






 本文详细介绍了Kafka,包括其起源、与LinkedIn/ApacheConfluent的关系,从消息模型(如JMS、AMQP、MQTT)到基本概念(Broker、Topic、Partition、Replication),再到生产者和消费者API、配置项、消息传递语义、序列化和常用消息格式。Kafka以其高性能、高可用性和与大数据生态的紧密集成而知名。
本文详细介绍了Kafka,包括其起源、与LinkedIn/ApacheConfluent的关系,从消息模型(如JMS、AMQP、MQTT)到基本概念(Broker、Topic、Partition、Replication),再到生产者和消费者API、配置项、消息传递语义、序列化和常用消息格式。Kafka以其高性能、高可用性和与大数据生态的紧密集成而知名。
Kafka简介
-
起源
-
LinkedIn(领英)
-
Apache
-
Confluent
-
-
简介
-
0.9.0.x 分布式消息系统
-
0.10.0.x 分布式流处理平台
-
kafka的优势
-
吞吐量高,性能好
-
伸缩性好,支持在线水平扩展
-
容错性和可靠性
-
与大数据生态紧密结合,可无缝对接hadoop、strom、spark等
-
-
-
发行版本
-
Confluent Platform
-
Cloudera Kafka
-
Hortonworks Kafka
-
消息模型
JMS
-
Java Message Service API(Java消息服务)
-
队列--点对点
-
主题--发布订阅
-
Apache ActiveMQ
AMQP
-
Advanced Message Queuing Protocol(高级消息队列协议)
