







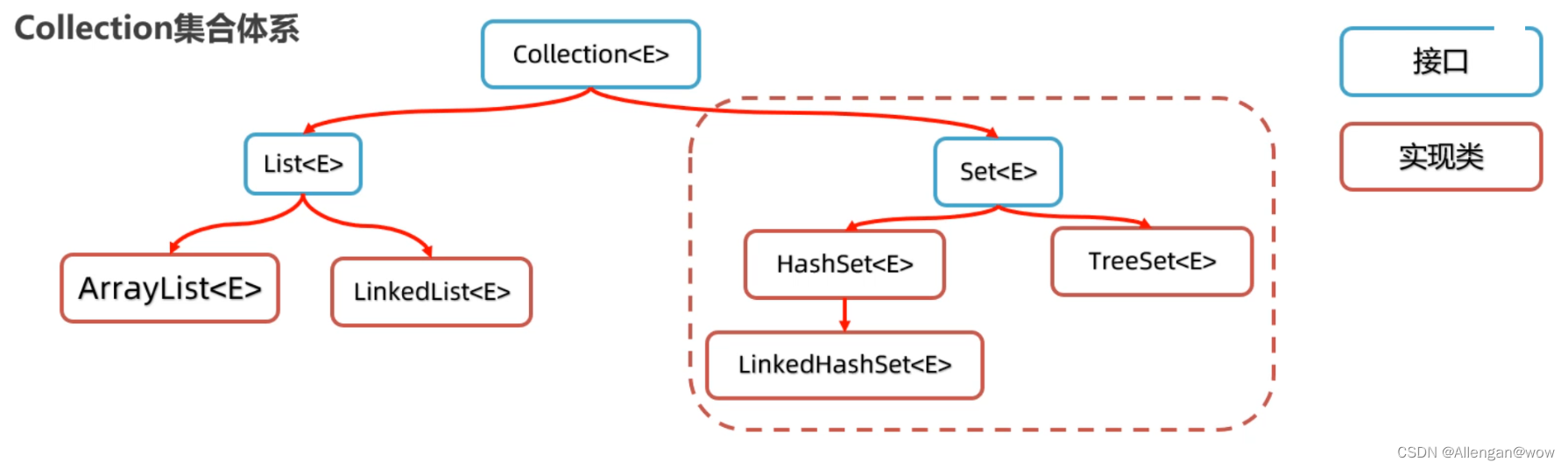
Collection集合体系
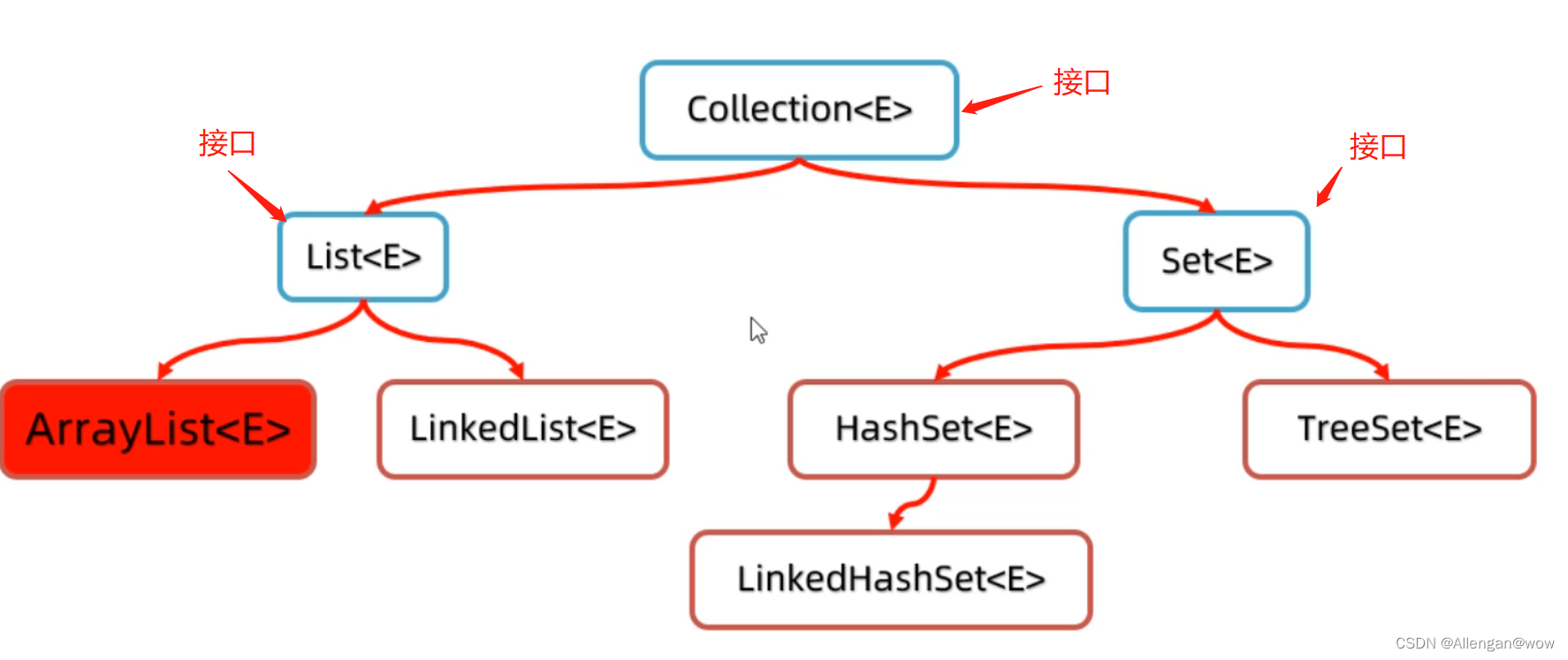
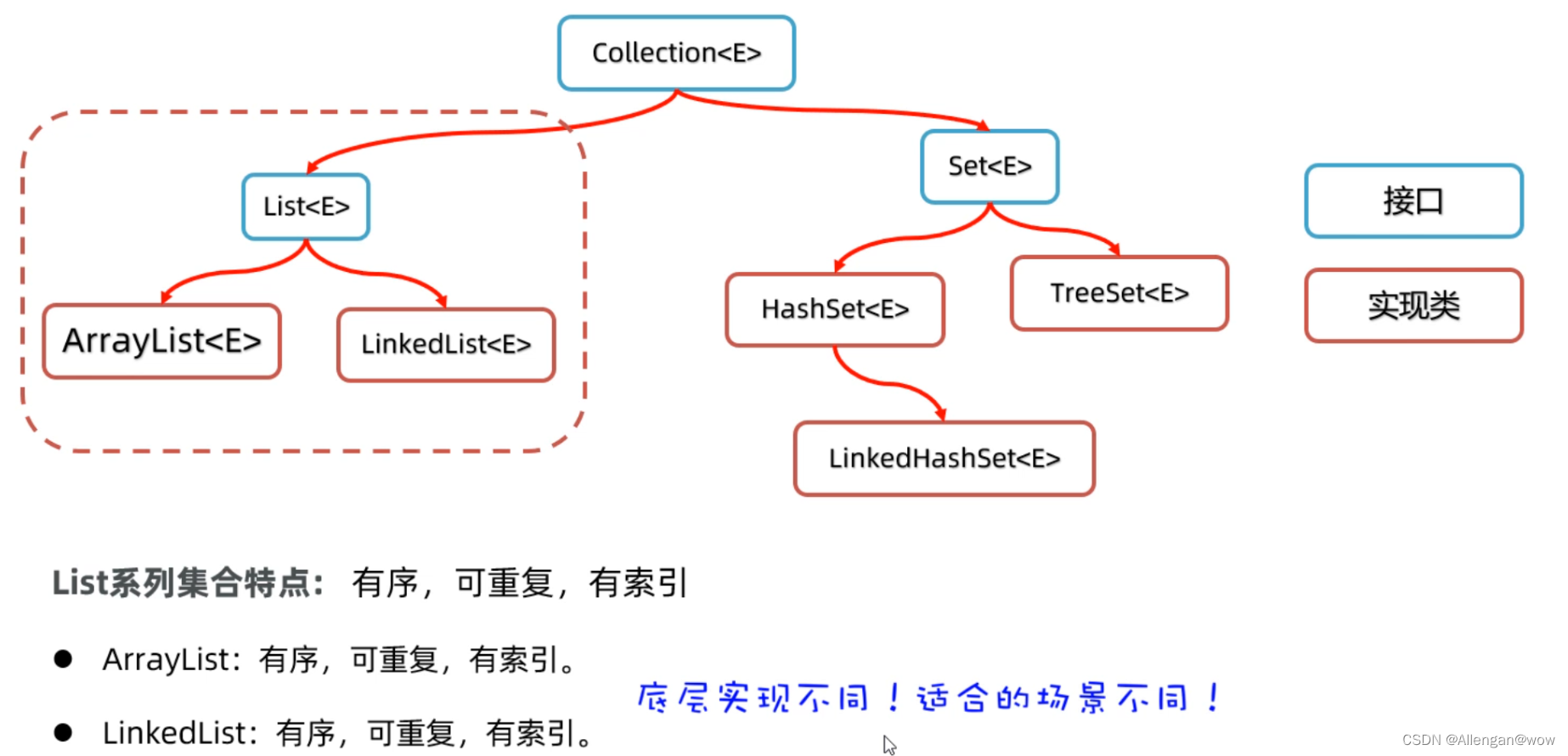
List系列集合:存取有序、可重复、有索引
ArrayList
LinekdList
Set系列集合:存取无序、不重复、无索引
HashSet
LinkedHashSet: 存取有序
TreeSet:排序
//简单确认一下Collection集合的特点
ArrayList<String> list = new ArrayList<>(); //存取顺序一致,可以重复,有索引
list.add("java1");
list.add("java2");
list.add("java1");
list.add("java2");
System.out.println(list); //[java1, java2, java1, java2]
HashSet<String> list = new HashSet<>(); //存取顺序不一致,不重复,无索引
list.add("java1");
list.add("java2");
list.add("java1");
list.add("java2");
list.add("java3");
System.out.println(list); //[java3, java2, java1] 1、单列集合的顶层接口是?双列集合的顶层接口是?存储元素的特点是?
Collection,每个元素只包含一个值
Map,每个元素包含两个值,元素也称为键值对
2、Collection有哪两大体系,各自的特点是?
List系列集合:存取有序、可重复、有索引
Set系列集合:存取无序、不重复、无索引
Collection的常用方法
| 方法名 | 说明 |
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数。 |
| public Object[] toArray() | 把集合中的元素,存储到数组中 |
import java.util.ArrayList;
import java.util.Collection;
public class Test04 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("张三");
collection.add("王五");
collection.add("赵六");
collection.add("钱七");
collection.remove("张三");//删除
collection.contains("张三");//判断集合中是否包含某个元素
collection.clear();//清除所有元素
System.out.println(collection.size());//判断集合中有多少个元素;
Object[] array = collection.toArray();//将集合转换成一个数组;
}
}将一个集合添加到另一个集合中;
Collection<String> c1 = new ArrayList<>();
c1.add("java1");
c1.add("java2");
Collection<String> c2 = new ArrayList<>();
c2.add("java3");
c2.add("java4");
c1.addAll(c2); //把c2集合中的全部元素,添加到c1集合中去
System.out.println(c1); //[java1, java2, java3, java4]Collection遍历方式
为什么Collection集合不能用普通for循环遍历
因为Collection中没有get方法,多态创建对象,编译报错;
迭代器遍历
迭代器是用来遍历单例集合的专用方式(数组没有迭代器),在Java中迭代器的代表是Iterator。
| 方法名称 | 说明 |
| Iterator<E> iterator() | 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的第一个元素 |
迭代器Iterator常用方法
| 方法名称 | 说明 |
