










一.动态规划
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。例如,给定三角形:
[[2],[3,4],[6,5,7],[4,1,8,3]]
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
动态规划我个人的理解是:能将一个大问题分解为一个个小问题,并且这些小问题之间有共性能重复调用。那么如何判断这道题是否可以用到动态规划,首先从底往上看,[6,5,7]对应的最小路径很明显可以看出分别是[1,1,3],那么后两层的最短路径是[7,6,10],再网上看[3,4]的最短路径也能明显看出是[9,10],那么2对应的最短路径很明显就是11。其实从这里就能看出每层分析判断的逻辑是一致的。js代码如下:
constminimumTotal = triangle => {
// es6方法填充数组
const dp = Array.of(...triangle[triangle.length - 1])
for (let i = dp.length - 2; i >= 0; i--) {
for (let j = 0; j < triangle[i].length; j++) {
// 状态转移方程
dp[j] = Math.min(dp[j], dp[j + 1]) + triangle[i][j]
}
}
return dp[0]
}二.二分查找
给定一个递增排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。例如:输入[1,3,5,6],5输出2
其实比较简单的方法就是循环判断一次,但是题目中给出排序数组,首先想到的就是二分法,二分查找也是基本算法,主要思路就是通过左右下标指针确认中间值,然后将给定值与中间值作比较判断给定值所在的区域。代码如下:
const searchInsert = (nums, target) => {
// 左指针
let left = 0
// 右指针
let right = nums.length - 1
while (left <= right) {
// 快速获取两数中间值的小技巧
const mid = left + right >>> 1
if (nums[mid] < target) {
left = mid + 1
} else if (nums[mid] > target) {
right = mid - 1
} else {
return mid
}
}
return left
}三.哈希表
给定一个已按照升序排列 的有序数组,找到两个数使得它们相加之和等于目标数。函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。说明:返回的下标值(index1 和 index2)不是从零开始的。你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
示例:
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
这类题目如果不通过哈希表计算,最简单粗暴的就是嵌套两层循环,但是利用哈希表查找,一个for循环就能搞定。当然看到有序数组同样可以通过二分法双指针查找,哈希表实现代码如下:
const twoSum = (numbers, target) => {
let map = {}
for(let i = 0; i < numbers.length; i ++) {
const dim = target - numbers[i]
if(map[dim] === undefined) {
map[numbers[i]] = i
}else {
return [map[dim] + 1,i + 1]
}
}
};四.递归
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
输入: [4, 6, 7, 7]
输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
也许首先会想到常规的双层循环遍历,代码如下:
const findSubsequences = nums => {
const arr = []
let left = 0
for(let i = 0; i < nums.length; i++) {
const res = []
res.push(nums[i])
for(let j = i + left + 1; j < nums.length; j++) {
if(res[res.length - 1] <= nums[j]) {
res.push(nums[j])
arr.push(res.slice())
}
}
left = 0
}
return arr
}但是结果为[ [ 4, 6 ],[ 4, 6, 7 ],[ 4, 6, 7, 7 ],[ 6, 7 ],[ 6, 7, 7 ],[ 7, 7 ] ]
显然不符合正确输出,因为每个数字可以选择选或者不选,那么该如何改进呢,我这里想到的办法是,将res定义为一个二位数组,然后加一层for循环,代码如下:
const findSubsequences = nums => {
const arr = []
const set = new Set()
let left = 0
for(let i = 0; i < nums.length; i++) {
const res = []
res.push([nums[i]])
for(let j = i + left + 1; j < nums.length; j++) {
const copyRes = res.slice()
for(const k of copyRes) {
if(k[k.length - 1] <= nums[j]) {
const newArray = k.slice()
newArray.push(nums[j])
res.push(newArray)
// 去重
const str = newArray.join(',')
if (!set.has(str)) {
arr.push(newArray)
set.add(str)
}
}
}
}
left = 0