-
AMQP 模型
-
队列(queues)
-
信箱(exchanges)
-
绑定(bindings)
-
-
特点:支持事务,数据一致性高,多用于银行、金融行业
-
Pivotal RabbitMQ
-
Spring AMQP与Spring JMS
MQTT
-
Message Queuing Telemetry Transport
-
广泛用于IOT(物联网)
-
为小型无声设备之间通过低带宽发送短消息而设计
基本概念
-
1、Broker 消息代理
-
2、Topic 主题,一个主题有多个分区,
-
3、Partition 分区,多个分区可以保存不同类型的消息,分区可以分布在不同的服务器(broker)上
-
保存有序的、不可变的提交日志
-
Record 消息:key - value 形式存储
-
key为空,则在多个分区轮询发送,不为空则指定分区。
-
-
每个分区都有 一个leader以及0个或者多个follower,在创建topic的时,kafka会将不同分区的leader均匀的分配在每个broker上。
-
kafka中的leader负责处理读写操作,而follower只负责副本数据的同步如果leader出现故障,其他follower会被重新选举为leader,follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中。
-
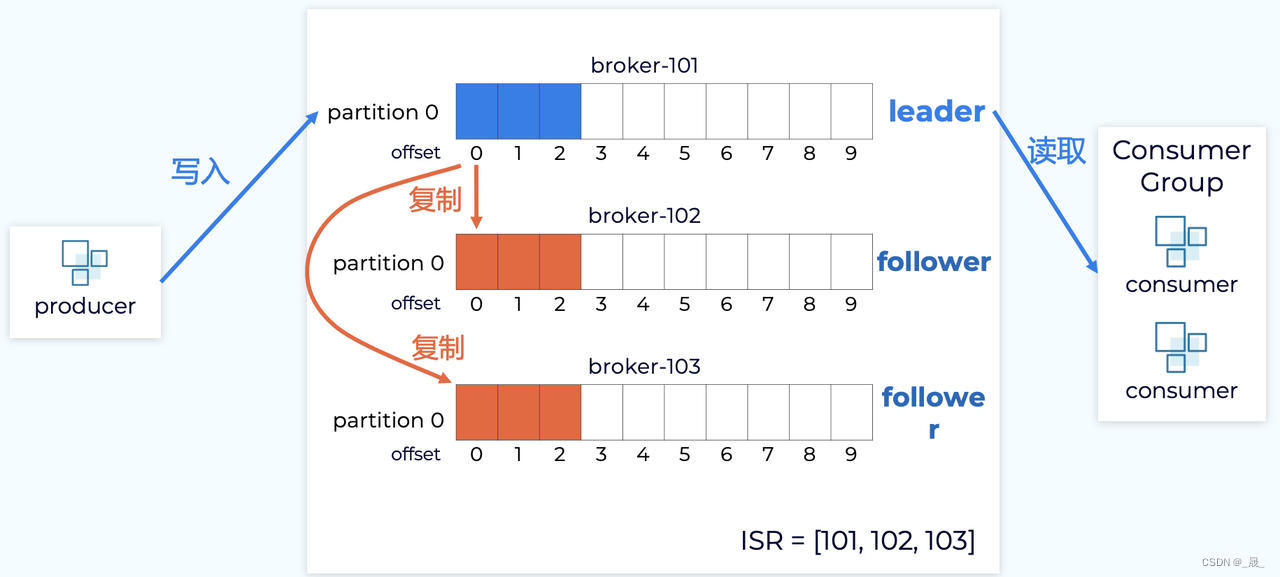
-
5、Replication 副本
-
副本与broker
-
每个分区都有一个server作为leader,0个或多个server作为follower