| boolean hasNext() | 询问当前位置是否有元素存在,存在返回true ,不存在返回false |
| E next() | 获取当前位置的元素,并同时将迭代器对象指向下一个元素处。 |
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Test05 {
public static void main(String[] args) {
Collection<Object> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
list.add("ee");
Iterator<Object> iterator = list.iterator();
while (iterator.hasNext()){//判断是否有元素
System.out.println(iterator.next());//取出元素并将索引指向下一个
}
}
}迭代器代码的原理如下:
-
当调用iterator()方法获取迭代器时,当前指向第一个元素
-
hasNext()方法则判断这个位置是否有元素,如果有则返回true,进入循环
-
调用next()方法获取元素,并将索引指向下一个位置,
-
等下次循环时,则获取下一个元素,依此内推
1、如何获取集合的迭代器? 迭代器遍历集合的代码具体怎么写?
通过集合对象名,调用iterator()方法获取迭代器对象 循环判断语句中调用hasNext()方法,该方法判断当前位置是否有元素可以取出,如果有则调用next()方法取出,并让迭代器后移一位;如果没有循环结束
2、hasNext()方法结果为false,如果继续使用next()方法会出现什么异常?
NoSuchElementException异常
增强for遍历集合
增强for循环不仅可以遍历集合还可以遍历数组
for(Object o:s){
System.out.println(o)
}
//Object表示集合的类型,o代表集合中的每一个元素,s代表集合;
Collection<String> c = new ArrayList<>();
c.add("赵敏");
c.add("小昭");
c.add("素素");
c.add("灭绝");
//1.使用增强for遍历集合
for(String s: c){
System.out.println(s);
}
//2.再尝试使用增强for遍历数组
String[] arr = {"迪丽热巴", "古力娜扎", "稀奇哈哈"};
for(String name: arr){
System.out.println(name);
}反编译可以看出增强for底层调用迭代器

forEach遍历集合
在JDK8版本以后还提供了一个forEach方法也可以遍历集合,如果下图所示:
| 方法名称 | 说明 |
| default void forEach(Consumer<? super T> action) | 结合lambda遍历集合 |
public class Demo06 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("张无忌");
collection.add("谢逊");
collection.add("周芷若");
collection.add("小昭");
collection.add("张三丰");
collection.forEach(new Consumer<String>() {//匿名内部类
@Override
public void accept(String s) {
System.out.println(s);
}
});
collection.forEach(System.out::println);//Lambda表达式进行简化
}
}public class Movie{
private String name; //电影名称
private double score; //评分
private String actor; //演员
//无参数构造方法
public Movie(){}
//全参数构造方法
public Movie(String name, double score, String actor){
this.name=name;
this.score=score;
this.actor=actor;
}
//...get、set、toString()方法自己补上..
