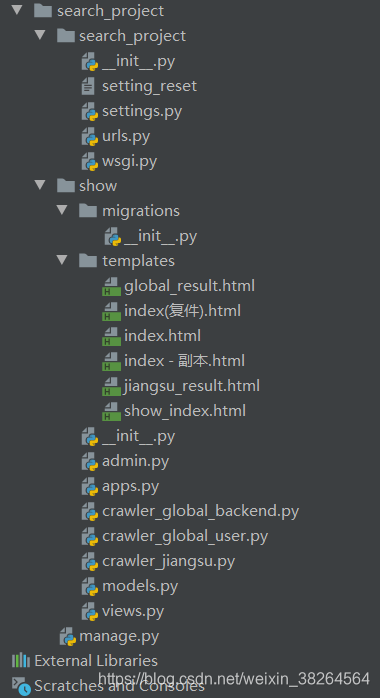
最终本文成品的文件结构如下(最外边还有一个search_project文件夹,是禁忌的三重套娃):
在本地安装好MongoDB以及创建好Django项目后,首先是在settings.py中屏蔽掉默认非常好使的sqlite,转而添加上必须由第三方支持才能使用而且资料极少的MongoDB依赖项,主要参考来自于Django 数据库操作(MongoDB+Django),Django+MongoDB,Scrapy爬取数据存储到Mongodb数据库,python+django从mongo读取数据和图片展示在html,Django 框架之 使用MangoDB数据库这几篇博客。
我的settings.py文件修改完成后如下:
"""
Django settings for search_project project.
Generated by 'django-admin startproject' using Django 1.11.4.
For more information on this file, see
https://docs.djangoproject.com/en/1.11/topics/settings/
For the full list of settings and their values, see
https://docs.djangoproject.com/en/1.11/ref/settings/
"""
import os
import mongoengine
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/
# SECURITY WARNING: keep the secret key used in production secret!
SECRET_KEY = '**^!7vv0ylwqme#^a6zs*$x)zzwgff-(u_6va%q@u-_g5wz8q#'#项目创建生成的key,每个都不一样
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = False
ALLOWED_HOSTS = ['*']
# Application definition
#show是我的app名,而mongoengine也作为第三方组件需要被当做app
INSTALLED_APPS = [
'show',
'mongoengine',
'django.contrib.admin',
'django.contrib.auth',
'rest_framework.authtoken',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
#mongodb数据库的名字,地址,以及??
MONGODB_DATABASES = {
"default": {
"name": "search_record",
"host": '127.0.0.1',
'tz_aware': True,
}
}
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'search_project.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = 'search_project.wsgi.application'
# Database
# https://docs.djangoproject.com/en/1.11/ref/settings/#databases
#注释掉sqlite部分
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.dummy',
#'ENGINE': 'django.db.backends.sqlite3',
#'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
#连接数据库
mongoengine.connect('search_record', host='127.0.0.1', port=27017)
# Password validation
# https://docs.djangoproject.com/en/1.11/ref/settings/#auth-password-validators
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
# Internationalization
# https://docs.djangoproject.com/en/1.11/topics/i18n/
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/1.11/howto/static-files/
STATIC_URL = '/static/'第二部分:Model创建
由于需求很简单,也没有涉及管理员和用户系统(Django+MongDB在这方面非常对新手而言非常不友好),所以只需要创建两个用于存储不同网站爬虫信息的模型即可。在show这个app里的models.py文件中创建两个class,分别对应江苏和全国的爬虫数据格式。
