







 本文介绍了在Hive SQL中处理非等值连接和范围匹配的问题,提供了两种解决方案:一是利用关联查询,通过左外连接筛选满足时间范围的记录;二是运用开窗函数,结合最大结束时间判断匹配值。同时,讨论了ON后的AND条件与WHERE子句的区别,并强调了SQL书写规范,如逗号放置和注释技巧。
本文介绍了在Hive SQL中处理非等值连接和范围匹配的问题,提供了两种解决方案:一是利用关联查询,通过左外连接筛选满足时间范围的记录;二是运用开窗函数,结合最大结束时间判断匹配值。同时,讨论了ON后的AND条件与WHERE子句的区别,并强调了SQL书写规范,如逗号放置和注释技巧。
🌿挑战100天不停更,刷爆 hive sql🧲
详情请点击🔗我的专栏🖲,共同学习,一起进步~
文章目录
NUM: 第22天 - 非等值连接-范围匹配
表 f 是事实表,
表 d 是匹配表,
在 hive 中如何将匹配表中的值关联到事实表中? 表 d 相当于拉链过的变化维,但日期范围可能是不全的。
那我们要怎么匹配呢??
🧨不废话,刷题~~🧨
🎈表结构
f: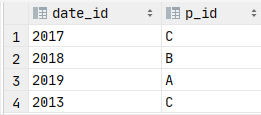
d: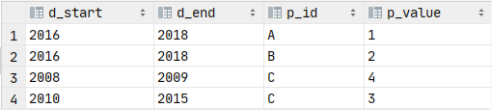
🎉建表
-- 建表并插入数据
-- 事实表
create table f
(
date_id string,
p_id string
);
-- 匹配表
create table d
(
d_start string,
d_end string,
p_id string,
p_value string
);
insert into f (date_id, p_id)
values ('2017', 'C'),
('2018', 'B'),
('2019', 'A'),
('2013', 'C');
insert into d (d_start, d_end, p_id, p_value)
values ('2016', '2018', 'A', '1'),
('2016', '2018', 'B', '2'),
('2008', '2009', 'C', '4'),
('2010', '2015', 'C', '3');
👓问题:范围匹配
✨先看执行结果
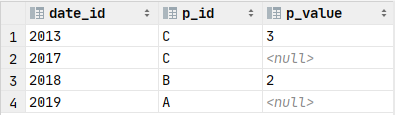
解法一:利用关联查询
🎨思考
- 拉链表的数据并不是连续的,封链时间也不固定? 那我们要怎么匹配呢?注意:比如
2017年的时间是拉链表的start在end之间,并且,时间范围可能不存在 - 左外关联拉链表,并求得
时间>=开始时间并<=结束时间,这一步是筛选时间 - 再以
f表为主表,左外关联筛选过的时间表,这就能得出了事实表所匹配维度表的所有值了 - 问题:
left join后面跟and和from后面的where有什么区别呢??都可以加查询条件- 这里首先要理解,我们再进行关联查询的时候,会生成一张临时表返回给客户端
on后面用and连接,都作为on的条件,on的优先级大于where,on后面跟的条件是先筛选当前表的条件,再合并给临时表 - 这么说可能还不好理解,再简单点说,
a和b两张表,a左外关联b,这时要匹配b='..'的条件,就是先查出b表中b='...'的记录行,再关联给a,即使不符合b的表,这个时候就有可能出现null值
那我们要在什么条件下使用**on **后面 跟**and **去作为条件呢? - 以
left join为例,我们想要即使不满足条件的时候,a表的关联的所有字段,这时候就应该把过滤条件加在on后面,但是这样会有会有null值,如果是放在where后面就会对临时表进行全局筛选 **on**后面用**where**连接,代表筛选条件,是对临时表的全局进行筛选
- 这里首先要理解,我们再进行关联查询的时候,会生成一张临时表返回给客户端
详情请参考:left join on 后and 和 where 的区别
🧨SQL
-- 2,再以f表为主表,左外关联筛选过的时间表,这就能得出了事实表所匹配维度表的所有值了
select f.date_id
, f.p_id
, A.p_value
from f
left join (
select date_id
, p_id
, p_value
from (
--1,左外关联拉链表,并求得时间>=开始时间 并<=结束时间,这一步是筛选时间
select f.date_id
, f.p_id
, d.p_value
from f
left join d on f.p_id = d.p_id
where f.date_id >= d.d_start
and f.date_id <= d.d_end
) A
) A ON f.date_id = A.date_id;
解法二:开窗函数
🎨思考
- 共同
left join关联,取出全部的数据后,筛选date_id时间再开始和结束时间之间 - 通过开窗函数
max(d_end)求得结束时间最大的时间 - 当最大的结束时间=结束时间时,取出对应的值即可
这里为什么要用**max()****开窗函数呢?? **
累计求出的最大的结束时间,其实就是去除重复的数据,保留单行数据
🧨SQL
select date_id
, p_id
, flag as p_value
from (
select f.date_id
, f.p_id
, d.d_start
, d.d_end
, d.p_value
, if(f.date_id between d.d_start and d.d_end, d.p_value, null) flag
, max(d.d_end) over (partition by date_id) max_end
from f
left join d on f.p_id = d.p_id
) tmp
where d_end = max_end;
关于sql的规范问题
尽量把逗号放在前面,为什么?
1,方便排查,不会遗漏逗号
2,方便注释,可以单行直接注释,不用再改逗号
3,排版看起来更紧密,我用datagrip快捷键ctrl + shift + L可以快速缩进
4,特别用datagrip进行快速复制一行的时候,只需要Ctrl + D不需要关注逗号,写起来很快


















 2496
2496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