}public class Test{
public static void main(String[] args){
Collection<Movie> movies = new ArrayList<>();
movies.add(new MOvie("《肖申克的救赎》", 9.7, "罗宾斯"));
movies.add(new MOvie("《霸王别姬》", 9.6, "张国荣、张丰毅"));
movies.add(new MOvie("《阿甘正传》", 9.5, "汤姆汉克斯"));
for(Movie movie : movies){
System.out.println("电影名:" + movie.getName());
System.out.println("评分:" + movie.getScore());
System.out.println("主演:" + movie.getActor());
}
}
}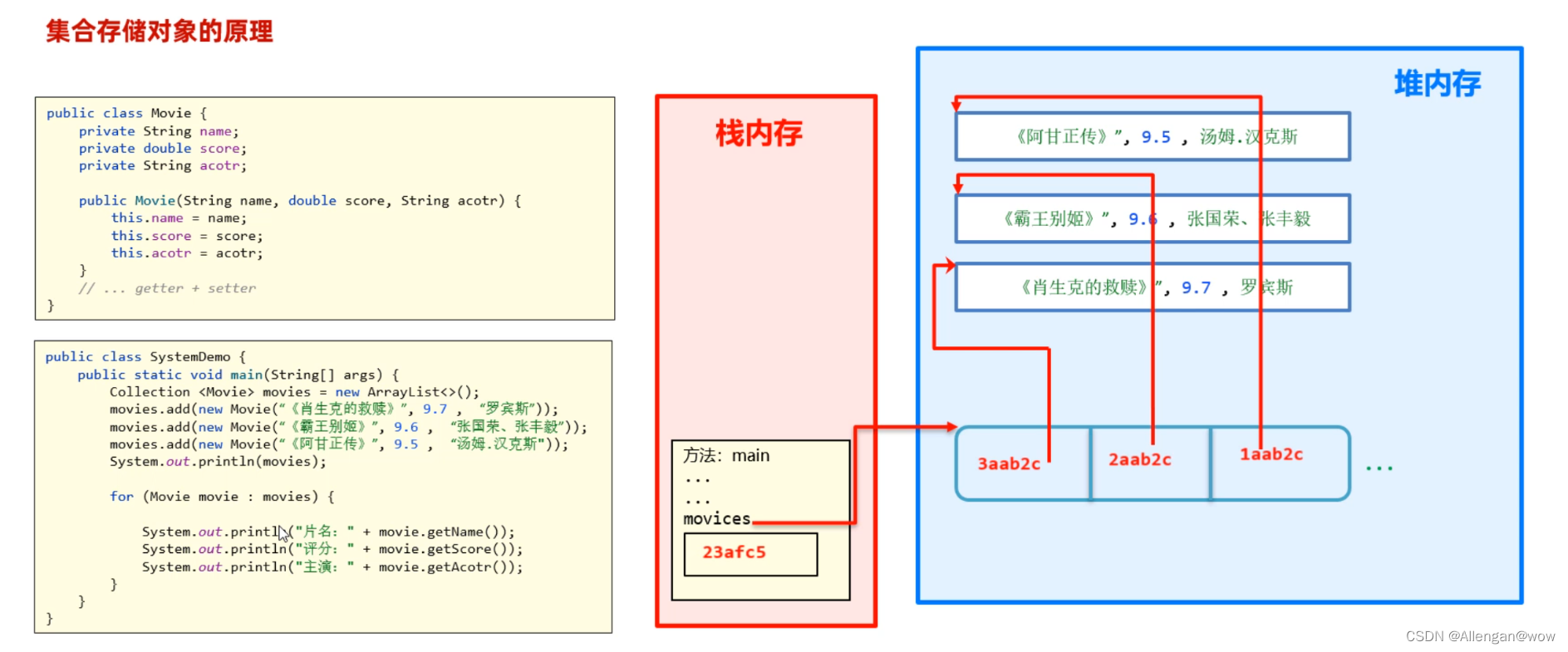
集合中存储的是元素对象的地址
List系列集合
List集合的常用方法
List集合因为支持索引,所以多了很多与索引相关的方法,当然,Collection的功能List也都继承了。
| 方法名称 | 说明 |
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
//1.创建一个ArrayList集合对象(有序、有索引、可以重复)
List<String> list = new ArrayList<>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("至尊宝");
list.add("牛夫人");
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
//2.public void add(int index, E element): 在某个索引位置插入元素
list.add(2, "紫霞仙子");
System.out.println(list); //[蜘蛛精, 至尊宝, 紫霞仙子, 至尊宝, 牛夫人]
//3.public E remove(int index): 根据索引删除元素, 返回被删除的元素
System.out.println(list.remove(2)); //紫霞仙子
System.out.println(list);//[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
//4.public E get(int index): 返回集合中指定位置的元素
System.out.println(list.get(3));
//5.public E set(int index, E e): 修改索引位置处的元素,修改后,会返回原数据
System.out.println(list.set(3,"牛魔王")); //牛夫人
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛魔王]List集合支持的遍历方式
for循环(因为List集合有索引)
iterator迭代器
增强for循环
Lambda表达式(foreach)
List<String> list = new ArrayList<>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("糖宝宝");
//1.普通for循环
for(int i = 0; i< list.size(); i++){
//i = 0, 1, 2
String e = list.get(i);
System.out.println(e);
}
//2.增强for遍历
for(String s : list){
System.out.println(s);
}
//3.迭代器遍历
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
//4.lambda表达式遍历
list.forEach(s->System.out.println(s));ArrayList底层的原理
基于数组实现的
- 查询速度快(注意:根据索引查询数据快):查询数据通过索引直接定位,查询任意数据耗时相同
- 删除效率低:需要把后面很多的数据进行前移
- 添加效率极低:需要把后面很多的数据后移,再添加元素。也可能需要进行数组扩容
我们知道数组的长度是固定的,但是集合的长度是可变的,这是怎么做到的呢?原理如下:

elementData是底层代码中arraylist创建对象时创建的空数组;
LinkedList底层原理
LinkedList底层是链表结构,链表结构是由一个一个的节点组成,一个节点由数据值、下一个元素的地址组成。如下图所示
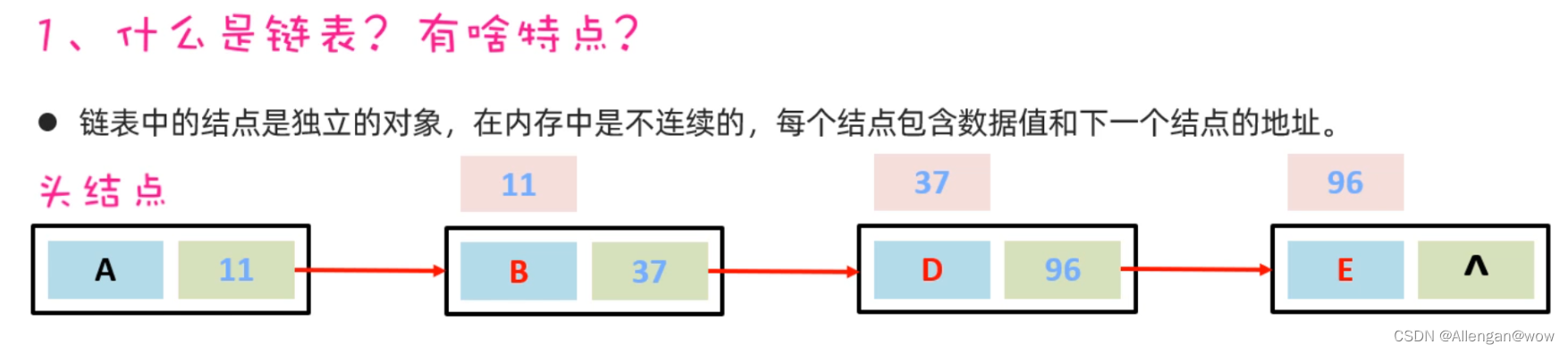
- 查询慢,无论查询那个都需要从头开始;
- 增删相对于arraylist比较快;
假如,现在要在B节点和D节点中间插入一个元素,只需要把B节点指向D节点的地址断掉,重新指向新的节点地址就可以了。如下图所示:
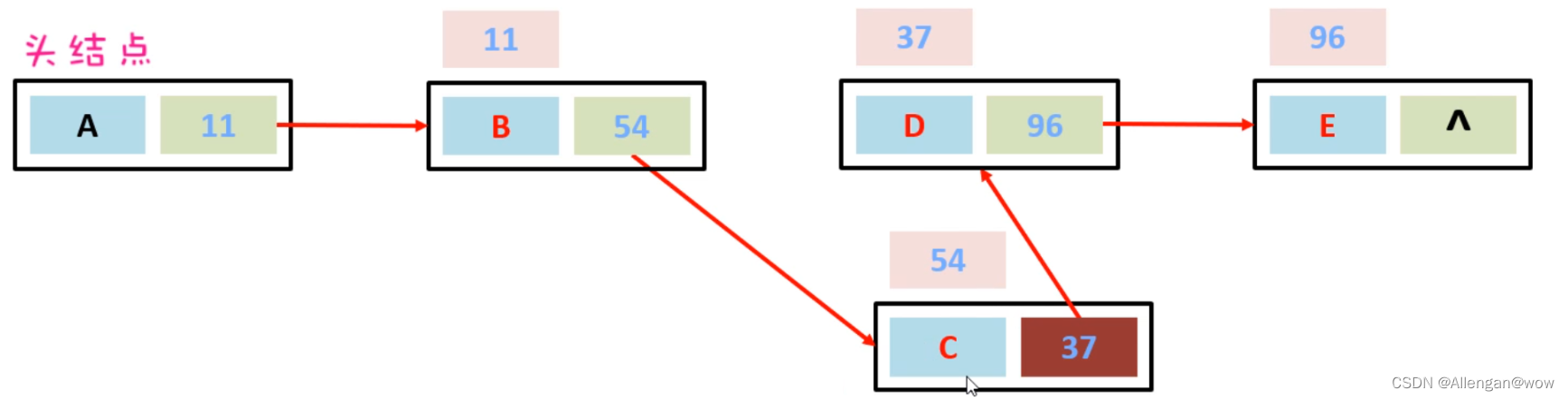
假如,现在想要把D节点删除,只需要让C节点指向E节点的地址,然后把D节点指向E节点的地址断掉。此时D节点就会变成垃圾,会把垃圾回收器清理掉。
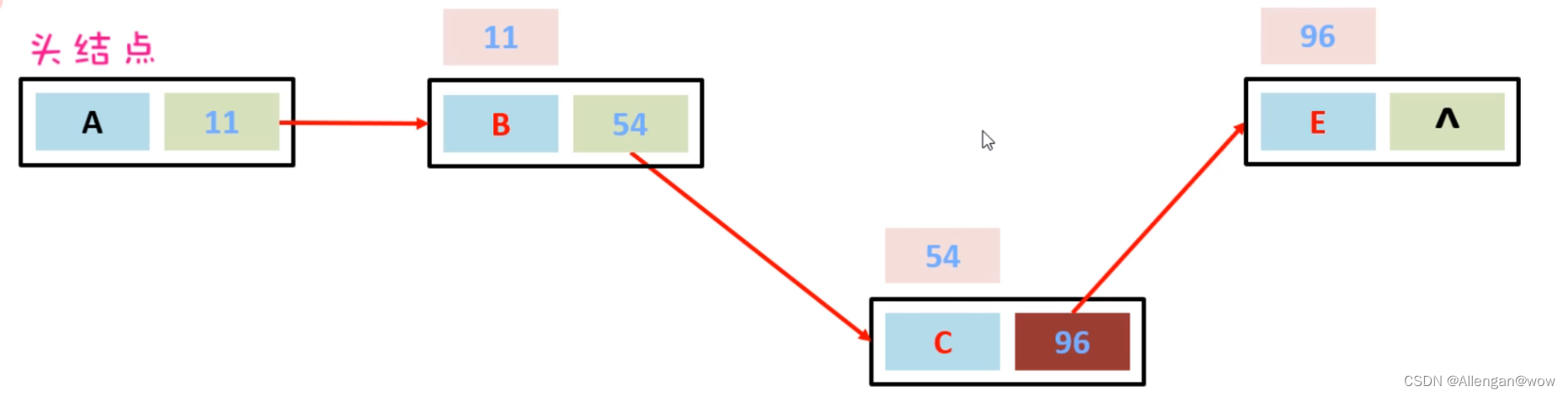
上面的链表是单向链表,它的方向是从头节点指向尾节点的,只能从左往右查找元素,这样查询效率比较慢;还有一种链表叫做双向链表,不光可以从做往右找,还可以从右往左找。如下图所示: 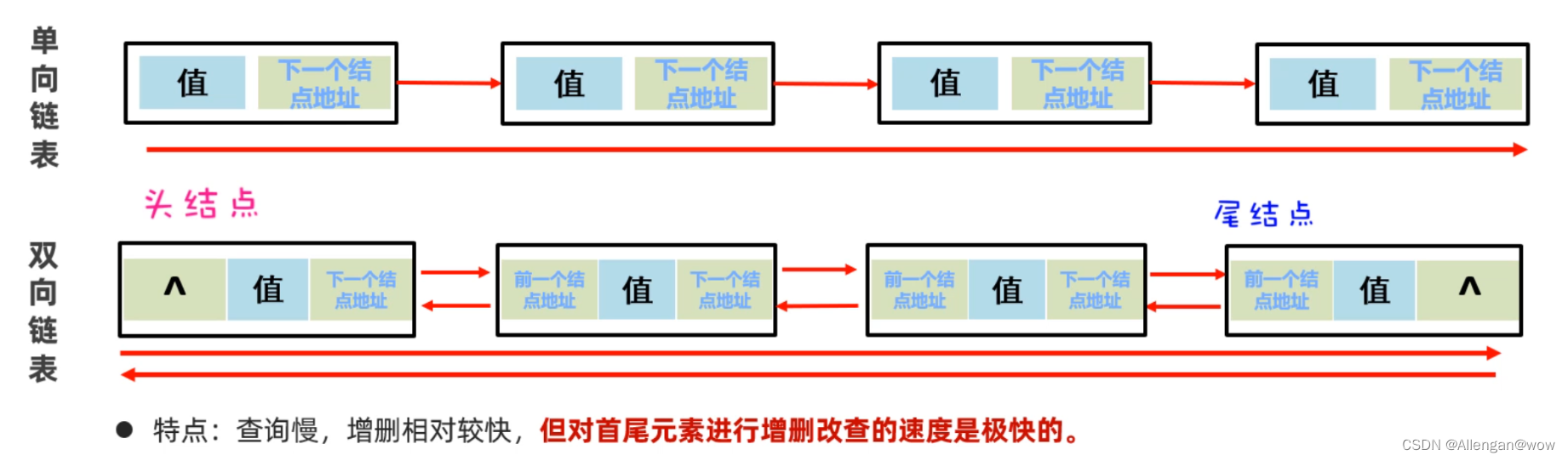