from django.db import models
import datetime
from mongoengine import *
# Create your models here.
"""
为了方便日期时间等存储,还是建议将相关类设置为DateTimeField格式,
这个可以由datetime库的数据类型直接存储,不需要做转换,
此外mate中ordering为排序key,这边取负数“-”倒序,
务必确认这里属性的名称和实际数据库中的名称一致(不然网页会报错500)
"""
class JiangSu_Record(Document):
title = StringField(max_length=2048, required=True)
url = StringField(max_length=2048, required=True)
start_time = DateTimeField(required=True)
deadline = DateTimeField(required=True)
issue_time = DateTimeField(required=True)
project_type = StringField(max_length=32, required=True)
created_time = DateTimeField(default=datetime.datetime.now(), required=True)
meta = {'collection': 'JiangSu', 'ordering': ['-created_time'], }
#江苏的相关信息包括标题,链接,开始时间,截止时间,发布时间,项目类型和创建时间,存在数据库的JiangSu这个集合中
class Global_Record(Document):
title = StringField(max_length=2048, required=True)
url = StringField(max_length=2048, required=True)
area_city = StringField(max_length=64, required=True)
issue_date = DateTimeField(required=True)
created_time = DateTimeField(default=datetime.datetime.now(), required=True)
meta = {'collection': 'Global', 'ordering': ['-created_time'], }
#全国的相关信息包括标题,链接,区域,发布时间和创建时间,存在数据库的Global这个集合中由于Django不支持MongoDB下的admin设置,所以admin.py的设置直接略去,同理,创建数据库迁移文件,创建表和创建超级用户等过程也略去。
第三部分:view和html以及URL配置
在app的views.py文件中创建相应网页的视图函数,分别对应主页,江苏查询页和全国查询页。实现MongoDB数据库操作的QuerySet接口是Django自带的,可以大致参考QuerySet API reference以及其他博文。
from django.shortcuts import render
import datetime
from .models import JiangSu_Record, Global_Record
import os, django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "search_project.settings")# project_name 项目名称
django.setup()
from .crawler_jiangsu import is_date, visit_jiangsu_home
from .crawler_global_user import update_or_not
#直接使用render渲染页面
def index(request):
return render(request, 'index.html')
def jiangsu_result(request):
visit_jiangsu_home()#每次都先爬取,如果是post操作则会读取post数据进行相应查询操作
if request.method == "POST":
jiangsu_key_word = request.POST.get('jiangsu_key_word', None)
jiangsu_date = request.POST.get('jiangsu_date', None)
jiangsu_date = is_date(jiangsu_date)
target_results = JiangSu_Record.objects.all()
if jiangsu_key_word is not None:#匹配多关键词
keys = jiangsu_key_word.split(" ")
for key in keys:
target_results = target_results.filter(title__contains=key)
else:
pass
if jiangsu_date is not None:
target_results = target_results.filter(deadline__gte=jiangsu_date)
else:
pass
context = {'results': target_results}
return render(request, 'jiangsu_result.html', context=context)
else:
jiangsu_results = JiangSu_Record.objects.all()
context = {'results': jiangsu_results}
return render(request, 'jiangsu_result.html', context=context)
def global_result(request):
update_or_not()
if request.method == "POST":
global_key_word = request.POST.get('global_key_word', None)
global_date = request.POST.get('global_date', None)
global_date = is_date(global_date)
target_results = Global_Record.objects.all()
if global_key_word is not None:
keys = global_key_word.split(" ")
for key in keys:
target_results = target_results.filter(title__contains=key)
else:
pass
if global_date is not None:
target_results = target_results.filter(issue_date__gte=global_date)
else:
pass
target_results = target_results[:100]#只显示前100行数据(最新创建的100行)
context = {'results': target_results}
return render(request, 'global_result.html', context=context)
else:
global_results = Global_Record.objects.all()[:100]
context = {'results': global_results}
return render(request, 'global_result.html', context=context)