}
return arr
}输出:[ [ 4, 6 ],[ 4, 7 ],[ 4, 6, 7 ],[ 4, 7, 7 ],[ 4, 6, 7, 7 ],[ 6, 7 ],[ 6, 7, 7 ],[ 7, 7 ] ]。结果输出正确,但是O(n3)复杂度显然不够好,其实在做这道题过程中发现可以通过dp动态规划来做,代码如下:
const findSubsequences = nums => {
const dp = new Array(nums.length)
const set = new Set()
dp[0] = [[nums[0]],[]]
for(let i = 1; i < nums.length; i++) {
if(nums[i] >= nums[i - 1]) {
const s = []
for(const j of dp[i - 1]) {
const item = j.slice()
item.push(nums[i])
const str = item.join(',')
if (!set.has(str)) {
s.push(item)
set.add(str)
}
}
dp[i] = [...dp[i - 1].slice(),...s]
}
}
return dp[dp.length - 1].filter(item => item.length >= 2)
}大致思路是,每个数字有选与不选,转移方程为dp[i] = dp[i -1] + s,当当前数大于之前的数字,s为当前值push到每个dp[i - 1]数组,如果小于上一个数组,那么dp[i] = dp[i -1]。这种算法还有个问题,即dp为一个三维数组,其实可以进行降维处理,代码如下:
const findSubsequences2 = nums => {
let dp = [[nums[0]],[]]
const set = new Set()
for(let i = 1; i < nums.length; i++) {
if(nums[i] >= nums[i - 1]) {
const s = []
for(const j of dp) {
const item = j.slice()
item.push(nums[i])
const str = item.join(',')
if (!set.has(str)) {
s.push(item)
set.add(str)
}
}
dp = [...dp,...s]
}
}
return dp.filter(item => item.length >= 2)
}现在dp即为一个二位数组,降低了空间复杂度。
好了,其实从题目中很容易看出,这是一道回溯算法的问题,采用递归能很快地解决该问题,代码如下:
const findSubsequences = nums => {
const res = []
const len = nums.length
const set = new Set()
const dfs = (start, path) => {
if (path.length >= 2) {
const str = path.join(',')
if (!set.has(str)) {
res.push(path.slice())
set.add(str)
}
}
for (let i = start; i < len; i++) {
const prev = path[path.length - 1]
const cur = nums[i]
if (path.length === 0 || prev <= cur) {
path.push(cur)
dfs(i + 1, path)
path.pop()
}
}
}
dfs(0, [])
return res
}通过递归加pop回溯,十分简单清晰的解决了该问题。
最后再提一句,该题目去重到目前为止都是用的hash去重的方法,使用该方法达到剪枝,减少不必要的代码运行。
五.欧拉路径
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。
说明:
如果存在多种有效的行程,你可以按字符自然排序返回最小的行程组合。例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前
所有的机场都用三个大写字母表示(机场代码)。
假定所有机票至少存在一种合理的行程。
示例 1:
输入: [['JFK','SFO'],['JFK','ATL'],['SFO','ATL'],['ATL','JFK'],['ATL','SFO']]
输出: [ 'JFK', 'SFO', 'ATL', 'JFK', 'ATL', 'SFO' ]
其实,通过看过四就知道,这道题也可以通过回溯+递归解决,和捉迷藏一样,如果走不下去,回到上一步,具体代码如下:
const findItinerary = tickets => {
const res = ['JFK']
const map = {}
let count = tickets.length
for(const i of tickets) {
const [from,to] = i
map[from] ? (map[from].push(to)) : (map[from] = [to])
}
const dfs = city => {
if(count === 0) {
return true
}
const nextCity = map[city]
if(!map[city] || map[city].length === 0) {
return false
}
for(let i = 0; i < nextCity.length; i++) {
const next = nextCity[i]
nextCity.splice(i, 1)
res.push(next)
--count
if(dfs(next)) {
return true
}else {
nextCity.splice(i, 0, next)
res.pop()
++count
}
}
}
dfs(res[0])
return res
}其实和四的解题思路类似,接下来说下欧拉路径,什么是欧拉路径?欧拉路径:欧拉路是指从图中任意一个点开始到图中任意一个点结束的路径,并且图中每条边通过的且只通过一次。类似有个欧拉回路,欧拉回路:欧拉回路是指起点和终点相同的欧拉路。