LinkedList新增了:很多首尾操作的特有方法。
| 方法名称 | 说明 |
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
LinkedList集合的应用场景
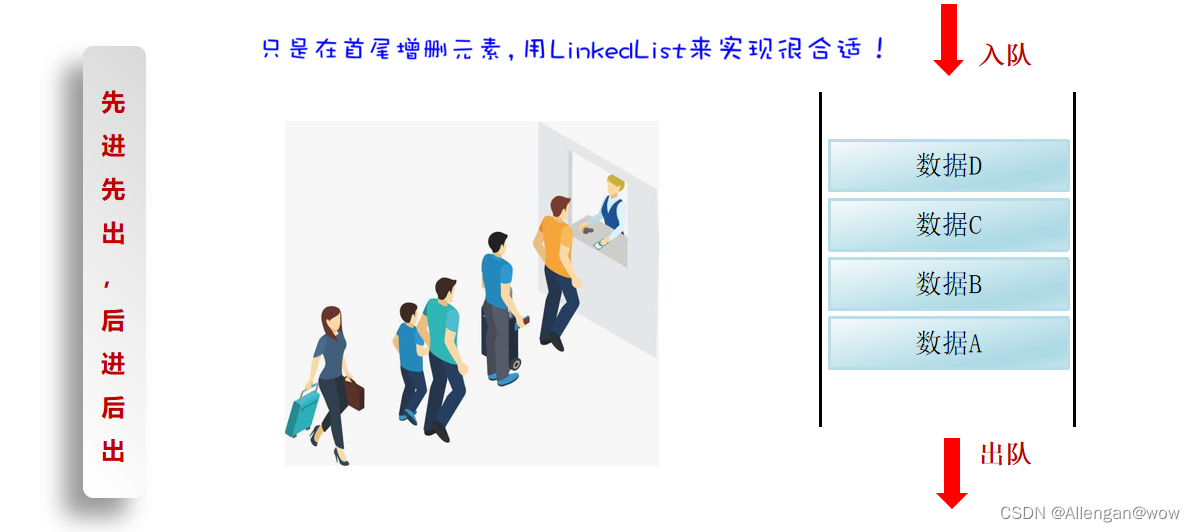
LInkedList集合有什么用呢?可以用它来设计栈结构、队列结构。
队列结构,队列结构你可以认为是一个上端开口,下端也开口的管子的形状。元素从上端入队列,从下端出队列。
package com.itcast.test;
import java.util.LinkedList;
public class Demo06 {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
//进队列
linkedList.add("000");
linkedList.add("111");
linkedList.add("222");
linkedList.addLast("aaa");
linkedList.addLast("bbb");
linkedList.addLast("ccc");
linkedList.addLast("ddd");
System.out.println(linkedList);
//出队列
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeFirst());
System.out.println(linkedList);
}
}
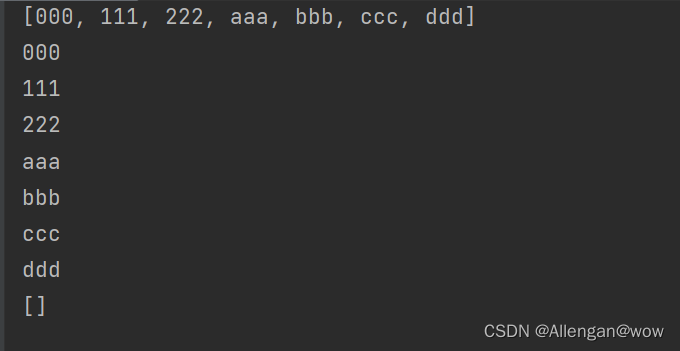
队结构先进先出
用LinkedList集合来模拟一下栈结构的效果。还是先来认识一下栈结构长什么样。栈结构可以看做是一个上端开头,下端闭口的水杯的形状。
元素永远是上端进,也从上端出,先进入的元素会压在最底下,所以栈结构的特点是先进后出,后进先出

package com.itcast.test;
import java.util.LinkedList;
public class Demo07 {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
linkedList.push("第一颗子弹");//相当于addFirst
linkedList.push("第二颗子弹");//相当于addFirst
linkedList.push("第三颗子弹");//相当于addFirst
linkedList.push("第四颗子弹");//相当于addFirst
linkedList.push("第五颗子弹");//相当于addFirst
linkedList.push("第六颗子弹");//相当于addFirst
linkedList.push("第七颗子弹");//相当于addFirst
System.out.println(linkedList);
System.out.println(linkedList.pop());//相当于removeFirst
System.out.println(linkedList.pop());
System.out.println(linkedList.pop());
System.out.println(linkedList.pop());
System.out.println(linkedList.pop());
System.out.println(linkedList.pop());
System.out.println(linkedList.pop());
System.out.println(linkedList);
}
}
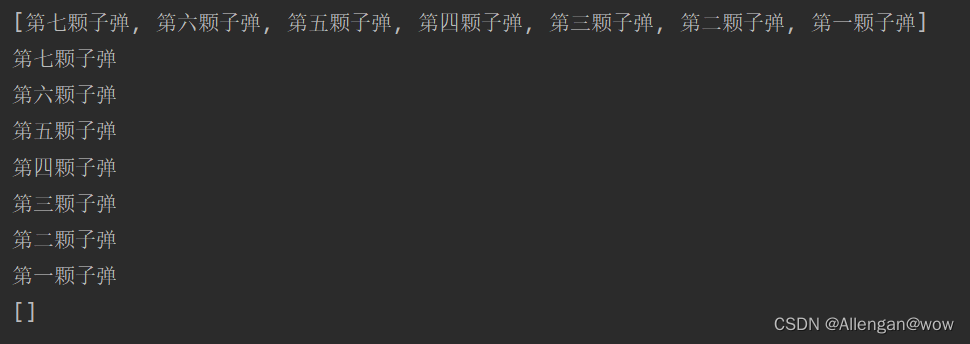
1、LinkedList集合的底层是基于什么实现的?有什么特点?
基于双链表实现的 查询慢,增删相对较快,但对首、尾元素进行增删改查的速度是极快的
2、LinkedList集合适合什么业务场景?
设计队列、设计栈。有专门对首、尾元素进行操作的方法
set集合
set集合的特点
Set集合是属于Collection体系下的另一个分支,它的特点如下图所示
Set集合特点:
- 无序
- 不重复
- 无索引
注意: Set要用到的常用方法,基本上就是Collection提供的!! 自己几乎没有额外新增一些常用功能!
package com.itcast.prepare;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
public class Demo01 {
public static void main(String[] args) {
Set<String> set1 = new HashSet<>();//无序 无索引 无重复
set1.add("aaa");
set1.add("bbb");
set1.add("ccc");
set1.add("aaa");
set1.add("aaa");
set1.add("ddd");
set1.add("ddd");
System.out.println(set1);
System.out.println("--------------------------");
Set<String> set2 = new LinkedHashSet<>();//有序 无索引 无重复
set2.add("aaa");
set2.add("bbb");
set2.add("aaa");
set2.add("aaa");
set2.add("ccc");
set2.add("ddd");
System.out.println(set2);