在写好view.py以后,在app目录下创建templates文件(注意:有“s”),在这个文件夹中创建相应的网页文件,使view中的函数在渲染时能直接调用这些网页。
本文需要3个页面,分别是主页index.html:
<!DOCTYPE html>
<head>
<title>首页</title>
</head>
<body>
<hr/>
<a target="_blank" href="/jiangsu_result/">江苏搜索</a>
<hr/>
<a target="_blank" href="/global_result/">全国搜索</a>
<hr/>
</body>
</html>这个页面只是实现简单的跳转功能。
江苏爬虫查询页面jiangsu_result.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>江苏-搜索结果</title>
</head>
<body>
<hr/>
<form action="/jiangsu_result/" method="post" align="center">
{% csrf_token %}
关键字:<input type="text" name="jiangsu_key_word" />
公告截止日期:<input type="text" name="jiangsu_date" />
<input type="submit" value="江苏搜索" />
</form>
<hr/>
<table border="1" align="center">
<tbody>
<tr>
<th>公告名称</th>
<th>公告截止日期</th>
<th>公告发布日期</th>
<th>项目类型</th>
<th>公告链接</th>
</tr>
{% for item in results %}
<tr>
<td width="1000" align="left">{{ item.title }}</td>
<td width="250" align="center">{{ item.deadline }}</td>
<td width="250" align="center">{{ item.issue_time }}</td>
<td width="200" align="center">{{ item.project_type }}</td>
<td width="100" align="center"><a href={{ item.url }}>链接</a></td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>此处的results就是views.py中render函数context中的内容。
全国爬虫查询页面global_result.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>全国-搜索结果</title>
</head>
<body>
<hr/>
<form action="/global_result/" method="post" align="center">
{% csrf_token %}
关键字:<input type="text" name="global_key_word" />
起始公布日期:<input type="text" name="global_date" />
<input type="submit" value="全国搜索" />
</form>
<hr/>
<table border="1" align="center">
<tbody>
<tr>
<th>公告名称</th>
<th>地区</th>
<th>公告发布日期</th>
<th>公告链接</th>
</tr>
{% for item in results %}
<tr>
<td width="1000" align="left">{{ item.title }}</td>
<td width="150" align="center">{{ item.area_city }}</td>
<td width="250" align="center">{{ item.issue_date }}</td>
<td width="100" align="center"><a href={{ item.url }}>链接</a></td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>最后进行URL配置,即对settings.py同级的urls.py文件进行修改:
from django.conf.urls import url
from django.contrib import admin
from django.contrib.staticfiles.urls import staticfiles_urlpatterns
from show import views
#分别对应3个界面的3个映射
urlpatterns = [
url(r'^$', views.index, name='index'),
url(r'^jiangsu_result', views.jiangsu_result, name='jiangsu_result'),
url(r'^global_result', views.global_result, name='global_result'),
url(r'^admin/', admin.site.urls),
]
urlpatterns += staticfiles_urlpatterns()#此处意义未理解第四部分:完成
回到项目文件目录下,在命令行输入python manage.py runserver启动项目,访问http://127.0.0.1:8000即可以访问主页。
其他:
对上一篇中的爬虫程序做了一些修改,补充了相应的数据库操作和后台自动更新数据库等功能,代码如下。
其中江苏数据更新量少,可以每次查询前先更新一下,不需要在后台不断更新:
# -*- coding: utf-8 -*-
import requests, json
from bs4 import BeautifulSoup
import time
import datetime
import sys
from pymongo import MongoClient, InsertOne
import re
def visit_jiangsu_home(x=10):#默认找前10页
#模拟头部分
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Content-Length': '14',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=6938F495DAA5F25B2E458C7AB108BEDF',
'Host': '218.2.208.144:8094',
'Origin': 'http://218.2.208.144:8094',
'Referer': 'http://218.2.208.144:8094/EBTS/publish/announcement/paglist1?type=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
#模拟form data部分
form_data = {
'page':'1',
'rows': '10'
}
#空字典存放信息
#home_dict = {}
#从第一页开始
times = 1
repeat_num = 0
while times <= x:
form_data['page'] = times
#注意url是Name下的链接,不是网址
url = 'http://218.2.208.144:8094/EBTS/publish/announcement/getList?placard_type=1'