-
每个server 可以作为多个分区的leader和其他若干个分区的follower
-
-
-
6、Segment 段
-
7、Producer 生产者
-
生产者决定将消息发到哪个分区
-
-
8、Consumer 消费者
-
消费者通过保存offset来记录消费位置
-
-
4、Offset 偏移量
-
9、Consumer Group 消费者组
-
消费者组是消费者的一个属性,通过消费者组统一来点对点、发布订阅模式
-
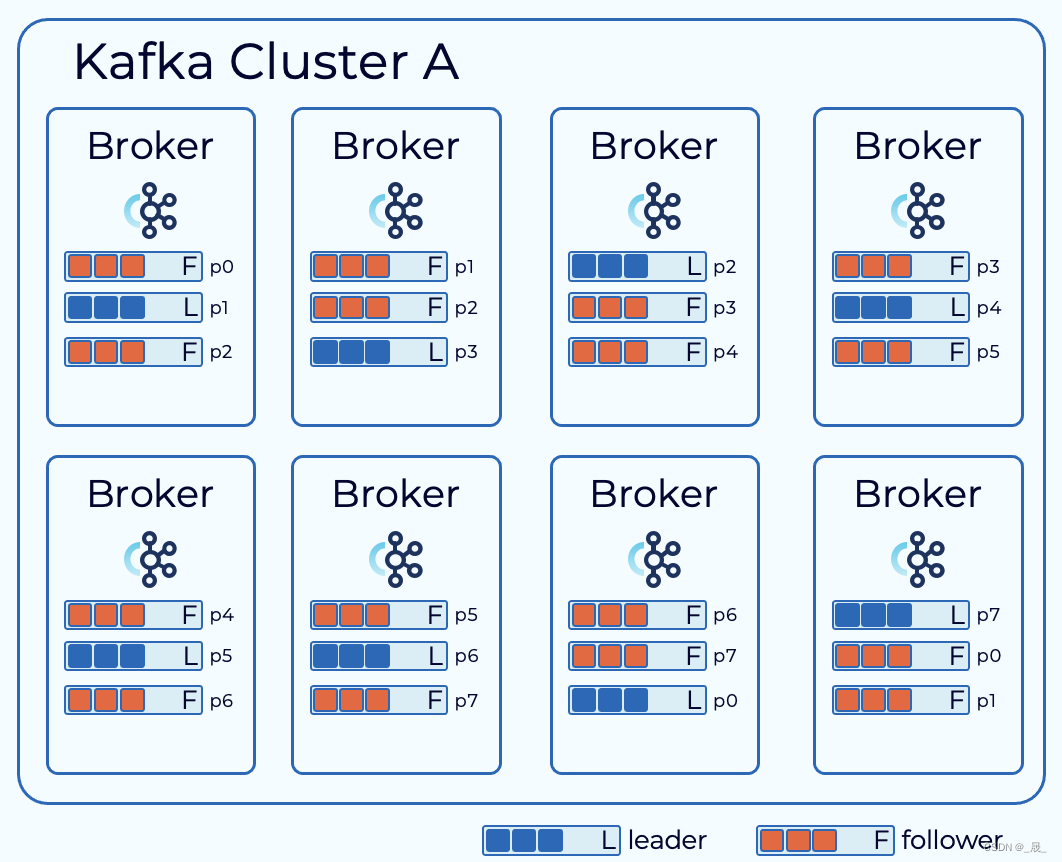
配置项
server.properties 必要配置项
-
broker.id
-
log.dirs
-
zookeeper.connect
监听器
listeners:指定broker启动时本机的监听名称,端口

监听器listeners和advertised.listeners
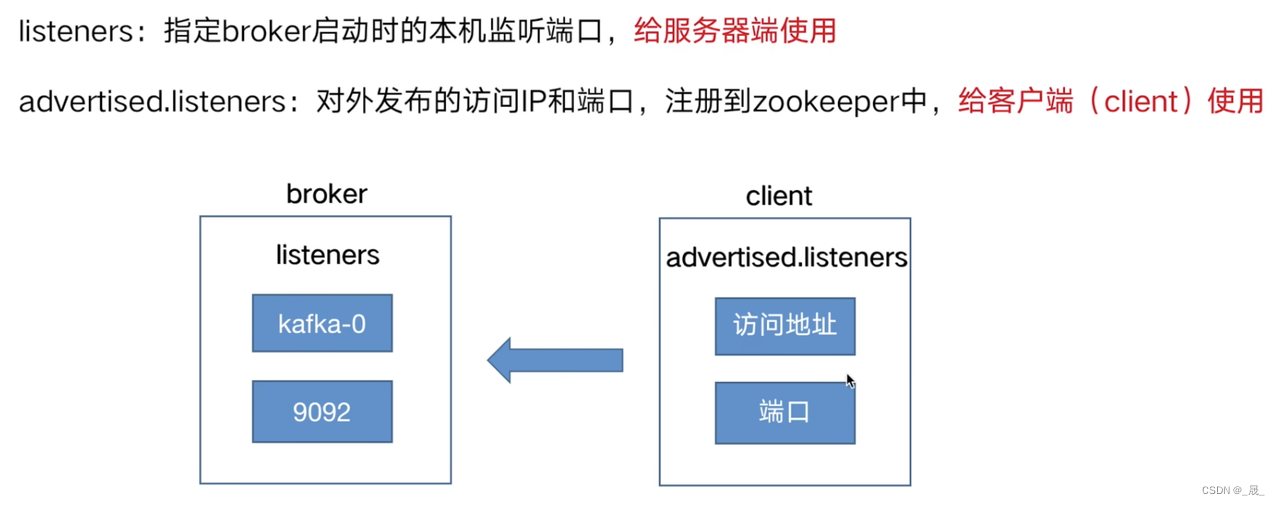
kafka消息模型
分区是最小的并行单位 一个消费者可以消费多个分区 一个分区可以被多个消费者组里的消费者消费 但是,一个分区不能同时被同一个消费者组里的多个消费者消费
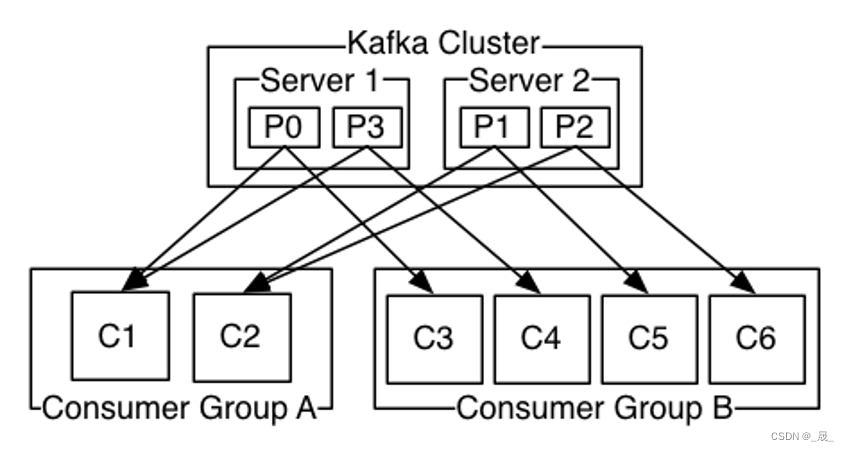
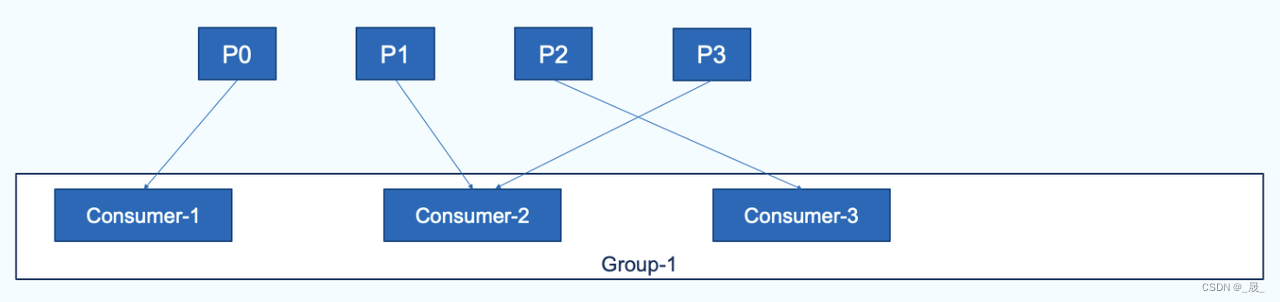
点对点
所有消费者都属于同一个消费者组
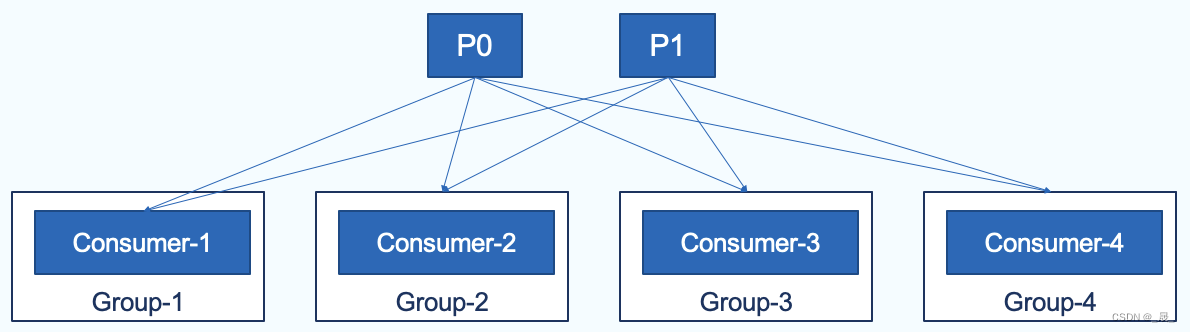
发布订阅
每个消费者都属于不同的消费者组
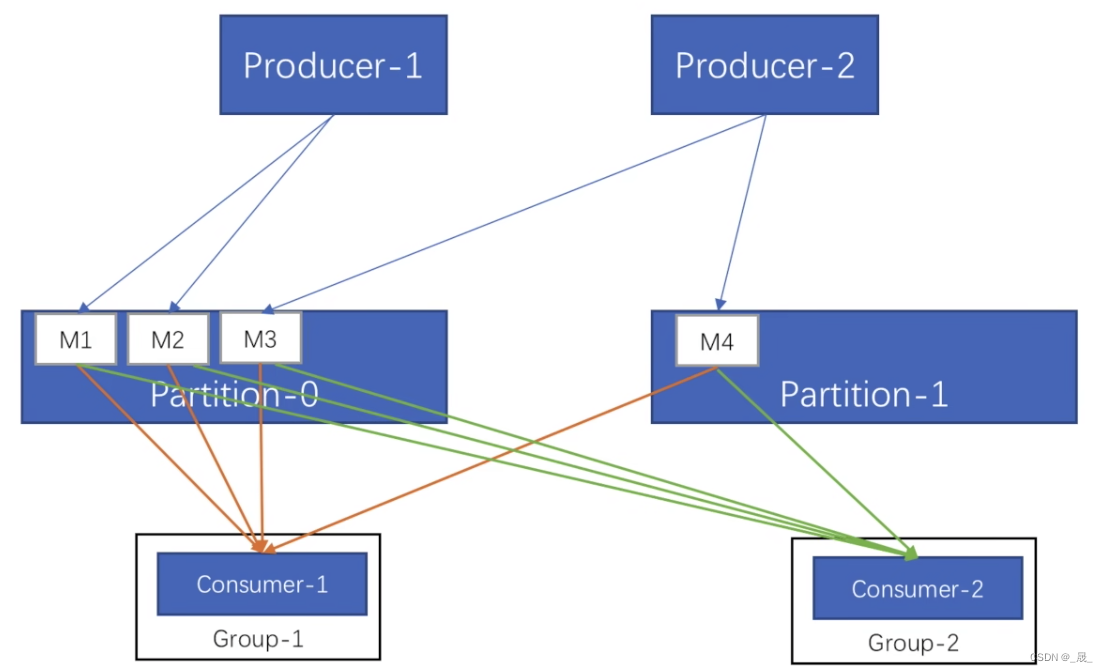