System.out.println("--------------------------------");
Set<String> set3 = new TreeSet<>();//可排序(升序) 无索引 无重复
set3.add("aaaaaa");
set3.add("bbb");
set3.add("ccc");
set3.add("bbb");
set3.add("bbbbbbb");
set3.add("ddd");
System.out.println(set3);
}
}
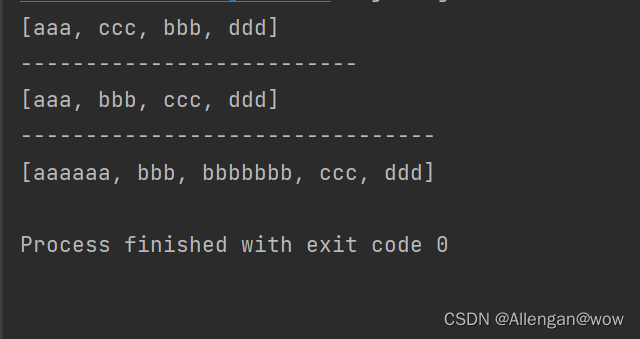
- HashSet:无序 无索引 无重复;
- LinkedHashSet:有序 无索引 无重复;
- TreeSet :排序(升序)无索引 无重复
HashSet集合底层原理
HashSet集合底层是基于哈希表实现的,哈希表根据JDK版本的不同,也是有点区别的
-
JDK8以前:哈希表 = 数组+链表
-
JDK8以后:哈希表 = 数组+链表+红黑树
哈希值
- 就是一个int类型的数值,Java中每个对象都有一个哈希值。
- Java中的所有对象,都可以调用Obejct类提供的hashCode方法,返回该对象自己的哈希值。
Public int hashCode(){//返回对象的哈希值码
}对象哈希值的特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的。
- 不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞)。
哈希表
JDK8之前,哈希表 = 数组+链表

我们发现往HashSet集合中存储元素时,底层调用了元素的两个方法:一个是hashCode方法获取元素的hashCode值(哈希值);另一个是调用了元素的equals方法,用来比较新添加的元素和集合中已有的元素是否相同。
-
只有新添加元素的hashCode值和集合中以后元素的hashCode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
-
如果hashCode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
JDK8开始,哈希表 = 数组+链表+红黑树
在JDK8开始后,为了提高性能,当链表的长度超过8时,就会把链表转换为红黑树,如下图所示

HashSet去重原理
HashSet存储元素的原理,依赖于两个方法:一个是hashCode方法用来确定在底层数组中存储的位置,另一个是用equals方法判断新添加的元素是否和集合中已有的元素相同。
package com.itcast.prepare;
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
public class Demo02 {
public static void main(String[] args) {
Set<Student> hashSet = new HashSet<>();//创建hashSet对象
//添加学生对象
hashSet.add(new Student("张三",18,180.0));
hashSet.add(new Student("王五",28,190.0));
hashSet.add(new Student("王五",28,190.0));
hashSet.add(new Student("李四",38,180.0));
//增强for遍历
for (Student student : hashSet) {
System.out.println(student);
}
}
}
//编写学生的Javabean
class Student{
private String name;
private int age;
private double height;
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
if (Double.compare(student.height, height) != 0) return false;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
int result;
long temp;
result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
temp = Double.doubleToLongBits(height);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
}
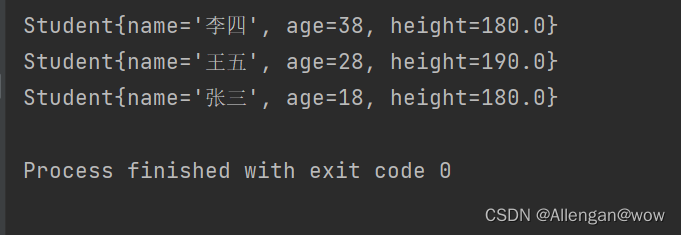
只打印了一个王五,并且是无序的;
当我们使用Set集合时,都是去用它去除里面的重复元素,假如我们在存储的时候对于那些对象一一进行equals()方法进行比较的话,这效率可就太低了(耗时间又耗内存),而使用hash算法的HashCode()方法,则提高了去重的效率,也使equals()方法的执行次数大大降低!
1.当我们的HashSet调用add()方法去存储对象的时候,是先调用对象的HashCode()得到一个哈希值,然后在集找是否有哈希值相同的对象。
(1)、如果没有哈希值相同的对象就直接加入到集合当中不用再经过equals()方法进行比对
(2)、如果哈希值相同的对象的话,就进一步用equals()方法比对去重。
2. 将我们自定义的对象存入set集合当中时:
(1)、类中必须重写equals()和HashSet()这两个方法
(2)、HashCode():属性相同的对象返回值必须是相同的,属性不相同的对象返回值一定不同