response = requests.post(url, data=form_data, headers=headers, stream=True)
#请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
soup = str(soup)
for i in range(1,11):#由于每页有10行即10个信息,故分可以根据关键字分为11段,其中有效信息在第2到第11段
id = soup.split('placard_id":"')[i].split('","project_id')[0]#提取公告ID
mark = soup.split('is_new_tuisong":"')[i].split('","remark_id')[0]#提取是否是修改型的公告
project_type = soup.split('tender_project_type":"')[i].split('","publish_remark_by_zzw')[0]#提取招标种类
station = visit_single_website(id, mark, project_type) #访问单个网站并插入数据库
if station == False:
repeat_num+=1
if repeat_num>10:
print("重复过多")
return
times= times+1
time.sleep(0.5)#防止频繁访问
#return home_dict
return
def visit_single_website(id, mark, project_type):
data_address_first1 = 'http://218.2.208.148:9092/api/BiddingNotice/GetByKeys?BNID=' # 普通公告json链接头
data_address_first2 = 'http://218.2.208.148:9092/api/BiddingNoticeAdditional/GetByKeys?TNAID=' # 更正公告json链接头
page_address_first1 = 'http://218.2.208.148:9092/OP/Bidding/BiddingNoticeAdditionalView.aspx?bnid=' # 普通公告网址头
page_address_first2 = 'http://218.2.208.148:9092/OP/Bidding/BiddingNoticeAdditionalView2.aspx?action=view&TNAID=' # 更正公告网址头
if int(mark)==2: #是更正公告
page_url = page_address_first2 + id
address_url = data_address_first2 + id
try:
return_data = requests.get(address_url, stream=True) #获取json中的全部内容
all_content = json.loads(return_data.content)
try:
title = str(all_content.get('TNANAME')) # 更正公告的标题,普通公告中没有这个TNANAME项
except:
title = "无公告内容"
try:
start_date = str(all_content.get('APPLYBEGINTIME')).replace("T", " ") # 截止日期
start_date = datetime.datetime.strptime(start_date, '%Y-%m-%d %H:%M:%S')
except:
start_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
try:
deadline = str(all_content.get('APPLYENDTIME')).replace("T", " ") # 截止日期
deadline = datetime.datetime.strptime(deadline, '%Y-%m-%d %H:%M:%S')
except:
deadline = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
try:
issue_date = str(all_content.get('CREATETIME')).replace("T", " ") # 公布日期
issue_date = datetime.datetime.strptime(issue_date, '%Y-%m-%d %H:%M:%S')
except:
issue_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
except:
title = "无公告内容"
start_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
deadline = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
issue_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
else:
page_url = page_address_first1 + id
address_url = data_address_first1 + id
try:
return_data = requests.get(address_url, stream=True)
all_content = json.loads(return_data.content)
try:
title = str(all_content.get('BNNAME')) # 普通公告的标题
except:
title = "无公告内容"
try:
start_date = str(all_content.get('APPLYBEGINTIME')).replace("T", " ") # 截止日期
start_date = datetime.datetime.strptime(start_date, '%Y-%m-%d %H:%M:%S')
except:
start_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
try:
deadline = str(all_content.get('APPLYENDTIME')).replace("T", " ") # 截止日期
deadline = datetime.datetime.strptime(deadline, '%Y-%m-%d %H:%M:%S')
except:
deadline = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
try:
issue_date = str(all_content.get('CREATETIME')).replace("T", " ") # 公布日期
issue_date = datetime.datetime.strptime(issue_date, '%Y-%m-%d %H:%M:%S')
except:
issue_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
except:
title = "无公告内容"
start_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
deadline = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
issue_date = datetime.datetime.strptime("1993-01-03", '%Y-%m-%d')