分区与消息顺序
消费者按照消息在分区里的存放顺序进行消费
kafka只保证分区内的消息顺序,不能保证分区的消息顺序
保证有序方法:
-
设置一个分区,可以保证所有消息的顺序,但是失去了拓展性和性能
-
通过设置消息的key,相同的消息会发送同一个分区
消息传递语义
-
最多一次——消息可能会丢失,永远不重复发送
-
最少一次——消息不会丢失,但是可能会重复
-
精确一次——保证消息被传递到服务端且在服务端不重复
生产者API
异步
byte[] key = "key".getBytes();
byte[] value = "value".getBytes();
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("my-topic", key, value)
producer.send(record).get();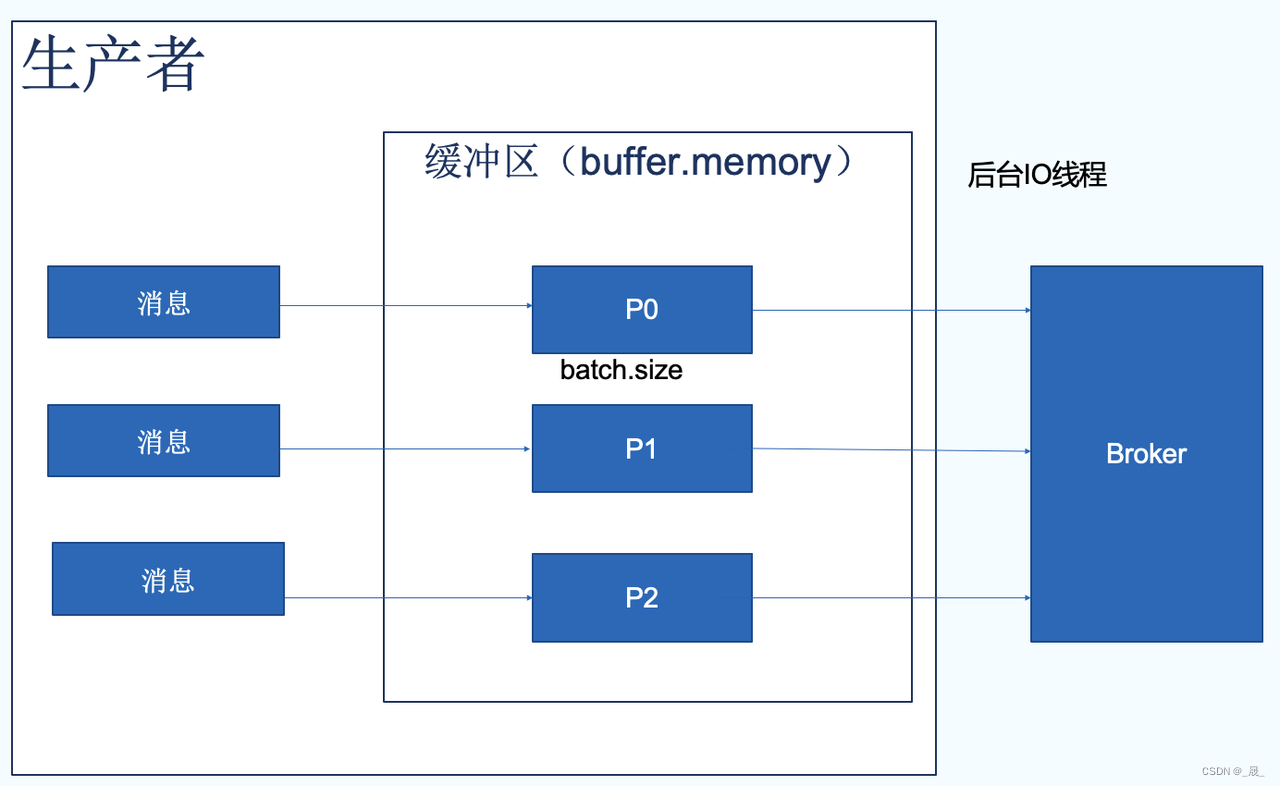
同步
Future<RecordMetadata> result =
producer.send(new ProducerRecord<String, String>("my-topic", key, value);
try {
RecordMetadata recordMetadata = result.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}批量发送
linger.ms:延迟时间
Batch.size:每一批消息最大大小
满足一个即可发送
消息确认