(3)、equals():属性相同就返回true,属性不同就返回false;(此方法是判断是否为同一个对象终极审判)
LinkedHashSet底层原理
HashSet的子类LinkedHashSet类。LinkedHashSet它底层采用的是也是哈希表结构,只不过额外新增了一个双向链表来维护元素的存取顺序。如下下图所示:
- 依然是基于哈希表(数组、链表、红黑树)实现的;
- 每个元素额外多一个双链表的机制记录前后元素位置;
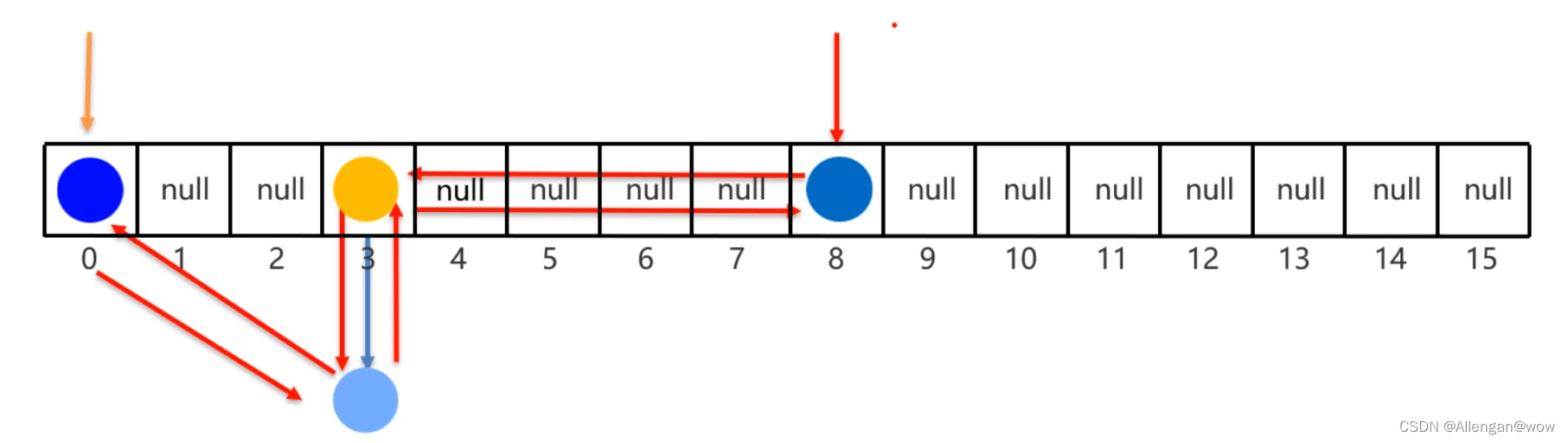
每次添加元素,就和上一个元素用双向链表连接一下。第一个添加的元素是双向链表的头节点,最后一个添加的元素是双向链表的尾节点。
import java.util.LinkedHashSet;
import java.util.Objects;
import java.util.Set;
public class Dome03 {
public static void main(String[] args) {
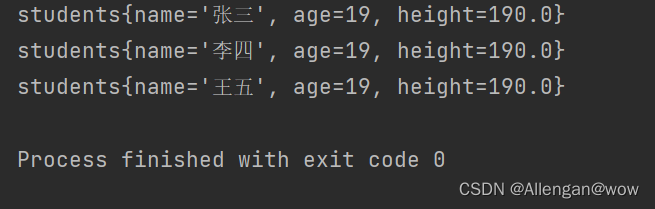
Set<Students> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add(new Students("张三",19,190.0));
linkedHashSet.add(new Students("张三",19,190.0));
linkedHashSet.add(new Students("李四",19,190.0));
linkedHashSet.add(new Students("王五",19,190.0));
linkedHashSet.forEach(System.out::println);
}
}
//编写学生的Javabean
class Students{
private String name;
private int age;
private double height;
public Students() {
}
public Students(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "students{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Students students = (Students) o;
if (age != students.age) return false;
if (Double.compare(students.height, height) != 0) return false;
return Objects.equals(name, students.name);
}
@Override
public int hashCode() {
int result;
long temp;
result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
temp = Double.doubleToLongBits(height);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
}
TreeSet集合
TreeSet集合的特点是可以对元素进行排序,但是必须指定元素的排序规则。
如果往集合中存储String类型的元素,或者Integer类型的元素,它们本身就具备排序规则,所以直接就可以排序。
import java.util.Set;
import java.util.TreeSet;
public class Demo04 {
public static void main(String[] args) {
Set<String> treeSet = new TreeSet<>();
treeSet.add("aaa");
treeSet.add("aaa");
treeSet.add("aaa");
treeSet.add("bbb");
treeSet.add("bbbbbbbbbbb");
treeSet.add("ccc");
treeSet.add("ddd");
System.out.println(treeSet);
Set<Integer> treeSet1 = new TreeSet<>();
treeSet1.add(1);
treeSet1.add(8);
treeSet1.add(9);
treeSet1.add(2);
treeSet1.add(3);
treeSet1.add(4);
treeSet1.add(6);
treeSet1.add(5);
System.out.println(treeSet1);
}
}如果往TreeSet集合中存储自定义类型的元素,比如说Student类型,则需要我们自己指定排序规则,否则会出现异常。
public class Demo05 {
public static void main(String[] args) {
Set<Student> ts = new TreeSet<>();
ts.add(new Student("张三",19,180.0));
ts.add(new Student("李四",28,198.0));
ts.add(new Student("王五",29,164.0));
System.out.println(ts);
}
}此时运行代码,会直接报错。原因是TreeSet不知道按照什么条件对Student对象来排序。
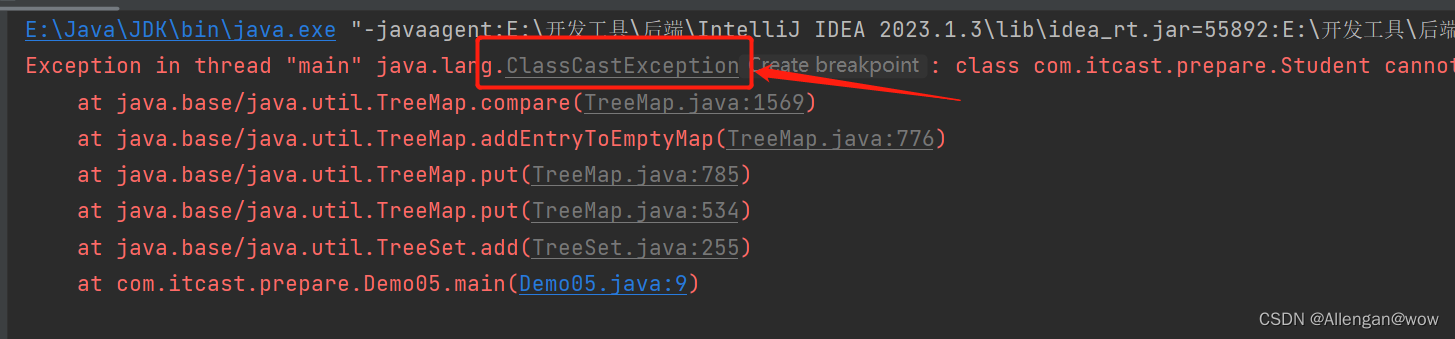
reeSet集合按照指定的规则排序,有两种办法:
- 第一种:让元素的类实现Comparable接口,重写compareTo方法