state = insert_single_data(title, page_url, start_date, deadline, issue_date, project_type) #true或者false计数
return state
def insert_single_data(title, page_url, start_date, deadline, issue_date, project_type):
conn = MongoClient("127.0.0.1:27017", maxPoolSize=None)
my_db = conn['search_record']
try:
my_db['JiangSu'].insert_one({"title": title,
"url": page_url,
"start_time": start_date,
"deadline": deadline,
"issue_time": issue_date,
"project_type": project_type,
"created_time": datetime.datetime.now()})
conn.close()
print(title, page_url, start_date, deadline, issue_date, project_type)
print("插入成功")
return True
except:
print("重复,插入失败")
conn.close()
return False
def search_jiangsu_record(key_word=None, deadline=None):
conn = MongoClient("127.0.0.1:27017", maxPoolSize=None)
my_db = conn['search_record']
my_col = my_db['JiangSu']
search_result = []
if deadline==None:
deadline = datetime.datetime.now()
if key_word!=None:
key_word = make_key_word(key_word)
for x in my_col.find({"title": re.compile(key_word), "deadline": {"$gte":deadline}}):
search_result.append(x)
conn.close()
else:
for x in my_col.find({"deadline": {"$gte":deadline}}):
search_result.append(x)
conn.close()
if len(search_result)==0:
search_result="No Result"
return search_result
def make_key_word(str_input):
str_list = str_input.split(" ")
print(str_list)
str_more = ""
for i in str_list:
str_more = str_more+"(?=.*?"+i+")"
str_more = "^"+str_more+".+"
print(str_more)
return str_more
def crawler_and_search(jiangsu_key_word, jiangsu_date):
visit_jiangsu_home(x=10)
str_more = make_key_word(jiangsu_key_word)
deadline = is_date(jiangsu_date)
return search_jiangsu_record(key_word=str_more, deadline=deadline)
def is_date(date):
try:
deadline = datetime.datetime.strptime(date, '%Y-%m-%d')
except:
deadline = None
return deadline
if __name__ == "__main__":
jiangsu_key_word = input("关键字:")
jiangsu_date = input("日期:")
print(crawler_and_search(jiangsu_key_word, jiangsu_date))全国数据更新速度快,故设置一个后台更新程序,每十五分钟爬取一次更新数据库:
# -*- coding: utf-8 -*-
import requests
import os
from bs4 import BeautifulSoup
import time
import datetime
import sys,json
from pymongo import MongoClient, InsertOne
import re
# 创建标记文件
def create_mark_file(mark_file_path):
mark_file = open(mark_file_path, "w")
mark_file.close()
# 删除标记文件
def delete_mark_file(mark_file_path):
if os.path.exists(mark_file_path):
os.remove(mark_file_path)
else:
pass
def visit_global_home(key_word=None, max_repeat=200):
# 模拟头部分
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '181',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=585E887A70EA60F7982104CE88AE9B7E; UM_distinctid=1735f8daa6a299-0f79f479f2fe33-b7a1334-144000-1735f8daa6b447; CNZZdate2114438=cnzz_eid%3D1721879153-1595032889-http%253A%252F%252Fwww.infobidding.com%252F%26ntime%3D1595032889',
'Host': 'www.infobidding.com',
'Origin': 'http://www.infobidding.com',
'Referer': 'http://www.infobidding.com/listAction.do?count=25&type=2&freeflg=&tradeid=',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
}
# 模拟form data部分
form_data = {
'cdiqu': '-1',
'pdiqu': '-1',
'term': None,
'areaid': '-1',
'townid': '-1',
'pageNum': '1',
'#request.state': '1',
'#request.tname': None,
'#request.type': '2',
'#request.flg': None,
'#request.tradeid': None,
}
form_data['term'] = key_word
url = 'http://www.infobidding.com/listAction.do?count=25&type=2&freeflg=&tradeid='
response = requests.post(url, data=form_data, headers=headers)
# 请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
if soup.find_all(colspan="5") != []:
# notice_list.append("没有查到相关数据!")
# 无内容则退出,不做数据库的任何操作
print("无内容")
return
else:
all_repeat_num = 0 # 总重复数
max_repeat_num = max_repeat # 最大重复数
all_repeat_num = all_repeat_num + get_name_date_area(soup) # 对第一页进行插入,返回这一页的重复数并加入总重复数
#print("完成第1页")
try: # 如果有多页,则从第二页开始,先获取总页数
page_num_is = \
str(soup.find_all(style="text-align: center;", colspan="4")[0]).split("</font>/")[1].split("页")[0]
#print("有多页内容")
time.sleep(1)
for i in range(2, int(page_num_is) + 1):
form_data['pageNum'] = str(i)
response = requests.post(url, data=form_data, headers=headers)
# 请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
all_repeat_num = all_repeat_num + get_name_date_area(soup) # 返回这一页的重复数并加入总重复数
#print("完成第" + str(i) + "页")
if all_repeat_num > max_repeat_num: # 超过则退出
return
time.sleep(1)
except:
print("无多页内容")
return
def get_name_date_area(soup): # soup是网页内全部内容
repeat_num = 0 # 每一页的重复数
for x in soup.find_all(align="left", height="28px"):
title = str(x.find_all(width="68%")).split('hand;">')[1].split('</span>')[0].strip()
url_ads = "http://www.infobidding.com" + str(x.find_all(width="68%")).split('href="')[1].split('" target=')[
0].strip()
area = str(x.find_all(width="11%")).split('color="red">')[1].split('</font>')[0].strip()
date = str(x.find_all(width="10%")).split('color="red">')[1].split('</font>')[0].strip()
date = datetime.datetime.strptime(date, "%Y-%m-%d")
insertion = insert_global_data(title, url_ads, area, date) # 插入变为原子行为
if insertion == False:
repeat_num += 1
return repeat_num
# 单项插入
def insert_global_data(title, url_ads, area, date):
conn = MongoClient("127.0.0.1:27017", maxPoolSize=None)
my_db = conn['search_record']
try:
my_db['Global'].insert_one({"title": title,
"url": url_ads,
"area_city": area,
"issue_date": date,
"created_time": datetime.datetime.now()})
conn.close()
#print("插入成功")
return True # 成功插入
except:
conn.close()
#print("重复,插入失败")
return False # 插入失败
def is_date(notice_list, date=''):
if notice_list[0] == "没有查到相关数据!":
lan = "没有查到该日期的数据,请重新输入关键字或日期!\n"
print(lan)
return lan
elif date == '':
text_content = as_text(notice_list)
return text_content
else:
date_notice = []
for i in range(len(notice_list)):
if notice_list[i][3].strip() == date:
date_notice.append(notice_list[i])
if len(date_notice) == 0:
lan = "没有查到该日期的数据,请重新输入关键字或日期!\n"
print(lan)
return lan
text_content = as_text(date_notice)
return text_content
def as_text(list_text):
text = ''
for i in range(len(list_text)):
text = text + "No." + str(i + 1) + "\n" + "日期:" + str(list_text[i][3]) + "\t" + "地区:" + str(list_text[i][2]) \
+ "\n" + "公告名称:" + str(list_text[i][0]) + "\n" + "链接:" + str(list_text[i][1]) + "\n"
return text
def search_global_record(key_word=None, issue_date=None):
conn = MongoClient("127.0.0.1:27017", maxPoolSize=None)
my_db = conn['search_record']
my_col = my_db['Global']
search_result = []
for x in my_col.find({"title": re.compile(key_word), "issue_date": re.compile(issue_date)}):
print(x)
search_result.append(x)
conn.close()
return search_result
def make_key_word(str_input):
str_list = str_input.split(" ")
print(str_list)
str_more = ""
for i in str_list:
str_more = str_more + "(?=.*?" + i + ")"
str_more = "^" + str_more + ".+"
print(str_more)
return str_more
def is_the_time():
the_time = str(datetime.datetime.now()).split(" ")[1].split(".")[0].split(":")