ack 应答机制 对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失, 所以没必要等 ISR 中的 follower 全部接收成功。 所以 Kafka 为用户提供了三种可靠性级别
acks 参数配置:
-
0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
-
1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据
-
-1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower (ISRL里的follower,不是全部的follower)全部落盘成功后才 返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复
重发消息
retries 参数配置
参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms ,可以通过retry.backoff.ms 参数来配置时间间隔。
事务
消费者API
消费者和消费位置
Kafka中有一个主题'__consumer_offsets'
用来保存消费者消费到哪个主题、哪个分区的哪个消费位置,利于快速恢复
自动提交——至多一次
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}手动提交——至少一次
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();//批量提交
buffer.clear();
}
}手动提交——逐条提交
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value()); }
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
手动指定消费分区和消费位置
指定消费分区
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));指定消费位置
seek(TopicPartition, long)
精确一次
生产者:
enable.idempotence=true
retries=Integer.MAX_VALUE
Acts=all消费者:
通常在消息中加入唯一ID,在处理业务时,通过判断ID来防止重复处理
事务
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
producer.abortTransaction();
}
producer.close();
序列化
将对象以二进制的方式在网络之间传输或者保存到文件中,并可以根据特定的规则进行还原
kafka提供了9种基本类型的序列化和反序列化,在org.apache.kafka.common.serialization包下
常用消息格式
-
CSV
-
适合简单的消息
-
-
JSON
-
可读性高
-
ElasticSearch支持好
-
-
占用空间大
-
-
序列化消息
-
Avro
-
Hadoop、Hive支持好
-
-
Protobuf
-
-
Avro与Schema
-
自定义序列化
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