//编写学生的Javabean
class Student implements Comparable<Student>{//实现compareable的接口并设置泛型
private String name;
private int age;
private double height;
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
if (Double.compare(student.height, height) != 0) return false;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
int result;
long temp;
result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
temp = Double.doubleToLongBits(height);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
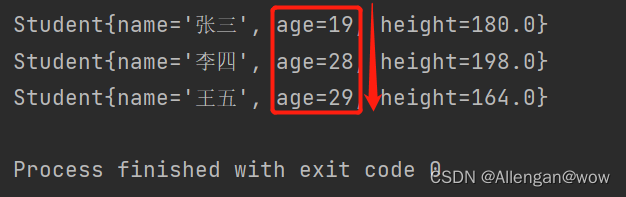
//重写compareTo方法
@Override
public int compareTo(Student s) {
return this.age - s.age;//升序
// return s.age - this.age;//降序
}
}
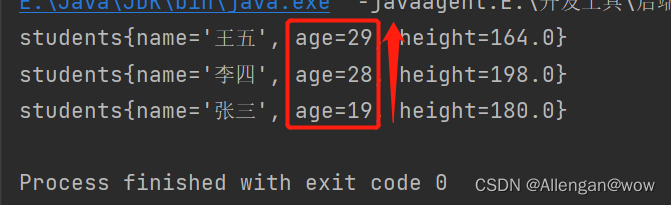
- 第二种:在创建TreeSet集合时,通过构造方法传递Compartor比较器对象
注意:如果类本身有实现Comparable接口,TreeSet集合同时也自带比较器,默认使用集合自带的比较器排序。
public class Demo06 {
public static void main(String[] args) {
Set<Students> ts = new TreeSet<>(new Comparator<Students>() {
@Override
public int compare(Students s1, Students s2) {
return s2.getAge() - s1.getAge();
}
});
ts.add(new Students("张三", 19, 180.0));
ts.add(new Students("李四", 28, 198.0));
ts.add(new Students("王五", 29, 164.0));
//System.out.println(ts);
for (Students student : ts) {
System.out.println(student);
}
}
}
TreeSet集合的特点是怎么样的?
可排序、不重复、无索引 底层基于红黑树实现排序,增删改查性能较好
TreeSet集合对自定义类型的对象排序,有几种方式指定比较规则?
2种。 类实现Comparable接口,重写比较规则。 集合自定义Comparator比较器对象,重写比较规则。
并发修改异常
public class Demo07 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
Iterator<String> it = list.iterator();
//需求:找到集合中带‘李’字的元素,并删除;
while (it.hasNext()){
String st = it.next();
if (list.contains("李")){
list.remove(st);
}
}
System.out.println(list);
}
}

为什么会出现这个异常呢?那是因为迭代器遍历机制,规定迭代器遍历集合的同时,不允许集合自己去增删元素,否则就会出现这个异常。
怎么解决这个问题呢?不使用集合的删除方法,而是使用迭代器的删除方法,代码如下:
public class Demo07 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
Iterator<String> it = list.iterator();
//需求:找到集合中带‘李’字的元素,并删除;
while (it.hasNext()){
String st = it.next();
if (st.contains("李")){//字符串的contains方法
//list.remove(st);//集合的方法;
it.remove();//迭代器的方法;
}
}
System.out.println(list);
}
}可变参数
-
可变参数是一种特殊的形式参数,定义在方法、构造器的形参列表处,它可以让方法接收多个同类型的实际参数。
-
可变参数在方法内部,本质上是一个数组
import java.util.Arrays;
public class Demo08 {
public static void main(String[] args) {
//空参
test();
//带参
test(1,2,3,4,4,5);
//传递一个数组
int[] arr = {1,2,3,3,4,4,5,5};
test(arr);
}
public static void test(int...nums){
//可变参数本质上是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("---------------------");
}
}
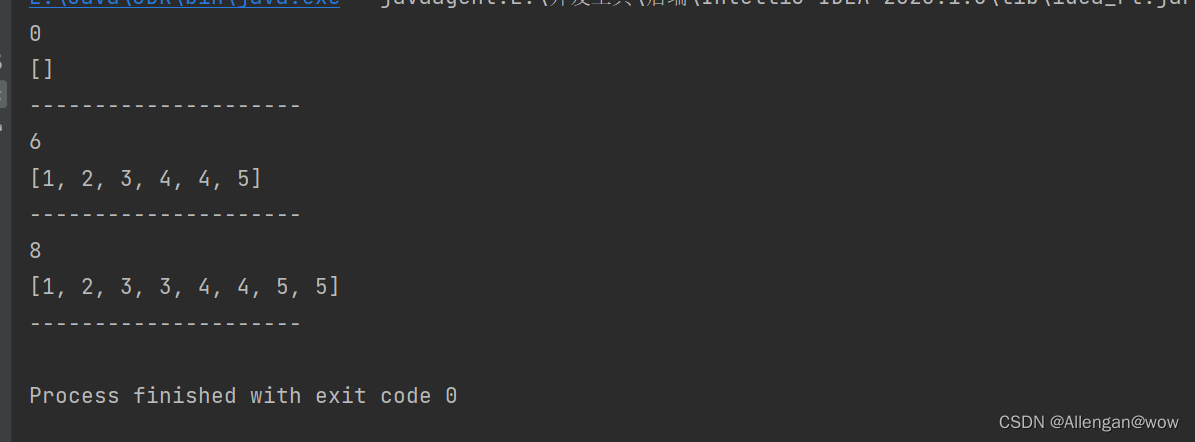
最后还有一些错误写法,需要让大家写代码时注意一下,不要这么写哦!!!