# 只在6点到22点的整点和半点进行后台爬虫
if (int(the_time[0])>=6 and int(the_time[0])<=22 and (int(the_time[1])==0 or int(the_time[1])==30 or int(the_time[1])==15 or int(the_time[1])==45)):
return True
else:
return False
def backend_crawler():
mark_file_path = os.getcwd() + "/inserting.txt"
print("启动后端爬虫更新")
while(True):
if is_the_time():
print(datetime.datetime.now(), "到点爬虫开始")
if os.path.exists(mark_file_path):
print("数据库正在手动更新,自动更新暂停,休眠5分钟")
time.sleep(300)# 休眠5分钟
while(os.path.exists(mark_file_path)):# 若5分钟后还在手动更新,则继续等5分钟
print("数据库正在手动更新,自动更新暂停,再次休眠5分钟")
time.sleep(300) # 休眠5分钟
# 直到手动更新结束,开始自动更新
create_mark_file(mark_file_path) # 创建标记文件
visit_global_home(max_repeat=200) # 插入
delete_mark_file(mark_file_path) # 删除标记文件
print(datetime.datetime.now(), "数据库自动更新完成")
else:# 不在自动更新中则立刻开始自动更新
create_mark_file(mark_file_path)# 创建标记文件
visit_global_home(max_repeat=500)# 插入
delete_mark_file(mark_file_path)# 删除标记文件
# 完成更新,休眠一段时间
print(datetime.datetime.now(), "数据库自动更新完成")
else:
#print(datetime.datetime.now(), "没到点")
pass
#每分钟查看一次是否到设定时间
time.sleep(60)
if __name__=="__main__":
backend_crawler()手工操作时先更新后查询则使用如下部分代码:
# -*- coding: utf-8 -*-
import requests
import os
from bs4 import BeautifulSoup
import time
import datetime
from pymongo import MongoClient
import re
def search_first_or_later(max_repeat=100, key_word=None, issue_date=None):
mark_file_path = os.getcwd() + "/inserting.txt"
key_word = make_key_word(key_word)
if os.path.exists(mark_file_path):# 若存在,说明最近刚更新过
print("刚更新过,直接搜索")
search_global_record(key_word=key_word, issue_date=issue_date)# 直接搜索
else:
print("先更新再搜索")
create_mark_file(mark_file_path)
visit_global_home(max_repeat=max_repeat)# 进行爬取和插入
search_global_record(key_word=key_word, issue_date=issue_date) #再搜索
delete_mark_file(mark_file_path)
def update_or_not(max_repeat=100):
mark_file_path = os.getcwd() + "/inserting.txt"
if os.path.exists(mark_file_path):# 若存在,说明最近刚更新过
print("刚更新过")
pass
else:
print("先更新")
create_mark_file(mark_file_path)
visit_global_home(max_repeat=max_repeat)# 进行爬取和插入
delete_mark_file(mark_file_path)
# 创建标记文件
def create_mark_file(mark_file_path):
mark_file = open(mark_file_path, "w")
mark_file.close()
# 删除标记文件
def delete_mark_file(mark_file_path):
if os.path.exists(mark_file_path):
os.remove(mark_file_path)
else:
pass
def visit_global_home(key_word=None, max_repeat=200):
#模拟头部分
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '181',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=585E887A70EA60F7982104CE88AE9B7E; UM_distinctid=1735f8daa6a299-0f79f479f2fe33-b7a1334-144000-1735f8daa6b447; CNZZdate2114438=cnzz_eid%3D1721879153-1595032889-http%253A%252F%252Fwww.infobidding.com%252F%26ntime%3D1595032889',
'Host': 'www.infobidding.com',
'Origin': 'http://www.infobidding.com',
'Referer': 'http://www.infobidding.com/listAction.do?count=25&type=2&freeflg=&tradeid=',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
}
#模拟form data部分
form_data = {
'cdiqu': '-1',
'pdiqu': '-1',
'term': None,
'areaid': '-1',
'townid': '-1',
'pageNum': '1',
'#request.state': '1',
'#request.tname': None,
'#request.type': '2',
'#request.flg': None,
'#request.tradeid': None,
}
form_data['term'] = key_word
url = 'http://www.infobidding.com/listAction.do?count=25&type=2&freeflg=&tradeid='
response = requests.post(url, data=form_data, headers=headers)
# 请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
if soup.find_all(colspan="5") != []:
#notice_list.append("没有查到相关数据!")