显然这道题是肯定存在欧拉路径的,那么如何解决欧拉路径呢,先看下代码:
const findItinerary = tickets => {
const res = []
const map = {}
for(const i of tickets) {
const [from,to] = i
map[from] ? (map[from].push(to)) : (map[from] = [to])
}
const dfs = node => {
const nextNodes = map[node]
if(nextNodes) {
while (nextNodes.length) {
const next = nextNodes.shift()
dfs(next)
}
}
res.unshift(node)
}
dfs('JFK')
return res
}是不是看代码比回溯简单很多?其实这里用到了hierholzer算法,
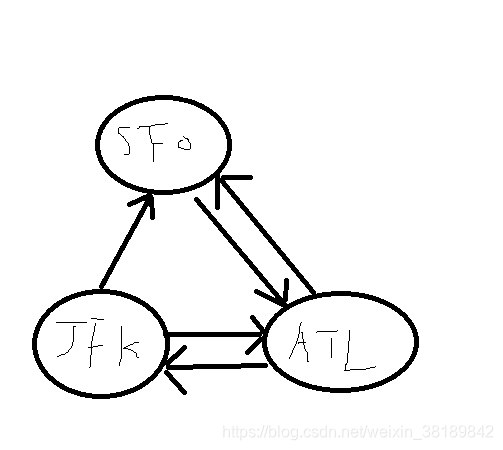
如图,只要一笔画完就可以,如果路线是JFK -> SFO -> ALT -> SFO的话,
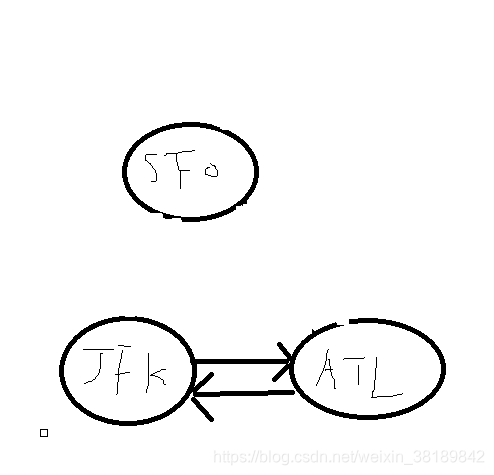
这个时候递归到SFO节点,发现没有线了,将SFO推入res,以此类推,结果就是[ 'JFK', 'SFO', 'ATL', 'JFK', 'ATL', 'SFO' ],有可能会有疑问,为什么没有线了,就可以把该节点推入res,至于hierholzer实现原理是什么。
这里先说下欧拉路径的存在性判断:
无向图存在欧拉回路的判断条件:除2个端点外其余节点入度=出度;1个端点入度比出度大1;一个端点入度比出度小1 。
有向图G存在欧拉回路的判断条件:G中恰有两个奇数度顶点。
通过这个判断条件,很容易可以得到,最先推入res节点的必定为除了起点对的奇数点,因为只有奇数点,当再次进入该点时,才会知道周边没有线了,即入度比出度大一。找到了终点,只要不停网上回溯就行了,因为除了起点和顶点,其余节点都是入度=出度。这就是该算法的原理。
六.二叉树遍历
(1)前序遍历
a、访问根节点;b、前序遍历左子树;c、前序遍历右子树。
(2)中序遍历
a、中序遍历左子树;b、访问根节点;c、中序遍历右子树。
(3)后序遍历
a、后序遍历左子树;b、后续遍历右子树;c、访问根节点。
mock二叉树,接下来每个节点结构如下
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }中序遍历:
var inorderTraversal = function(root) {
const array = []
const getNode = function(node) {
if(!node) {
return false
}
node.left && getNode(node.left)
array.push(node.val)
node.right && getNode(node.right)
}
getNode(root)
return array
};前序排序:
var preorderTraversal = function(root) {
const array = []
const getNode = function(node) {
if(!node) {
return false
}
array.push(node.val)
node.left && getNode(node.left)
node.right && getNode(node.right)
}
getNode(root)
return array
};后序排序:
var postorderTraversal = function(root) {
const array = []
const getNode = function(node) {
if(!node) {
return false
}
node.left && getNode(node.left)
node.right && getNode(node.right)
array.push(node.val)
}
getNode(root)
return array
};七.二叉搜索树
给定一棵二叉搜索树,请找出其中第k大的节点。
二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。二叉搜索树作为一种经典的数据结构,它既有链表的快速插入与删除操作的特点,又有数组快速查找的优势;所以应用十分广泛,例如在文件系统和数据库系统一般会采用这种数据结构进行高效率的排序与检索操作。
实现代码如下:
const kthLargest = function(root, k) {
const array = []
const getNode = function(node) {
if(!node) {
return false
}
node.right && getNode(node.right)
array.push(node.val)
node.left && getNode(node.left)
}
getNode(root)
return array[k - 1]
}根据二叉搜索树的定义,可以通过中序排序,找到对应的第k大节点,但是,其实没有必要把所有的节点都排序,优化写法如下:
const kthLargest = function(root, k) {
let num = k
let val = 0
const getNode = function(node) {
if(!node) {
return false
}
node.right && getNode(node.right)
--num
if(num === 0) {
val = node.val
return false
}
node.left && getNode(node.left)
}
getNode(root)
return val
}主要也是通过中序,但是当num为0时直接返回。不用接下来计算。

















 2542
2542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