一个形参列表中,只能有一个可变参数;否则会报错
一个形参列表中如果多个参数,可变参数需要写在最后;否则会报错
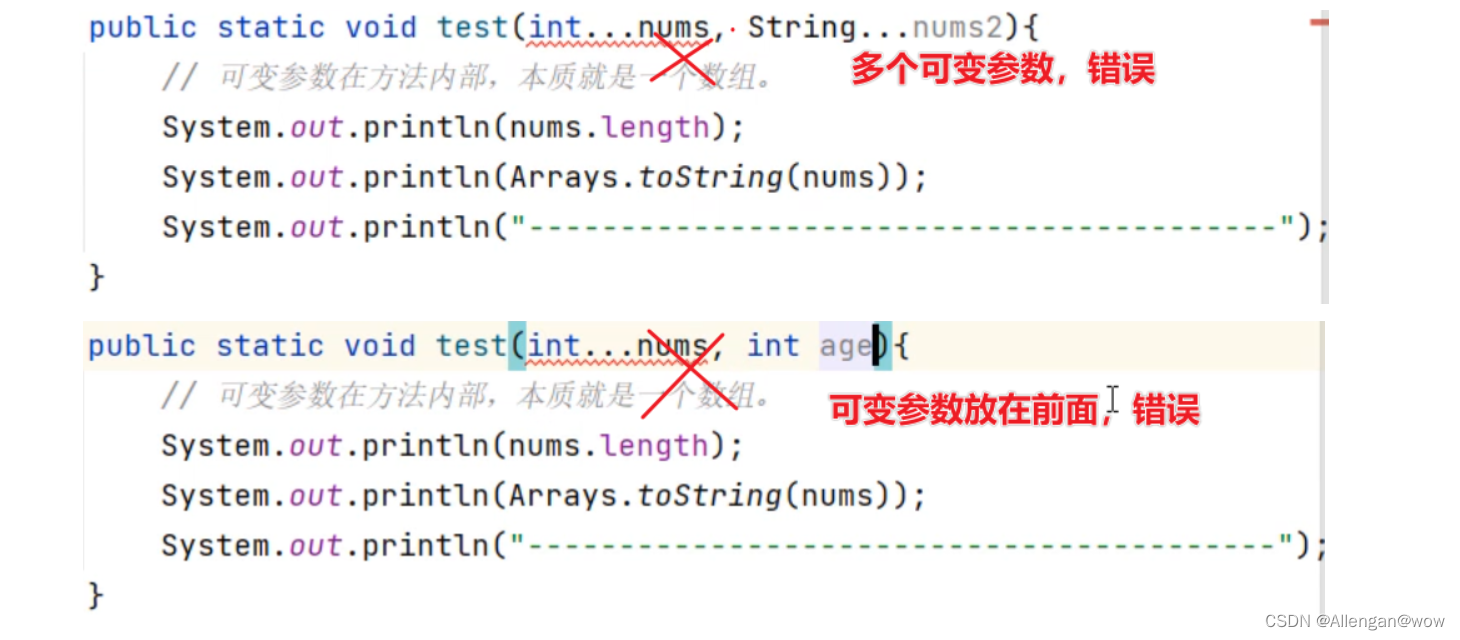
Collections工具类
注意Collections并不是集合,它比Collection多了一个s,一般后缀为s的类很多都是工具类。这里的Collections是用来操作Collection的工具类。它提供了一些好用的静态方法,如下

public class Demo09 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
//批量添加
Collections.addAll(list,"李四","王五","张三三");
System.out.println(list);
System.out.println("----------------------------------");
//打乱集合中元素的顺序
Collections.shuffle(list);
System.out.println(list);
System.out.println("----------------------------------");
//对集合中的元素进行升序排列
Collections.sort(list);
System.out.println(list);
System.out.println("----------------------------------");
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
return s1.length() - s2.length();//升序
}
});
System.out.println(list);
System.out.println("----------------------------------");
}
}
当集合中元素时对象时,我们需要自定义排序规则;
- 让引用类实现Comparetor接口并指定泛型,并重新compareTo接口,在重写方法中制定排序规则,再调用Collections的sort方法;
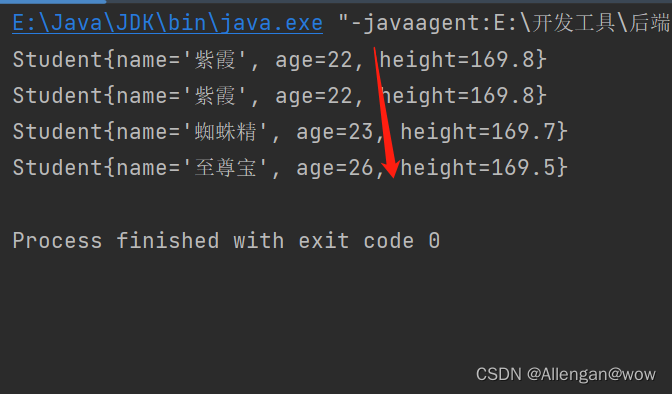
public class Demo10 {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
list.add(new Student("蜘蛛精",23,169.7));
list.add(new Student("紫霞",22,169.8));
list.add(new Student("紫霞",22,169.8));
list.add(new Student("至尊宝",26,169.5));
Collections.sort(list);//调用Collections的sort方法,直接排序;
for (Student student : list) {
System.out.println(student);
}
}
}
//编写学生的Javabean
class Student implements Comparable<Student>{//实现compareable的接口并设置泛型
private String name;
private int age;
private double height;
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
if (Double.compare(student.height, height) != 0) return false;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
int result;
long temp;
result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
temp = Double.doubleToLongBits(height);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
//重写compareTo方法
@Override
public int compareTo(Student s) {
return this.age - s.age;//升序
// return s.age - this.age;//降序
}
}
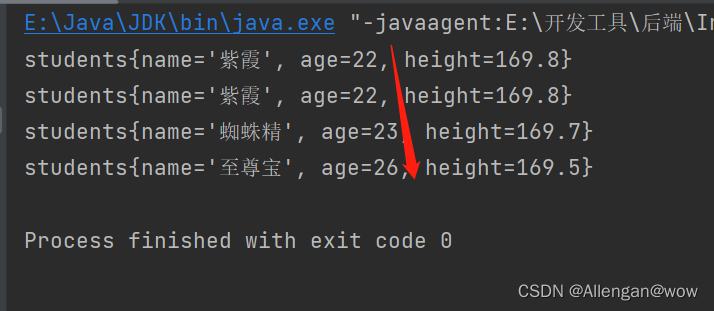
- 直接调用Collections的sort方法并在方法的第二个参数传入比较器;
package com.itcast.prepare;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Demo10 {
public static void main(String[] args) {
List<Students> list = new ArrayList<>();
list.add(new Students("蜘蛛精",23,169.7));
list.add(new Students("紫霞",22,169.8));
list.add(new Students("紫霞",22,169.8));
list.add(new Students("至尊宝",26,169.5));
Collections.sort(list, new Comparator<Students>() {
@Override
public int compare(Students s1, Students s2) {
return s1.getAge() -s2.getAge();//升序
}
});//调用Collections的sort方法,直接排序;
for (Students students : list) {
System.out.println(students);
}
}
}




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