#无内容则退出,不做数据库的任何操作
print("无内容")
return
else:
all_repeat_num = 0# 总重复数
max_repeat_num = max_repeat# 最大重复数
all_repeat_num = all_repeat_num + get_name_date_area(soup)#对第一页进行插入,返回这一页的重复数并加入总重复数
print("完成第1页")
try:#如果有多页,则从第二页开始,先获取总页数
page_num_is = str(soup.find_all(style="text-align: center;", colspan="4")[0]).split("</font>/")[1].split("页")[0]
print("有多页内容")
time.sleep(1)
for i in range(2, int(page_num_is)+1):
form_data['pageNum'] = str(i)
response = requests.post(url, data=form_data, headers=headers)
# 请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
all_repeat_num = all_repeat_num + get_name_date_area(soup)#返回这一页的重复数并加入总重复数
print("完成第" + str(i) + "页")
if all_repeat_num > max_repeat_num:#超过则退出
return
time.sleep(1)
except:
print("无多页内容")
return
def get_name_date_area(soup):#soup是网页内全部内容
repeat_num = 0 #每一页的重复数
for x in soup.find_all(align="left", height="28px"):
title = str(x.find_all(width="68%")).split('hand;">')[1].split('</span>')[0].strip()
url_ads = "http://www.infobidding.com"+str(x.find_all(width="68%")).split('href="')[1].split('" target=')[0].strip()
area = str(x.find_all(width="11%")).split('color="red">')[1].split('</font>')[0].strip()
date = str(x.find_all(width="10%")).split('color="red">')[1].split('</font>')[0].strip()
date = datetime.datetime.strptime(date, "%Y-%m-%d")
insertion = insert_global_data(title, url_ads, area, date)#插入变为原子行为
if insertion==False:
repeat_num += 1
return repeat_num
# 单项插入
def insert_global_data(title, url_ads, area, date):
conn = MongoClient("127.0.0.1:27017", maxPoolSize=None)
my_db = conn['search_record']
try:
my_db['Global'].insert_one({"title": title,
"url": url_ads,
"area_city": area,
"issue_date": date,
"created_time": datetime.datetime.now()})
conn.close()
print("插入成功")
return True#成功插入
except:
conn.close()
print("重复,插入失败")
return False#插入失败
def is_date(notice_list, date=''):
if notice_list[0] == "没有查到相关数据!":
lan = "没有查到该日期的数据,请重新输入关键字或日期!\n"
print(lan)
return lan
elif date == '':
text_content = as_text(notice_list)
return text_content
else:
date_notice = []
for i in range(len(notice_list)):
if notice_list[i][3].strip() == date:
date_notice.append(notice_list[i])
if len(date_notice)==0:
lan = "没有查到该日期的数据,请重新输入关键字或日期!\n"
print(lan)
return lan
text_content = as_text(date_notice)
return text_content
def as_text(list_text):
text = ''
for i in range(len(list_text)):
text = text+"No."+str(i+1)+"\n"+"日期:"+str(list_text[i][3])+"\t"+"地区:"+str(list_text[i][2])\
+"\n"+"公告名称:"+str(list_text[i][0])+"\n"+"链接:"+str(list_text[i][1])+"\n"
return text
def search_global_record(key_word=None,issue_date=None):
conn = MongoClient("127.0.0.1:27017", maxPoolSize=None)
my_db = conn['search_record']
my_col = my_db['Global']
search_result = []
if issue_date==None:
deadline = datetime.datetime.now()
for x in my_col.find({"title": re.compile(key_word), "issue_date": re.compile(issue_date)}):
print(x)
search_result.append(x)
conn.close()
return search_result
def make_key_word(str_input):
str_list = str_input.split(" ")
print(str_list)
str_more = ""
for i in str_list:
str_more = str_more+"(?=.*?"+i+")"
str_more = "^"+str_more+".+"
print(str_more)
return str_more
def is_date(date):
try:
deadline = datetime.datetime.strptime(date, '%Y-%m-%d')
except:
deadline = None
return deadline
if __name__=="__main__":
search_first_or_later(key_word="江苏 有限公司 高速", issue_date="2020-08-20")收工。

















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









